SAP-C01 : AWS Certified Solutions Architect – Professional : Part 01
SAP-C01 : AWS Certified Solutions Architect – Professional : Part 01
-
Your company policies require encryption of sensitive data at rest. You are considering the possible options for protecting data while storing it at rest on an EBS data volume, attached to an EC2 instance.
Which of these options would allow you to encrypt your data at rest? (Choose three.)
- Implement third party volume encryption tools
- Implement SSL/TLS for all services running on the server
- Encrypt data inside your applications before storing it on EBS
- Encrypt data using native data encryption drivers at the file system level
- Do nothing as EBS volumes are encrypted by default
-
A customer is deploying an SSL enabled web application to AWS and would like to implement a separation of roles between the EC2 service administrators that are entitled to login to instances as well as making API calls and the security officers who will maintain and have exclusive access to the application’s X.509 certificate that contains the private key.
- Upload the certificate on an S3 bucket owned by the security officers and accessible only by EC2 Role of the web servers.
- Configure the web servers to retrieve the certificate upon boot from an CloudHSM is managed by the security officers.
- Configure system permissions on the web servers to restrict access to the certificate only to the authority security officers
- Configure IAM policies authorizing access to the certificate store only to the security officers and terminate SSL on an ELB.
Explanation:
You’ll terminate the SSL at ELB. and the web request will get unencrypted to the EC2 instance, even if the certs are stored in S3, it has to be configured on the web servers or load balancers somehow, which becomes difficult if the keys are stored in S3. However, keeping the keys in the cert store and using IAM to restrict access gives a clear separation of concern between security officers and developers. Developer’s personnel can still configure SSL on ELB without actually handling the keys. -
You have recently joined a startup company building sensors to measure street noise and air quality in urban areas. The company has been running a pilot deployment of around 100 sensors for 3 months each sensor uploads 1KB of sensor data every minute to a backend hosted on AWS.
During the pilot, you measured a peak or 10 IOPS on the database, and you stored an average of 3GB of sensor data per month in the database.
The current deployment consists of a load-balanced auto scaled Ingestion layer using EC2 instances and a PostgreSQL RDS database with 500GB standard storage.
The pilot is considered a success and your CEO has managed to get the attention or some potential investors. The business plan requires a deployment of at least 100K sensors which needs to be supported by the backend. You also need to store sensor data for at least two years to be able to compare year over year Improvements.
To secure funding, you have to make sure that the platform meets these requirements and leaves room for further scaling.Which setup win meet the requirements?
- Add an SQS queue to the ingestion layer to buffer writes to the RDS instance
- Ingest data into a DynamoDB table and move old data to a Redshift cluster
- Replace the RDS instance with a 6 node Redshift cluster with 96TB of storage
- Keep the current architecture but upgrade RDS storage to 3TB and 10K provisioned IOPS
Explanation:
The POC solution is being scaled up by 1000, which means it will require 72TB of Storage to retain 24 months’ worth of data. This rules out RDS as a possible DB solution which leaves you with Redshift.
I believe DynamoDB is a more cost effective and scales better for ingest rather than using EC2 in an auto scaling group.
Also, this example solution from AWS is somewhat similar for reference. -
A web company is looking to implement an intrusion detection and prevention system into their deployed VPC. This platform should have the ability to scale to thousands of instances running inside of the VPC.
How should they architect their solution to achieve these goals?
- Configure an instance with monitoring software and the elastic network interface (ENI) set to promiscuous mode packet sniffing to see an traffic across the VPC.
- Create a second VPC and route all traffic from the primary application VPC through the second VPC where the scalable virtualized IDS/IPS platform resides.
- Configure servers running in the VPC using the host-based ‘route’ commands to send all traffic through the platform to a scalable virtualized IDS/IPS.
- Configure each host with an agent that collects all network traffic and sends that traffic to the IDS/IPS platform for inspection.
-
A company is storing data on Amazon Simple Storage Service (S3). The company’s security policy mandates that data is encrypted at rest.
Which of the following methods can achieve this? (Choose three.)
- Use Amazon S3 server-side encryption with AWS Key Management Service managed keys.
- Use Amazon S3 server-side encryption with customer-provided keys.
- Use Amazon S3 server-side encryption with EC2 key pair.
- Use Amazon S3 bucket policies to restrict access to the data at rest.
