DP-203 : Data Engineering on Microsoft Azure : Part 03
DP-203 : Data Engineering on Microsoft Azure : Part 03
-
You have two Azure Data Factory instances named ADFdev and ADFprod. ADFdev connects to an Azure DevOps Git repository.
You publish changes from the main branch of the Git repository to ADFdev.
You need to deploy the artifacts from ADFdev to ADFprod.
What should you do first?
- From ADFdev, modify the Git configuration.
- From ADFdev, create a linked service.
- From Azure DevOps, create a release pipeline.
- From Azure DevOps, update the main branch.
Explanation:
In Azure Data Factory, continuous integration and delivery (CI/CD) means moving Data Factory pipelines from one environment (development, test, production) to another.
Note:
The following is a guide for setting up an Azure Pipelines release that automates the deployment of a data factory to multiple environments.
1. In Azure DevOps, open the project that’s configured with your data factory.
2. On the left side of the page, select Pipelines, and then select Releases.
3. Select New pipeline, or, if you have existing pipelines, select New and then New release pipeline.
4. In the Stage name box, enter the name of your environment.
5. Select Add artifact, and then select the git repository configured with your development data factory. Select the publish branch of the repository for the Default branch. By default, this publish branch is adf_publish.
6. Select the Empty job template. -
You are developing a solution that will stream to Azure Stream Analytics. The solution will have both streaming data and reference data.
Which input type should you use for the reference data?
- Azure Cosmos DB
- Azure Blob storage
- Azure IoT Hub
- Azure Event Hubs
Explanation:Stream Analytics supports Azure Blob storage and Azure SQL Database as the storage layer for Reference Data. -
You are designing an Azure Stream Analytics job to process incoming events from sensors in retail environments.
You need to process the events to produce a running average of shopper counts during the previous 15 minutes, calculated at five-minute intervals.
Which type of window should you use?
- snapshot
- tumbling
- hopping
- sliding
Explanation:Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals. The following diagram illustrates a stream with a series of events and how they are mapped into 10-second tumbling windows.
