DP-203 : Data Engineering on Microsoft Azure : Part 04
DP-203 : Data Engineering on Microsoft Azure : Part 04
-
DRAG DROP
You have the following table named Employees.

DP-203 Data Engineering on Microsoft Azure Part 04 Q01 055 You need to calculate the employee_type value based on the hire_date value.
How should you complete the Transact-SQL statement? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

DP-203 Data Engineering on Microsoft Azure Part 04 Q01 056 Question 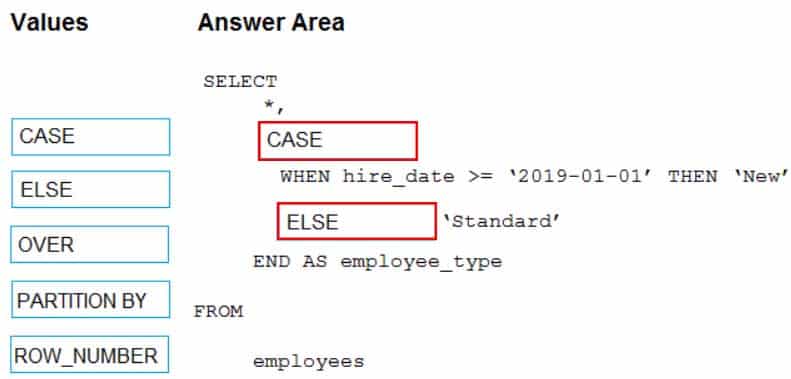
DP-203 Data Engineering on Microsoft Azure Part 04 Q01 056 Answer Explanation:Box 1: CASE
CASE evaluates a list of conditions and returns one of multiple possible result expressions.CASE can be used in any statement or clause that allows a valid expression. For example, you can use CASE in statements such as SELECT, UPDATE, DELETE and SET, and in clauses such as select_list, IN, WHERE, ORDER BY, and HAVING.
Syntax: Simple CASE expression:
CASE input_expression
WHEN when_expression THEN result_expression [ …n ]
[ ELSE else_result_expression ]
ENDBox 2: ELSE
-
DRAG DROP
You have an Azure Synapse Analytics workspace named WS1.
You have an Azure Data Lake Storage Gen2 container that contains JSON-formatted files in the following format.