- Encrypt the data on the client-side before ingesting to Amazon S3 using their own master key.
- Use SSL to encrypt the data while in transit to Amazon S3.
-
Your firm has uploaded a large amount of aerial image data to S3. In the past, in your on-premises environment, you used a dedicated group of servers to oaten process this data and used Rabbit MQ – An open source messaging system to get job information to the servers. Once processed the data would go to tape and be shipped offsite. Your manager told you to stay with the current design, and leverage AWS archival storage and messaging services to minimize cost.
Which is correct?
- Use SQS for passing job messages use Cloud Watch alarms to terminate EC2 worker instances when they become idle. Once data is processed, change the storage class of the S3 objects to Reduced Redundancy Storage.
- Setup Auto-Scaled workers triggered by queue depth that use spot instances to process messages in SOS Once data is processed, change the storage class of the S3 objects to Reduced Redundancy Storage.
- Setup Auto-Scaled workers triggered by queue depth that use spot instances to process messages in SQS Once data is processed, change the storage class of the S3 objects to Glacier.
- Use SNS to pass job messages use Cloud Watch alarms to terminate spot worker instances when they become idle. Once data is processed, change the storage class of the S3 object to Glacier.
-
You’ve been hired to enhance the overall security posture for a very large e-commerce site. They have a well architected multi-tier application running in a VPC that uses ELBs in front of both the web and the app tier with static assets served directly from S3. They are using a combination of RDS and DynamoDB for their dynamic data and then archiving nightly into S3 for further processing with EMR. They are concerned because they found questionable log entries and suspect someone is attempting to gain unauthorized access.
Which approach provides a cost effective scalable mitigation to this kind of attack?
- Recommend that they lease space at a DirectConnect partner location and establish a 1G DirectConnect connection to their VPC they would then establish Internet connectivity into their space, filter the traffic in hardware Web Application Firewall (WAF). And then pass the traffic through the DirectConnect connection into their application running in their VPC.
- Add previously identified hostile source IPs as an explicit INBOUND DENY NACL to the web tier subnet.
- Add a WAF tier by creating a new ELB and an AutoScaling group of EC2 Instances running a host-based WAF. They would redirect Route 53 to resolve to the new WAF tier ELB. The WAF tier would their pass the traffic to the current web tier The web tier Security Groups would be updated to only allow traffic from the WAF tier Security Group
- Remove all but TLS 1.2 from the web tier ELB and enable Advanced Protocol Filtering. This will enable the ELB itself to perform WAF functionality.
-
Your company is in the process of developing a next generation pet collar that collects biometric information to assist families with promoting healthy lifestyles for their pets. Each collar will push 30kb of biometric data in JSON format every 2 seconds to a collection platform that will process and analyze the data providing health trending information back to the pet owners and veterinarians via a web portal. Management has tasked you to architect the collection platform ensuring the following requirements are met.
– Provide the ability for real-time analytics of the inbound biometric data
– Ensure processing of the biometric data is highly durable. Elastic and parallel
– The results of the analytic processing should be persisted for data miningWhich architecture outlined below win meet the initial requirements for the collection platform?
- Utilize S3 to collect the inbound sensor data analyze the data from S3 with a daily scheduled Data Pipeline and save the results to a Redshift Cluster.
- Utilize Amazon Kinesis to collect the inbound sensor data, analyze the data with Kinesis clients and save the results to a Redshift cluster using EMR.
- Utilize SQS to collect the inbound sensor data analyze the data from SQS with Amazon Kinesis and save the results to a Microsoft SQL Server RDS instance.
- Utilize EMR to collect the inbound sensor data, analyze the data from EUR with Amazon Kinesis and save me results to DynamoDB.
-
You are designing Internet connectivity for your VPC. The Web servers must be available on the Internet. The application must have a highly available architecture.
Which alternatives should you consider? (Choose two.)
- Configure a NAT instance in your VPC. Create a default route via the NAT instance and associate it with all subnets. Configure a DNS A record that points to the NAT instance public IP address.
- Configure a CloudFront distribution and configure the origin to point to the private IP addresses of your Web servers. Configure a Route53 CNAME record to your CloudFront distribution.
- Place all your web servers behind ELB. Configure a Route53 CNMIE to point to the ELB DNS name.