DP-203 Data Engineering on Microsoft Azure Part 03 Q03 045 -
HOTSPOT
You are designing a monitoring solution for a fleet of 500 vehicles. Each vehicle has a GPS tracking device that sends data to an Azure event hub once per minute.
You have a CSV file in an Azure Data Lake Storage Gen2 container. The file maintains the expected geographical area in which each vehicle should be.
You need to ensure that when a GPS position is outside the expected area, a message is added to another event hub for processing within 30 seconds. The solution must minimize cost.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
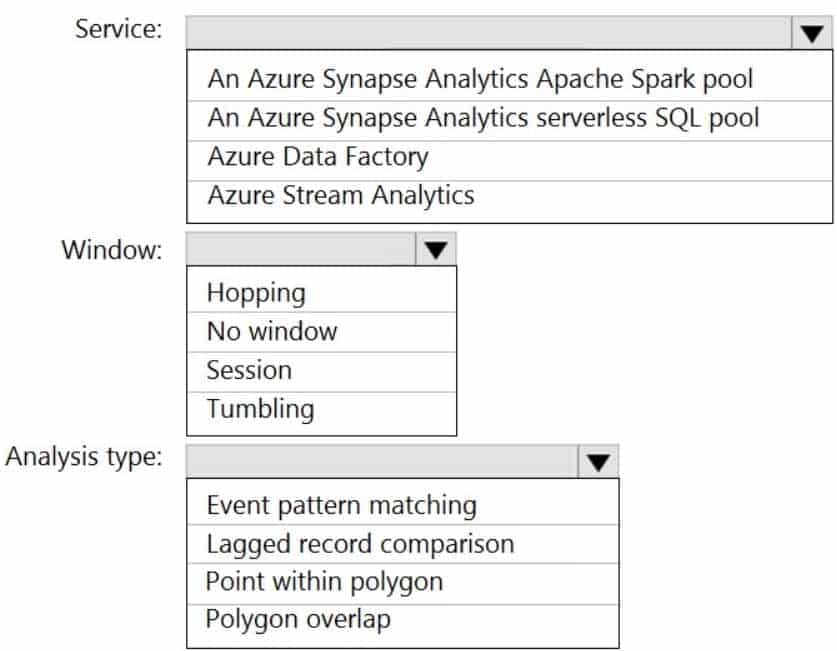
DP-203 Data Engineering on Microsoft Azure Part 03 Q04 046 Question 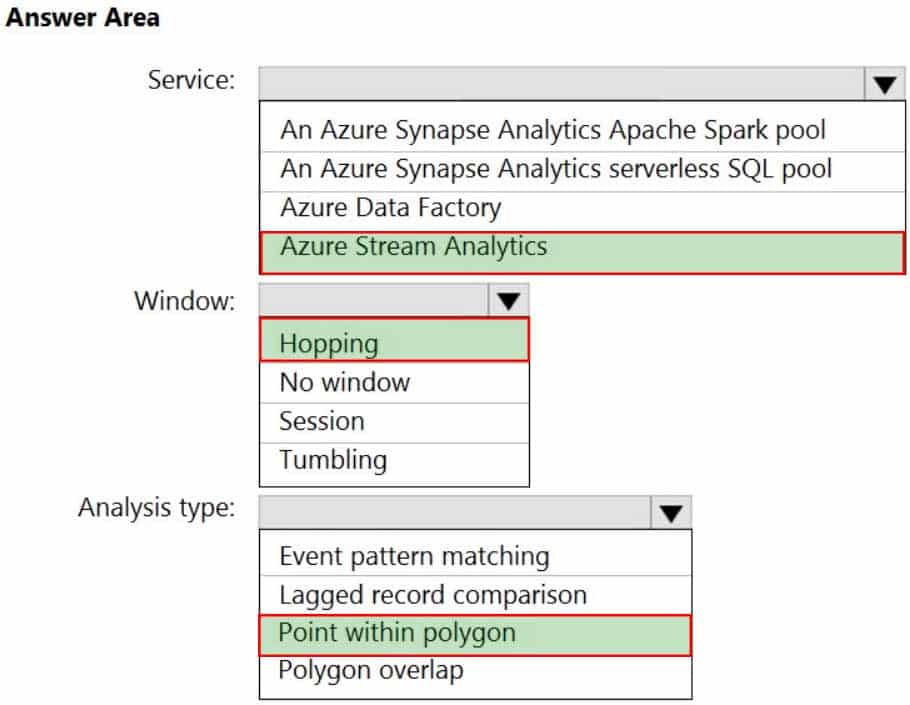
DP-203 Data Engineering on Microsoft Azure Part 03 Q04 046 Answer Explanation:Box 1: Azure Stream Analytics
Box 2: Hopping
Hopping window functions hop forward in time by a fixed period. It may be easy to think of them as Tumbling windows that can overlap and be emitted more often than the window size. Events can belong to more than one Hopping window result set. To make a Hopping window the same as a Tumbling window, specify the hop size to be the same as the window size.Box 3: Point within polygon
-
You are designing an Azure Databricks table. The table will ingest an average of 20 million streaming events per day.
You need to persist the events in the table for use in incremental load pipeline jobs in Azure Databricks. The solution must minimize storage costs and incremental load times.
What should you include in the solution?
- Partition by DateTime fields.
- Sink to Azure Queue storage.
- Include a watermark column.
- Use a JSON format for physical data storage.
Explanation:The Databricks ABS-AQS connector uses Azure Queue Storage (AQS) to provide an optimized file source that lets you find new files written to an Azure Blob storage (ABS) container without repeatedly listing all of the files. This provides two major advantages:
– Lower latency: no need to list nested directory structures on ABS, which is slow and resource intensive.
– Lower costs: no more costly LIST API requests made to ABS -
HOTSPOT
You have a self-hosted integration runtime in Azure Data Factory.