DP-203 Data Engineering on Microsoft Azure Part 04 Q02 057 You need to use the serverless SQL pool in WS1 to read the files.
How should you complete the Transact-SQL statement? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
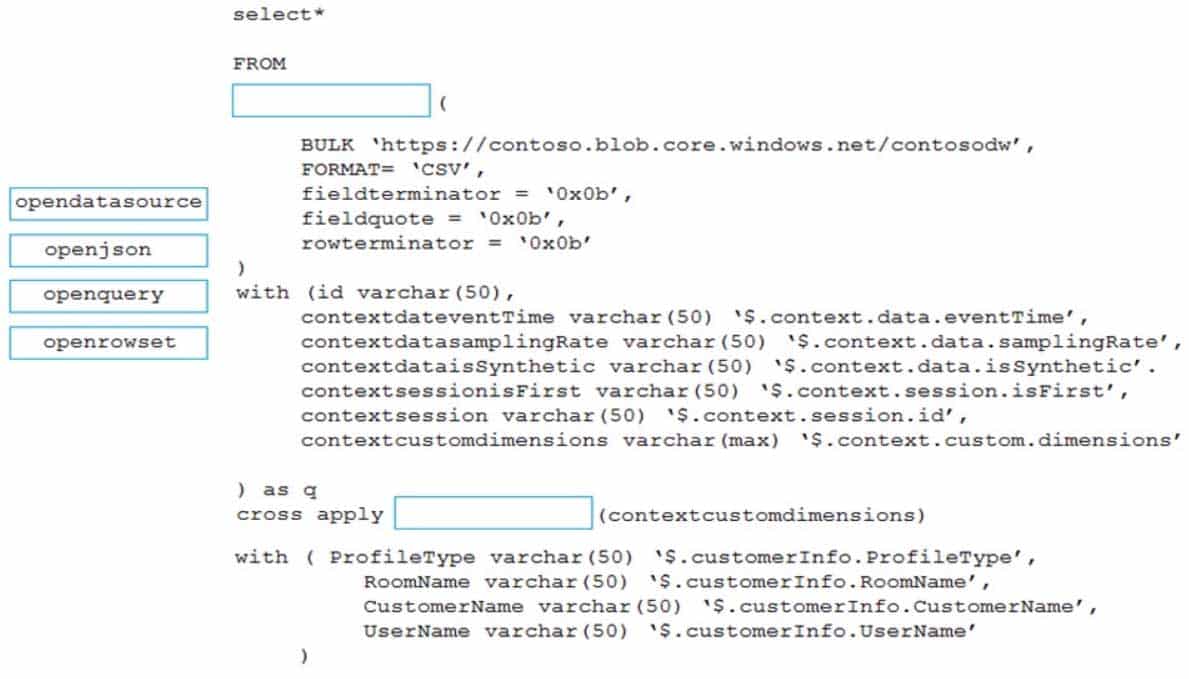
DP-203 Data Engineering on Microsoft Azure Part 04 Q02 058 Question 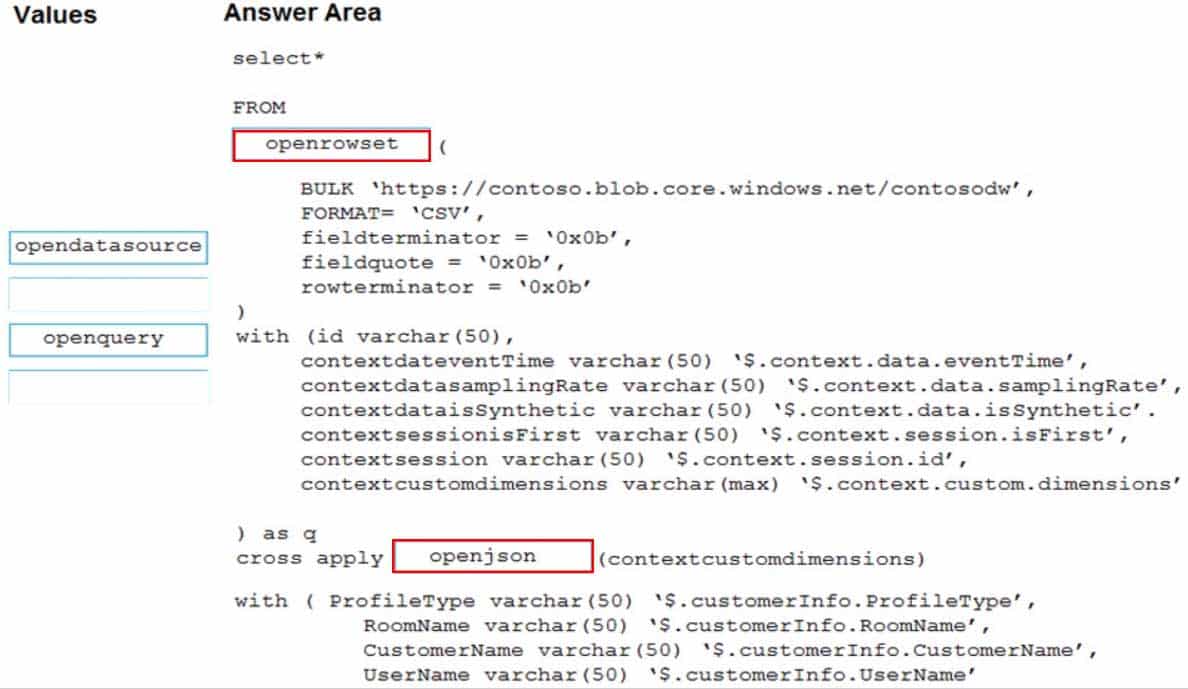
DP-203 Data Engineering on Microsoft Azure Part 04 Q02 058 Answer Explanation:Box 1: open rowset
The easiest way to see to the content of your CSV file is to provide file URL to OPENROWSET function, specify csv FORMAT.Example:
SELECT *
FROM OPENROWSET(
BULK ‘csv/population/population.csv’,
DATA_SOURCE = ‘SqlOnDemandDemo’,
FORMAT = ‘CSV’, PARSER_VERSION = ‘2.0’,
FIELDTERMINATOR =’,’,
ROWTERMINATOR = ‘\n’Box 2: open json
You can access your JSON files from the Azure File Storage share by using the mapped drive, as shown in the following example:SELECT book.* FROM
OPENROWSET(BULK N’t:\books\books.json’, SINGLE_CLOB) AS json
CROSS APPLY OPENJSON(BulkColumn)
WITH( id nvarchar(100), name nvarchar(100), price float,
pages_i int, author nvarchar(100)) AS book -
HOTSPOT
You have an Apache Spark DataFrame named temperatures. A sample of the data is shown in the following table.