- Assign EIPs to all web servers. Configure a Route53 record set with all EIPs, with health checks and DNS failover.
- Configure ELB with an EIP. Place all your Web servers behind ELB. Configure a Route53 A record that points to the EIP.
-
Your team has a tomcat-based Java application you need to deploy into development, test and production environments. After some research, you opt to use Elastic Beanstalk due to its tight integration with your developer tools and RDS due to its ease of management. Your QA team lead points out that you need to roll a sanitized set of production data into your environment on a nightly basis. Similarly, other software teams in your org want access to that same restored data via their EC2 instances in your VPC.
The optimal setup for persistence and security that meets the above requirements would be the following.
- Create your RDS instance as part of your Elastic Beanstalk definition and alter its security group to allow access to it from hosts in your application subnets.
- Create your RDS instance separately and add its IP address to your application’s DB connection strings in your code Alter its security group to allow access to it from hosts within your VPC’s IP address block.
- Create your RDS instance separately and pass its DNS name to your app’s DB connection string as an environment variable. Create a security group for client machines and add it as a valid source for DB traffic to the security group of the RDS instance itself.
- Create your RDS instance separately and pass its DNS name to your’s DB connection string as an environment variable Alter its security group to allow access to It from hosts in your application subnets.
Explanation:
Elastic Beanstalk provides support for running Amazon RDS instances in your Elastic Beanstalk environment. This works great for development and testing environments, but is not ideal for a production environment because it ties the lifecycle of the database instance to the lifecycle of your application’s environment. -
Your company has an on-premises multi-tier PHP web application, which recently experienced downtime due to a large burst in web traffic due to a company announcement Over the coming days, you are expecting similar announcements to drive similar unpredictable bursts, and are looking to find ways to quickly improve your infrastructures ability to handle unexpected increases in traffic.
The application currently consists of 2 tiers a web tier which consists of a load balancer and several Linux Apache web servers as well as a database tier which hosts a Linux server hosting a MySQL database.Which scenario below will provide full site functionality, while helping to improve the ability of your application in the short timeframe required?
- Failover environment: Create an S3 bucket and configure it for website hosting. Migrate your DNS to Route53 using zone file import, and leverage Route53 DNS failover to failover to the S3 hosted website.
- Hybrid environment: Create an AMI, which can be used to launch web servers in EC2. Create an Auto Scaling group, which uses the AMI to scale the web tier based on incoming traffic. Leverage Elastic Load Balancing to balance traffic between on-premises web servers and those hosted in AWS.
- Offload traffic from on-premises environment: Setup a CIoudFront distribution, and configure CloudFront to cache objects from a custom origin. Choose to customize your object cache behavior, and select a TTL that objects should exist in cache.
- Migrate to AWS: Use VM Import/Export to quickly convert an on-premises web server to an AMI. Create an Auto Scaling group, which uses the imported AMI to scale the web tier based on incoming traffic. Create an RDS read replica and setup replication between the RDS instance and on-premises MySQL server to migrate the database.
Explanation:
You can have CloudFront sit in front of your on-prem web environment, via a custom origin (the origin doesn’t have to be in AWS). This would protect against unexpected bursts in traffic by letting CloudFront handle the traffic that it can out of cache, thus hopefully removing some of the load from your on-prem web servers. -
You are implementing AWS Direct Connect. You intend to use AWS public service end points such as Amazon S3, across the AWS Direct Connect link. You want other Internet traffic to use your existing link to an Internet Service Provider.
What is the correct way to configure AWS Direct connect for access to services such as Amazon S3?
- Configure a public Interface on your AWS Direct Connect link. Configure a static route via your AWS Direct Connect link that points to Amazon S3 Advertise a default route to AWS using BGP.
- Create a private interface on your AWS Direct Connect link. Configure a static route via your AWS Direct connect link that points to Amazon S3 Configure specific routes to your network in your VPC.
- Create a public interface on your AWS Direct Connect link. Redistribute BGP routes into your existing routing infrastructure; advertise specific routes for your network to AWS.
- Create a private interface on your AWS Direct connect link. Redistribute BGP routes into your existing routing infrastructure and advertise a default route to AWS.
-
Your application is using an ELB in front of an Auto Scaling group of web/application servers deployed across two AZs and a Multi-AZ RDS Instance for data persistence.