The current status of the integration runtime has the following configurations:
– Status: Running
– Type: Self-Hosted
– Version: 4.4.7292.1
– Running / Registered Node(s): 1/1
– High Availability Enabled: False
– Linked Count: 0
– Queue Length: 0
– Average Queue Duration. 0.00sThe integration runtime has the following node details:
– Name: X-M
– Status: Running
– Version: 4.4.7292.1
– Available Memory: 7697MB
– CPU Utilization: 6%
– Network (In/Out): 1.21KBps/0.83KBps
– Concurrent Jobs (Running/Limit): 2/14
– Role: Dispatcher/Worker
– Credential Status: In SyncUse the drop-down menus to select the answer choice that completes each statement based on the information presented.
NOTE: Each correct selection is worth one point.

DP-203 Data Engineering on Microsoft Azure Part 03 Q06 047 Question 
DP-203 Data Engineering on Microsoft Azure Part 03 Q06 047 Answer Explanation:Box 1: fail until the node comes back online
We see: High Availability Enabled: FalseNote: Higher availability of the self-hosted integration runtime so that it’s no longer the single point of failure in your big data solution or cloud data integration with Data Factory.
Box 2: lowered
We see:
Concurrent Jobs (Running/Limit): 2/14
CPU Utilization: 6%Note: When the processor and available RAM aren’t well utilized, but the execution of concurrent jobs reaches a node’s limits, scale up by increasing the number of concurrent jobs that a node can run
-
You have an Azure Databricks workspace named workspace1 in the Standard pricing tier.
You need to configure workspace1 to support autoscaling all-purpose clusters. The solution must meet the following requirements:
– Automatically scale down workers when the cluster is underutilized for three minutes.
– Minimize the time it takes to scale to the maximum number of workers.
– Minimize costs.What should you do first?
- Enable container services for workspace1.
- Upgrade workspace1 to the Premium pricing tier.
- Set Cluster Mode to High Concurrency.
- Create a cluster policy in workspace1.
Explanation:For clusters running Databricks Runtime 6.4 and above, optimized autoscaling is used by all-purpose clusters in the Premium plan
Optimized autoscaling:
Scales up from min to max in 2 steps.
Can scale down even if the cluster is not idle by looking at shuffle file state.
Scales down based on a percentage of current nodes.
On job clusters, scales down if the cluster is underutilized over the last 40 seconds.
On all-purpose clusters, scales down if the cluster is underutilized over the last 150 seconds.
The spark.databricks.aggressiveWindowDownS Spark configuration property specifies in seconds how often a cluster makes down-scaling decisions. Increasing the value causes a cluster to scale down more slowly. The maximum value is 600.Note: Standard autoscaling
Starts with adding 8 nodes. Thereafter, scales up exponentially, but can take many steps to reach the max. You can customize the first step by setting the spark.databricks.autoscaling.standardFirstStepUp Spark configuration property.
Scales down only when the cluster is completely idle and it has been underutilized for the last 10 minutes.
Scales down exponentially, starting with 1 node. -
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure Stream Analytics solution that will analyze Twitter data.
You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only once.
Solution: You use a tumbling window, and you set the window size to 10 seconds.
Does this meet the goal?
- Yes
- No
Explanation:Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals. The following diagram illustrates a stream with a series of events and how they are mapped into 10-second tumbling windows.