DP-203 Data Engineering on Microsoft Azure Part 04 Q03 059 You need to produce the following table by using a Spark SQL query.

DP-203 Data Engineering on Microsoft Azure Part 04 Q03 060 How should you complete the query? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
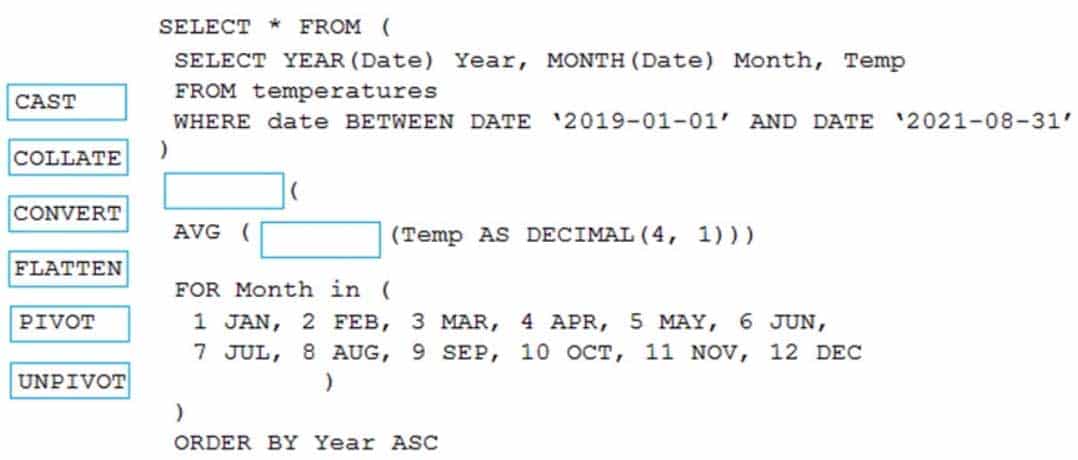
DP-203 Data Engineering on Microsoft Azure Part 04 Q03 061 Question 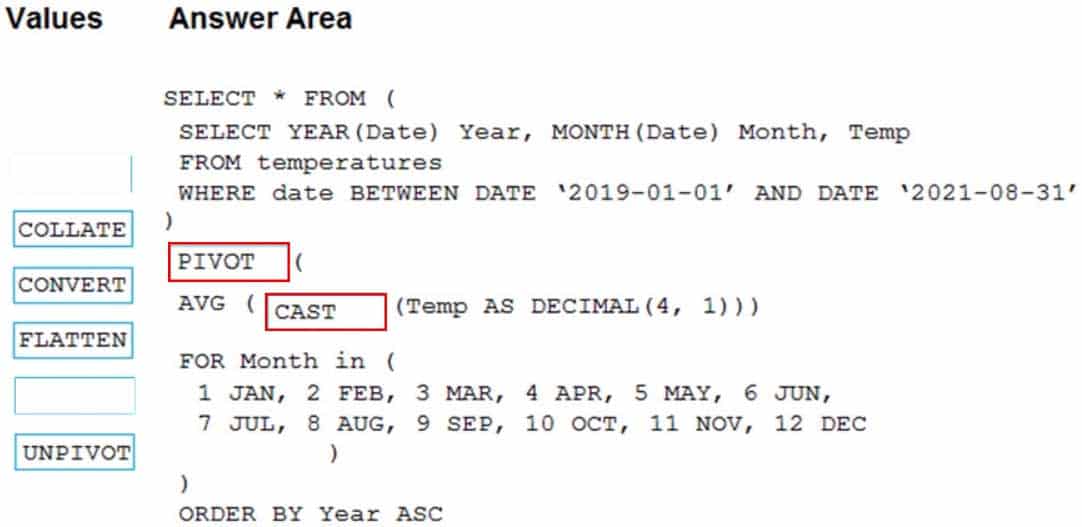
DP-203 Data Engineering on Microsoft Azure Part 04 Q03 061 Answer Explanation:Box 1: PIVOT
PIVOT rotates a table-valued expression by turning the unique values from one column in the expression into multiple columns in the output. And PIVOT runs aggregations where they’re required on any remaining column values that are wanted in the final output.Incorrect Answers:
UNPIVOT carries out the opposite operation to PIVOT by rotating columns of a table-valued expression into column values.Box 2: CAST
If you want to convert an integer value to a DECIMAL data type in SQL Server use the CAST() function.Example:
SELECT
CAST(12 AS DECIMAL(7,2) ) AS decimal_value;Here is the result:
decimal_value
12.00 -
You have an Azure Data Factory that contains 10 pipelines.