The database CPU is often above 80% usage and 90% of I/O operations on the database are reads. To improve performance you recently added a single-node Memcached ElastiCache Cluster to cache frequent DB query results. In the next weeks the overall workload is expected to grow by 30%.Do you need to change anything in the architecture to maintain the high availability or the application with the anticipated additional load? Why?
- Yes, you should deploy two Memcached ElastiCache Clusters in different AZs because the RDS instance will not be able to handle the load if the cache node fails.
- No, if the cache node fails you can always get the same data from the DB without having any availability impact.
- No, if the cache node fails the automated ElastiCache node recovery feature will prevent any availability impact.
- Yes, you should deploy the Memcached ElastiCache Cluster with two nodes in the same AZ as the RDS DB master instance to handle the load if one cache node fails.
Explanation:
ElastiCache for Memcached
The primary goal of caching is typically to offload reads from your database or other primary data source. In most apps, you have hot spots of data that are regularly queried, but only updated periodically. Think of the front page of a blog or news site, or the top 100 leaderboard in an online game. In this type of case, your app can receive dozens, hundreds, or even thousands of requests for the same data before it’s updated again. Having your caching layer handle these queries has several advantages. First, it’s considerably cheaper to add an in-memory cache than to scale up to a larger database cluster. Second, an in-memory cache is also easier to scale out, because it’s easier to distribute an in-memory cache horizontally than a relational database.