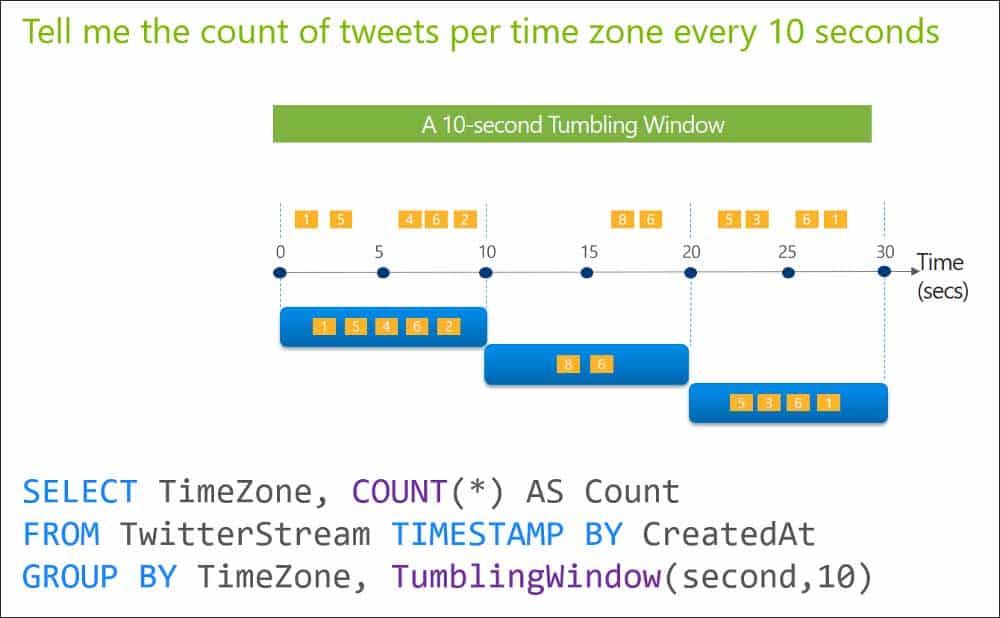
DP-203 Data Engineering on Microsoft Azure Part 03 Q08 048 -
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure Stream Analytics solution that will analyze Twitter data.
You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only once.
Solution: You use a session window that uses a timeout size of 10 seconds.
Does this meet the goal?
- Yes
- No
Explanation:Instead use a tumbling window. Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals.
-
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure Stream Analytics solution that will analyze Twitter data.
You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only once.
Solution: You use a hopping window that uses a hop size of 5 seconds and a window size 10 seconds.
Does this meet the goal?
- Yes
- No
Explanation:Instead use a tumbling window. Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals.
-
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads:
– A workload for data engineers who will use Python and SQL.
– A workload for jobs that will run notebooks that use Python, Scala, and SQL.
– A workload that data scientists will use to perform ad hoc analysis in Scala and R.The enterprise architecture team at your company identifies the following standards for Databricks environments:
– The data engineers must share a cluster.
– The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster.
– All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists.You need to create the Databricks clusters for the workloads.
Solution: You create a High Concurrency cluster for each data scientist, a High Concurrency cluster for the data engineers, and a Standard cluster for the jobs.
Does this meet the goal?
- Yes
- No
Explanation:Need a High Concurrency cluster for the jobs.
Standard clusters are recommended for a single user. Standard can run workloads developed in any language: Python, R, Scala, and SQL.
A high concurrency cluster is a managed cloud resource. The key benefits of high concurrency clusters are that they provide Apache Spark-native fine-grained sharing for maximum resource utilization and minimum query latencies.
-
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads:
– A workload for data engineers who will use Python and SQL.
– A workload for jobs that will run notebooks that use Python, Scala, and SQL.
– A workload that data scientists will use to perform ad hoc analysis in Scala and R.The enterprise architecture team at your company identifies the following standards for Databricks environments:
– The data engineers must share a cluster.
– The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster.
– All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists.You need to create the Databricks clusters for the workloads.
Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a Standard cluster for the jobs.
Does this meet the goal?
- Yes
- No
Explanation:We would need a High Concurrency cluster for the jobs.
Note:
Standard clusters are recommended for a single user. Standard can run workloads developed in any language: Python, R, Scala, and SQL.A high concurrency cluster is a managed cloud resource. The key benefits of high concurrency clusters are that they provide Apache Spark-native fine-grained sharing for maximum resource utilization and minimum query latencies.
-
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads:
– A workload for data engineers who will use Python and SQL.
– A workload for jobs that will run notebooks that use Python, Scala, and SQL.