You need to label each pipeline with its main purpose of either ingest, transform, or load. The labels must be available for grouping and filtering when using the monitoring experience in Data Factory.
What should you add to each pipeline?
- a resource tag
- a correlation ID
- a run group ID
- an annotation
Explanation:Annotations are additional, informative tags that you can add to specific factory resources: pipelines, datasets, linked services, and triggers. By adding annotations, you can easily filter and search for specific factory resources. -
HOTSPOT
The following code segment is used to create an Azure Databricks cluster.

DP-203 Data Engineering on Microsoft Azure Part 04 Q05 062 For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

DP-203 Data Engineering on Microsoft Azure Part 04 Q05 063 Question 
DP-203 Data Engineering on Microsoft Azure Part 04 Q05 063 Answer Explanation:Box 1: Yes
A cluster mode of ‘High Concurrency’ is selected, unlike all the others which are ‘Standard’. This results in a worker type of Standard_DS13_v2.Box 2: No
When you run a job on a new cluster, the job is treated as a data engineering (job) workload subject to the job workload pricing. When you run a job on an existing cluster, the job is treated as a data analytics (all-purpose) workload subject to all-purpose workload pricing.Box 3: Yes
Delta Lake on Databricks allows you to configure Delta Lake based on your workload patterns. -
You are designing a statistical analysis solution that will use custom proprietary Python functions on near real-time data from Azure Event Hubs.
You need to recommend which Azure service to use to perform the statistical analysis. The solution must minimize latency.
What should you recommend?
- Azure Synapse Analytics
- Azure Databricks
- Azure Stream Analytics
- Azure SQL Database
-
HOTSPOT
You have an enterprise data warehouse in Azure Synapse Analytics that contains a table named FactOnlineSales. The table contains data from the start of 2009 to the end of 2012.
You need to improve the performance of queries against FactOnlineSales by using table partitions. The solution must meet the following requirements:
– Create four partitions based on the order date.
– Ensure that each partition contains all the orders places during a given calendar year.How should you complete the T-SQL command? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
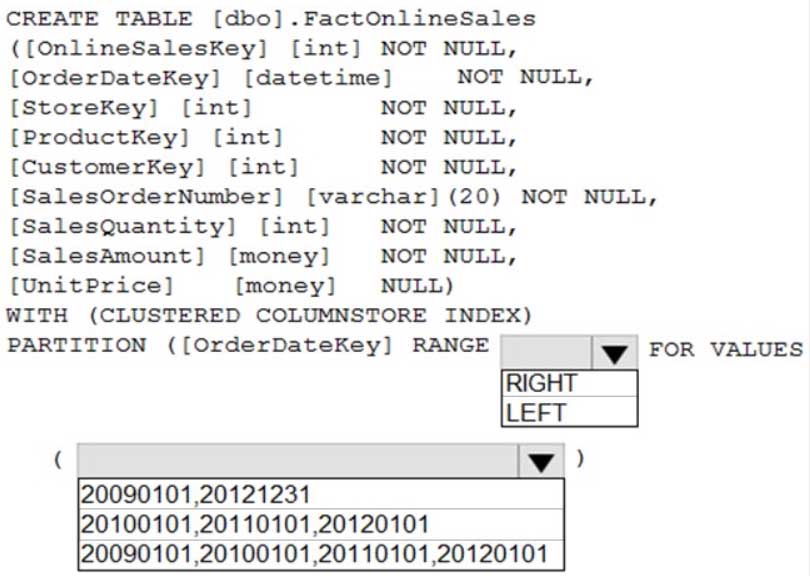
DP-203 Data Engineering on Microsoft Azure Part 04 Q07 064 Question 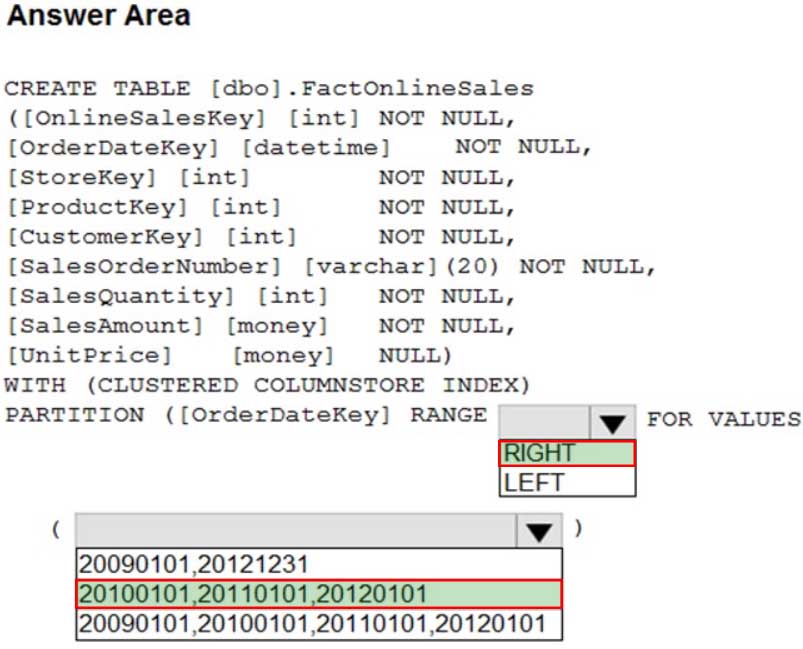
DP-203 Data Engineering on Microsoft Azure Part 04 Q07 064 Answer Explanation:Range Left or Right, both are creating similar partition but there is difference in comparison
For example: in this scenario, when you use LEFT and 20100101,20110101,20120101
Partition will be, datecol<=20100101, datecol>20100101 and datecol<=20110101, datecol>20110101 and datecol<=20120101, datecol>20120101But if you use range RIGHT and 20100101,20110101,20120101