Last, a caching layer provides a request buffer in the event of a sudden spike in usage. If your app or game ends up on the front page of Reddit or the App Store, it’s not unheard of to see a spike that is 10 to 100 times your normal application load. Even if you autoscale your application instances, a 10x request spike will likely make your database very unhappy.
Let’s focus on ElastiCache for Memcached first, because it is the best fit for a cachingfocused solution. We’ll revisit Redis later in the paper, and weigh its advantages and disadvantages.
Architecture with ElastiCache for Memcached
When you deploy an ElastiCache Memcached cluster, it sits in your application as a separate tier alongside your database. As mentioned previously, Amazon ElastiCache does not directly communicate with your database tier, or indeed have any particular knowledge of your database. A simplified deployment for a web application looks something like this:
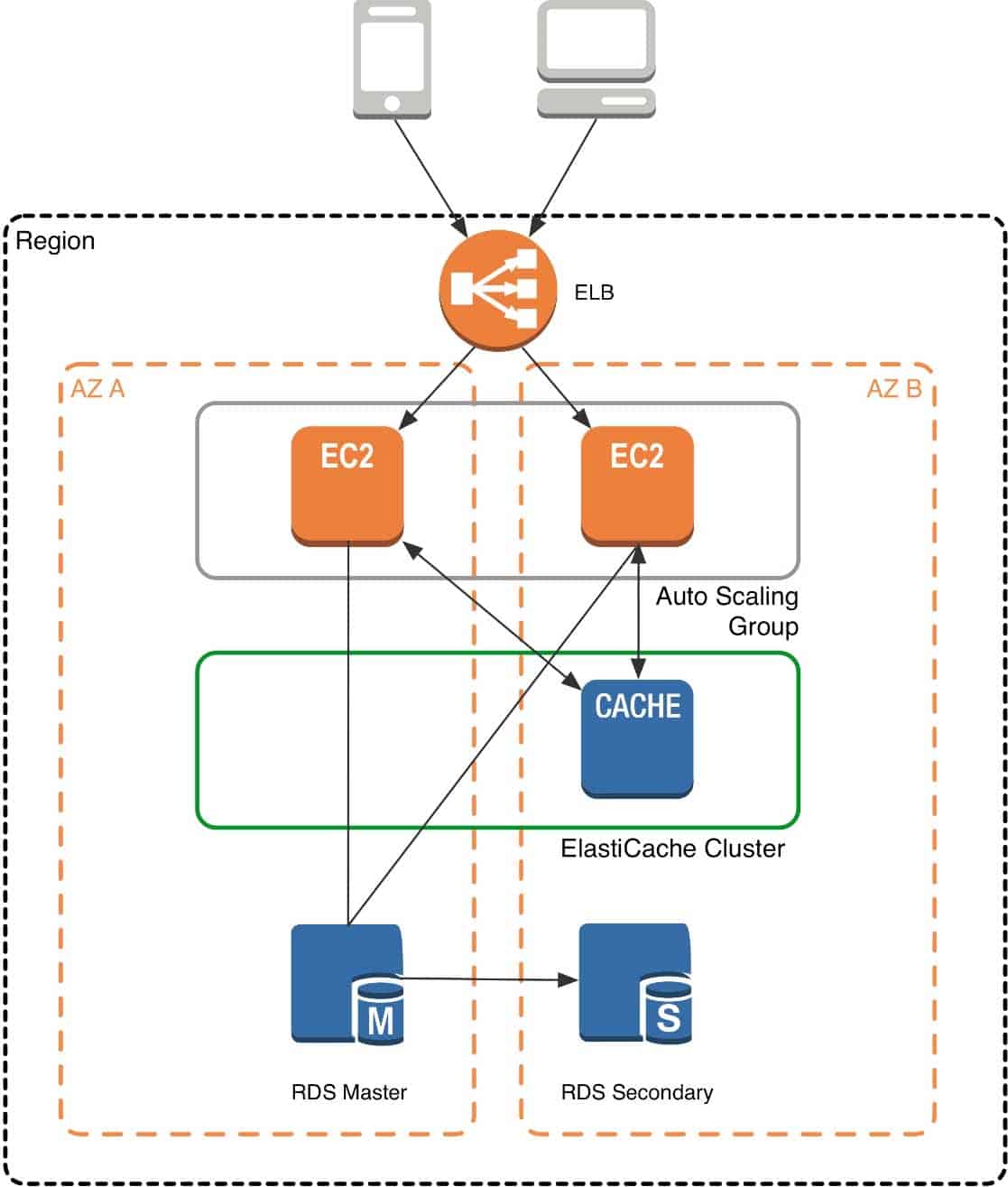
SAP-C01 AWS Certified Solutions Architect – Professional Part 01 Q13 001 In this architecture diagram, the Amazon EC2 application instances are in an Auto Scaling group, located behind a load balancer using Elastic Load Balancing, which distributes requests among the instances. As requests come into a given EC2 instance, that EC2 instance is responsible for communicating with ElastiCache and the database tier. For development purposes, you can begin with a single ElastiCache node to test your application, and then scale to additional cluster nodes by modifying the ElastiCache cluster. As you add additional cache nodes, the EC2 application instances are able to distribute cache keys across multiple ElastiCache nodes. The most common practice is to use client-side sharding to distribute keys across cache nodes, which we will discuss later in this paper.
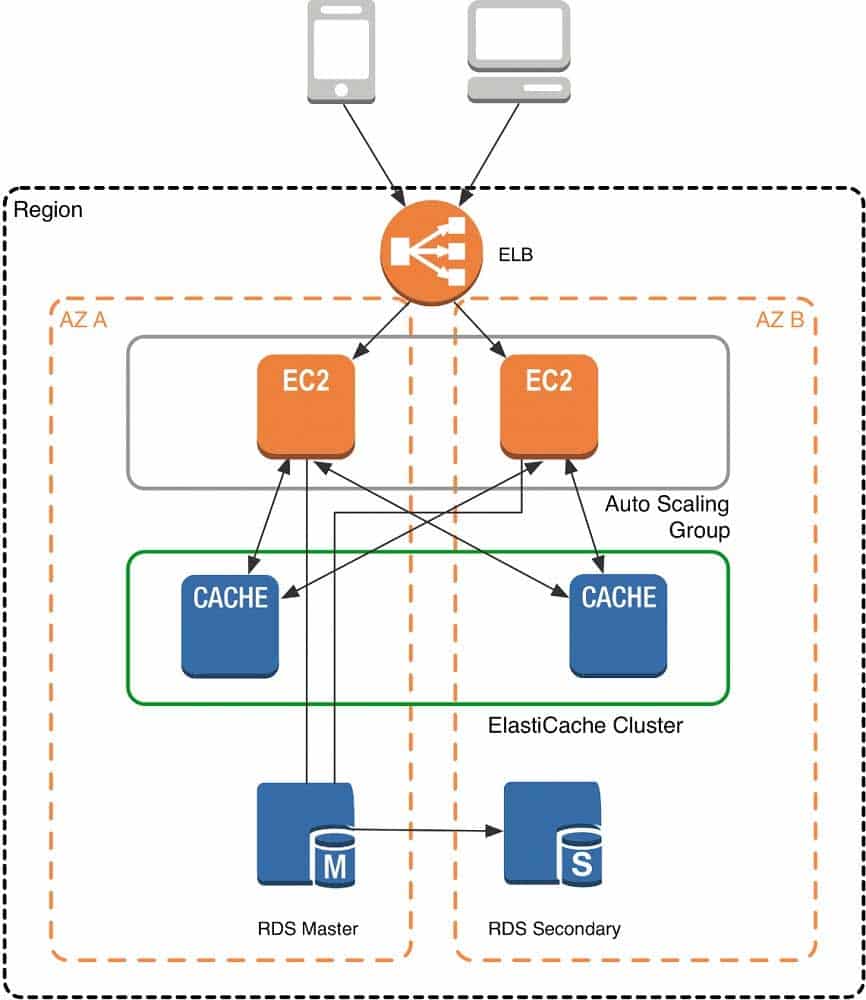