– A workload that data scientists will use to perform ad hoc analysis in Scala and R.The enterprise architecture team at your company identifies the following standards for Databricks environments:
– The data engineers must share a cluster.
– The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster.
– All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists.You need to create the Databricks clusters for the workloads.
Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a High Concurrency cluster for the jobs.
Does this meet the goal?
- Yes
- No
Explanation:We need a High Concurrency cluster for the data engineers and the jobs.
Note:
Standard clusters are recommended for a single user. Standard can run workloads developed in any language: Python, R, Scala, and SQL.A high concurrency cluster is a managed cloud resource. The key benefits of high concurrency clusters are that they provide Apache Spark-native fine-grained sharing for maximum resource utilization and minimum query latencies.
-
HOTSPOT
You plan to create a real-time monitoring app that alerts users when a device travels more than 200 meters away from a designated location.
You need to design an Azure Stream Analytics job to process the data for the planned app. The solution must minimize the amount of code developed and the number of technologies used.
What should you include in the Stream Analytics job? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-203 Data Engineering on Microsoft Azure Part 03 Q14 049 Question 
DP-203 Data Engineering on Microsoft Azure Part 03 Q14 049 Answer Explanation:Input type: Stream
You can process real-time IoT data streams with Azure Stream Analytics.Function: Geospatial
With built-in geospatial functions, you can use Azure Stream Analytics to build applications for scenarios such as fleet management, ride sharing, connected cars, and asset tracking.Note: In a real-world scenario, you could have hundreds of these sensors generating events as a stream. Ideally, a gateway device would run code to push these events to Azure Event Hubs or Azure IoT Hubs.
-
A company has a real-time data analysis solution that is hosted on Microsoft Azure. The solution uses Azure Event Hub to ingest data and an Azure Stream Analytics cloud job to analyze the data. The cloud job is configured to use 120 Streaming Units (SU).
You need to optimize performance for the Azure Stream Analytics job.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- Implement event ordering.
- Implement Azure Stream Analytics user-defined functions (UDF).
- Implement query parallelization by partitioning the data output.
- Scale the SU count for the job up.
- Scale the SU count for the job down.
- Implement query parallelization by partitioning the data input.
Explanation:D: Scale out the query by allowing the system to process each input partition separately.
F: A Stream Analytics job definition includes inputs, a query, and output. Inputs are where the job reads the data stream from. -
You need to trigger an Azure Data Factory pipeline when a file arrives in an Azure Data Lake Storage Gen2 container.
Which resource provider should you enable?
- Microsoft.Sql
- Microsoft.Automation
- Microsoft.EventGrid
- Microsoft.EventHub
Explanation:Event-driven architecture (EDA) is a common data integration pattern that involves production, detection, consumption, and reaction to events. Data integration scenarios often require Data Factory customers to trigger pipelines based on events happening in storage account, such as the arrival or deletion of a file in Azure Blob Storage account. Data Factory natively integrates with Azure Event Grid, which lets you trigger pipelines on such events. -
You plan to perform batch processing in Azure Databricks once daily.
Which type of Databricks cluster should you use?
- High Concurrency
- automated
- interactive
Explanation:Azure Databricks has two types of clusters: interactive and automated. You use interactive clusters to analyze data collaboratively with interactive notebooks. You use automated clusters to run fast and robust automated jobs.
Example: Scheduled batch workloads (data engineers running ETL jobs)
This scenario involves running batch job JARs and notebooks on a regular cadence through the Databricks platform.The suggested best practice is to launch a new cluster for each run of critical jobs. This helps avoid any issues (failures, missing SLA, and so on) due to an existing workload (noisy neighbor) on a shared cluster.
-
HOTSPOT
You are processing streaming data from vehicles that pass through a toll booth.
You need to use Azure Stream Analytics to return the license plate, vehicle make, and hour the last vehicle passed during each 10-minute window.
How should you complete the query? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
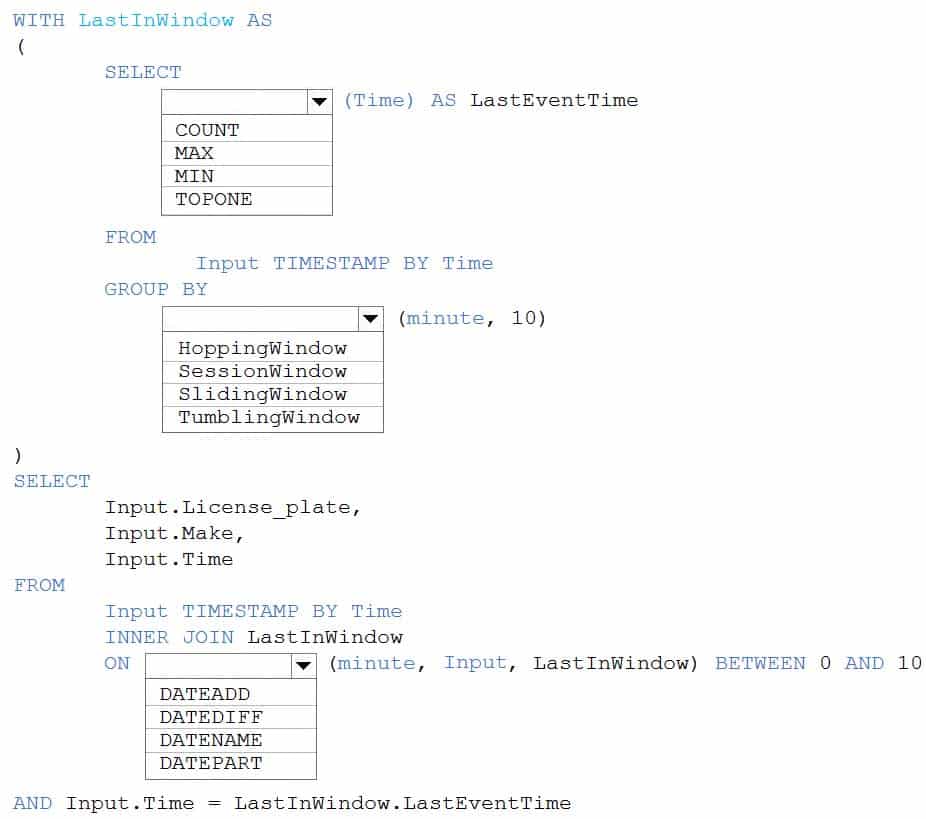
DP-203 Data Engineering on Microsoft Azure Part 03 Q18 050 Question 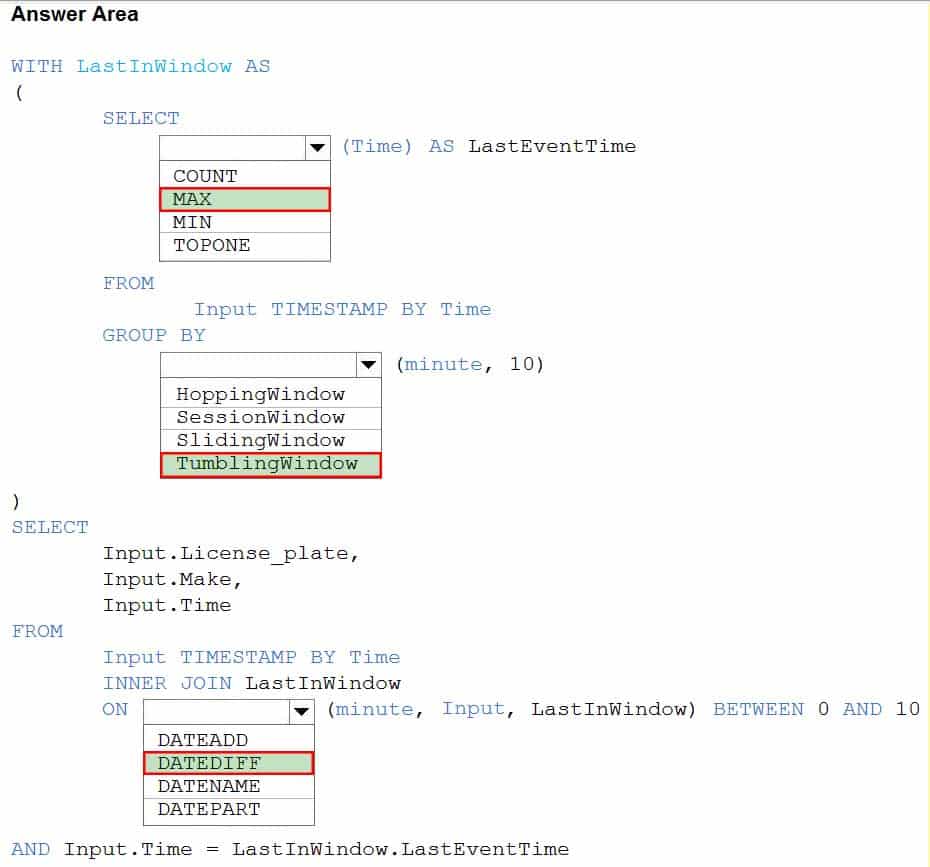
DP-203 Data Engineering on Microsoft Azure Part 03 Q18 050 Answer Explanation:Box 1: MAX
The first step on the query finds the maximum time stamp in 10-minute windows, that is the time stamp of the last event for that window. The second step joins the results of the first query with the original stream to find the event that match the last time stamps in each window.Query:
WITH LastInWindow AS
(
SELECT
MAX(Time) AS LastEventTime
FROM
Input TIMESTAMP BY Time
GROUP BY
TumblingWindow(minute, 10)
)SELECT
Input.License_plate,
Input.Make,
Input.Time
FROM
Input TIMESTAMP BY Time
INNER JOIN LastInWindow
ON DATEDIFF(minute, Input, LastInWindow) BETWEEN 0 AND 10
AND Input.Time = LastInWindow.LastEventTimeBox 2: TumblingWindow
Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals.Box 3: DATEDIFF
DATEDIFF is a date-specific function that compares and returns the time difference between two DateTime fields, for more information, refer to date functions. -
You have an Azure Data Factory instance that contains two pipelines named Pipeline1 and Pipeline2.
Pipeline1 has the activities shown in the following exhibit.

DP-203 Data Engineering on Microsoft Azure Part 03 Q19 051 Pipeline2 has the activities shown in the following exhibit.