SAP-C01 AWS Certified Solutions Architect – Professional Part 01 Q13 002 When you launch an ElastiCache cluster, you can choose the Availability Zone(s) that the cluster lives in. For best performance, you should configure your cluster to use the same Availability Zones as your application servers. To launch an ElastiCache cluster in a specific Availability Zone, make sure to specify the Preferred Zone(s) option during cache cluster creation. The Availability Zones that you specify will be where ElastiCache will launch your cache nodes. We recommend that you select Spread Nodes Across Zones, which tells ElastiCache to distribute cache nodes across these zones as evenly as possible. This distribution will mitigate the impact of an Availability Zone disruption on your ElastiCache nodes. The trade-off is that some of the requests from your application to ElastiCache will go to a node in a different Availability Zone, meaning latency will be slightly higher. For more details, refer to Creating a Cache Cluster in the Amazon ElastiCache User Guide.
As mentioned at the outset, ElastiCache can be coupled with a wide variety of databases. Here is an example architecture that uses Amazon DynamoDB instead of Amazon RDS and MySQL: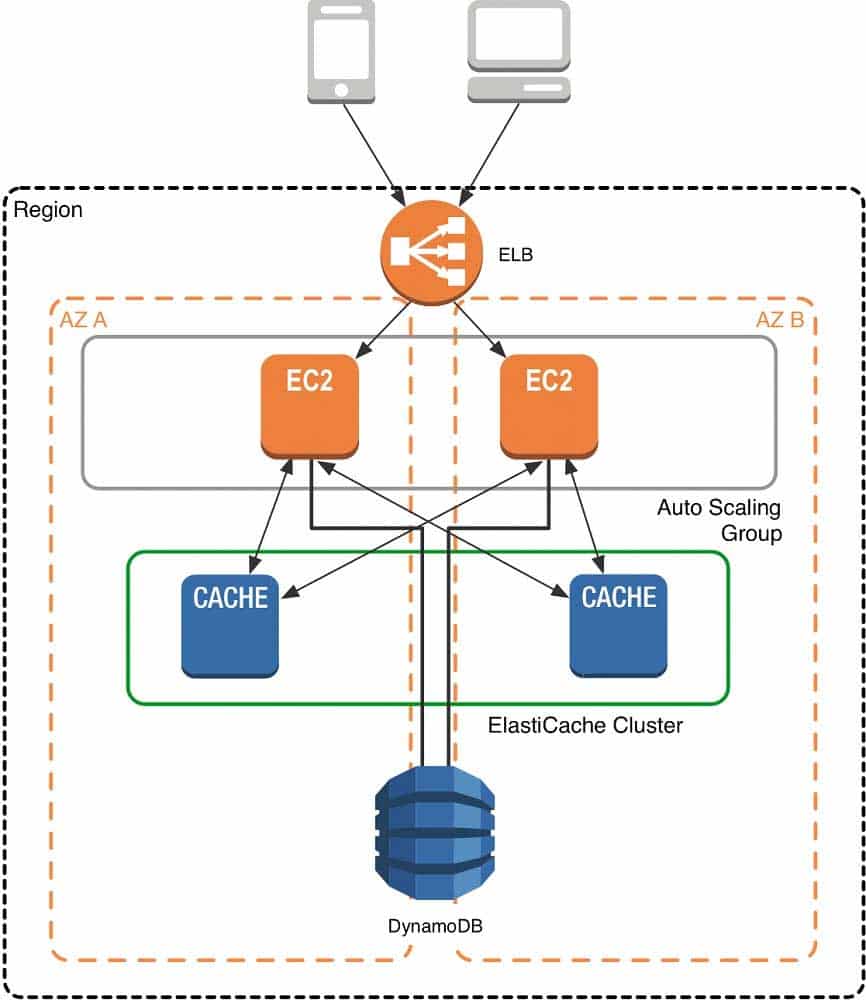
SAP-C01 AWS Certified Solutions Architect – Professional Part 01 Q13 003 This combination of DynamoDB and ElastiCache is very popular with mobile and game companies, because DynamoDB allows for higher write throughput at lower cost than traditional relational databases. In addition, DynamoDB uses a key-value access pattern similar to ElastiCache, which also simplifies the programming model. Instead of using relational SQL for the primary database but then key-value patterns for the cache, both the primary database and cache can be programmed similarly. In this architecture pattern, DynamoDB remains the source of truth for data, but application reads are offloaded to ElastiCache for a speed boost.