DP-203 Data Engineering on Microsoft Azure Part 03 Q19 052 You execute Pipeline2, and Stored procedure1 in Pipeline1 fails.
What is the status of the pipeline runs?
- Pipeline1 and Pipeline2 succeeded.
- Pipeline1 and Pipeline2 failed.
- Pipeline1 succeeded and Pipeline2 failed.
- Pipeline1 failed and Pipeline2 succeeded.
Explanation:Activities are linked together via dependencies. A dependency has a condition of one of the following: Succeeded, Failed, Skipped, or Completed.
Consider Pipeline1:
If we have a pipeline with two activities where Activity2 has a failure dependency on Activity1, the pipeline will not fail just because Activity1 failed. If Activity1 fails and Activity2 succeeds, the pipeline will succeed. This scenario is treated as a try-catch block by Data Factory.
DP-203 Data Engineering on Microsoft Azure Part 03 Q19 053 The failure dependency means this pipeline reports success.
Note:
If we have a pipeline containing Activity1 and Activity2, and Activity2 has a success dependency on Activity1, it will only execute if Activity1 is successful. In this scenario, if Activity1 fails, the pipeline will fail. -
HOTSPOT
A company plans to use Platform-as-a-Service (PaaS) to create the new data pipeline process. The process must meet the following requirements:
Ingest:
– Access multiple data sources.
– Provide the ability to orchestrate workflow.
– Provide the capability to run SQL Server Integration Services packages.Store:
– Optimize storage for big data workloads.
– Provide encryption of data at rest.
– Operate with no size limits.Prepare and Train:
– Provide a fully-managed and interactive workspace for exploration and visualization.
– Provide the ability to program in R, SQL, Python, Scala, and Java.
– Provide seamless user authentication with Azure Active Directory.Model & Serve:
– Implement native columnar storage.
– Support for the SQL language
– Provide support for structured streaming.You need to build the data integration pipeline.
Which technologies should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
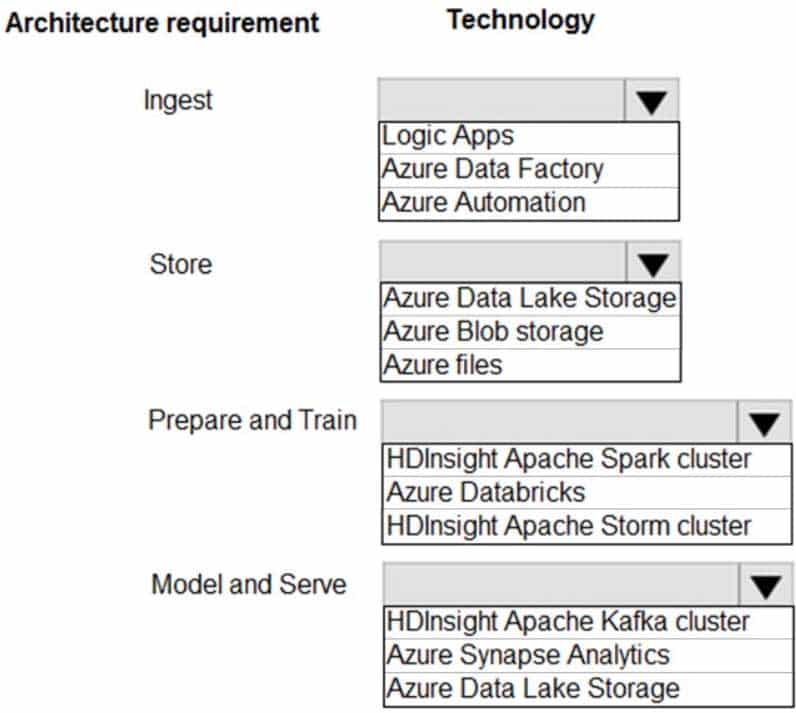
DP-203 Data Engineering on Microsoft Azure Part 03 Q20 054 Question 
DP-203 Data Engineering on Microsoft Azure Part 03 Q20 054 Answer Explanation:Ingest: Azure Data Factory
Azure Data Factory pipelines can execute SSIS packages.
In Azure, the following services and tools will meet the core requirements for pipeline orchestration, control flow, and data movement: Azure Data Factory, Oozie on HDInsight, and SQL Server Integration Services (SSIS).Store: Data Lake Storage
Data Lake Storage Gen1 provides unlimited storage.Note: Data at rest includes information that resides in persistent storage on physical media, in any digital format. Microsoft Azure offers a variety of data storage solutions to meet different needs, including file, disk, blob, and table storage. Microsoft also provides encryption to protect Azure SQL Database, Azure Cosmos DB, and Azure Data Lake.
Prepare and Train: Azure Databricks
Azure Databricks provides enterprise-grade Azure security, including Azure Active Directory integration.
With Azure Databricks, you can set up your Apache Spark environment in minutes, auto scale and collaborate on shared projects in an interactive workspace. Azure Databricks supports Python, Scala, R, Java and SQL, as well as data science frameworks and libraries including TensorFlow, PyTorch and scikit-learn.Model and Serve: Azure Synapse Analytics
Azure Synapse Analytics/ SQL Data Warehouse stores data into relational tables with columnar storage.
Azure SQL Data Warehouse connector now offers efficient and scalable structured streaming write support for SQL Data Warehouse. Access SQL Data Warehouse from Azure Databricks using the SQL Data Warehouse connector.Note: Note: As of November 2019, Azure SQL Data Warehouse is now Azure Synapse Analytics.