-
An ERP application is deployed across multiple AZs in a single region. In the event of failure, the Recovery Time Objective (RTO) must be less than 3 hours, and the Recovery Point Objective (RPO) must be 15 minutes. The customer realizes that data corruption occurred roughly 1.5 hours ago.
What DR strategy could be used to achieve this RTO and RPO in the event of this kind of failure?
- Take hourly DB backups to S3, with transaction logs stored in S3 every 5 minutes.
- Use synchronous database master-slave replication between two availability zones.
- Take hourly DB backups to EC2 Instance store volumes with transaction logs stored In S3 every 5 minutes.
- Take 15 minute DB backups stored In Glacier with transaction logs stored in S3 every 5 minutes.
-
You are designing the network infrastructure for an application server in Amazon VPC. Users will access all application instances from the Internet, as well as from an on-premises network. The on-premises network is connected to your VPC over an AWS Direct Connect link.
How would you design routing to meet the above requirements?
- Configure a single routing table with a default route via the Internet gateway. Propagate a default route via BGP on the AWS Direct Connect customer router. Associate the routing table with all VPC subnets.
- Configure a single routing table with a default route via the Internet gateway. Propagate specific routes for the on-premises networks via BGP on the AWS Direct Connect customer router. Associate the routing table with all VPC subnets.
- Configure a single routing table with two default routes: on to the Internet via an Internet gateway, the other to the on-premises network via the VPN gateway. Use this routing table across all subnets in the VPC.
- Configure two routing tables: on that has a default router via the Internet gateway, and other that has a default route via the VPN gateway. Associate both routing tables with each VPC subnet.
-
You control access to S3 buckets and objects with:
- Identity and Access Management (IAM) Policies.
- Access Control Lists (ACLs).
- Bucket Policies.
- All of the above
-
The AWS IT infrastructure that AWS provides, complies with the following IT security standards, including:
- SOC 1/SSAE 16/ISAE 3402 (formerly SAS 70 Type II), SOC 2 and SOC 3
- FISMA, DIACAP, and FedRAMP
- PCI DSS Level 1, ISO 27001, ITAR and FIPS 140-2
- HIPAA, Cloud Security Alliance (CSA) and Motion Picture Association of America (MPAA)
- All of the above
-
Auto Scaling requests are signed with a _________ signature calculated from the request and the user’s private key.
- SSL
- AES-256
- HMAC-SHA1
- X.509
-
The following policy can be attached to an IAM group. It lets an IAM user in that group access a “home directory” in AWS S3 that matches their user name using the console.
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Action”: [“s3:*”],
“Effect”: “Allow”,
“Resource”: [“arn:aws:s3:::bucket-name”],
“Condition”:{“StringLike”:{“s3:prefix”:[“home/${aws:username}/*”]}}
},
{
“Action”:[“s3:*”],
“Effect”:”Allow”,
“Resource”: [“arn:aws:s3:::bucket-name/home/${aws:username}/*”]
}
]
}
- True
- False
-
What does elasticity mean to AWS?
- The ability to scale computing resources up easily, with minimal friction and down with latency.
- The ability to scale computing resources up and down easily, with minimal friction.
- The ability to provision cloud computing resources in expectation of future demand.
- The ability to recover from business continuity events with minimal friction.