Partition will be, datecol<20100101, datecol>=20100101 and datecol<20110101, datecol>=20110101 and datecol<20120101, datecol>=20120101In this example, Range RIGHT will be suitable for calendar comparison Jan 1st to Dec 31st
-
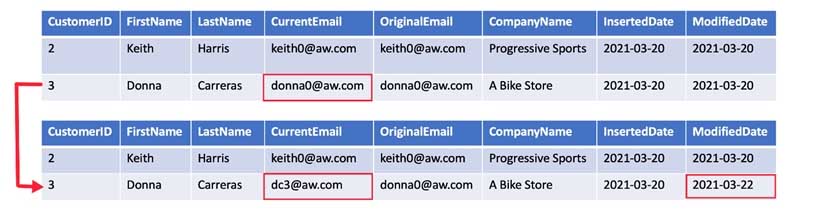
You need to implement a Type 3 slowly changing dimension (SCD) for product category data in an Azure Synapse Analytics dedicated SQL pool.
You have a table that was created by using the following Transact-SQL statement.

DP-203 Data Engineering on Microsoft Azure Part 04 Q08 065 Which two columns should you add to the table? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
-
[EffectiveStartDate] [datetime] NOT NULL,
-
[CurrentProductCategory] [nvarchar] (100) NOT NULL, -
[EffectiveEndDate] [datetime] NULL,
-
[ProductCategory] [nvarchar] (100) NOT NULL,
-
[OriginalProductCategory] [nvarchar] (100) NOT NULL,
Explanation:A Type 3 SCD supports storing two versions of a dimension member as separate columns. The table includes a column for the current value of a member plus either the original or previous value of the member. So Type 3 uses additional columns to track one key instance of history, rather than storing additional rows to track each change like in a Type 2 SCD.
This type of tracking may be used for one or two columns in a dimension table. It is not common to use it for many members of the same table. It is often used in combination with Type 1 or Type 2 members.
DP-203 Data Engineering on Microsoft Azure Part 04 Q08 066 -
-
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure Stream Analytics solution that will analyze Twitter data.
You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only once.
Solution: You use a hopping window that uses a hop size of 10 seconds and a window size of 10 seconds.
Does this meet the goal?
- Yes
- No
Explanation:Instead use a tumbling window. Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals. -
Case study
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.Overview
Litware, Inc. owns and operates 300 convenience stores across the US. The company sells a variety of packaged foods and drinks, as well as a variety of prepared foods, such as sandwiches and pizzas.
Litware has a loyalty club whereby members can get daily discounts on specific items by providing their membership number at checkout.
Litware employs business analysts who prefer to analyze data by using Microsoft Power BI, and data scientists who prefer analyzing data in Azure Databricks notebooks.
Requirements
Business Goals
Litware wants to create a new analytics environment in Azure to meet the following requirements:
– See inventory levels across the stores. Data must be updated as close to real time as possible.
– Execute ad hoc analytical queries on historical data to identify whether the loyalty club discounts increase sales of the discounted products.
– Every four hours, notify store employees about how many prepared food items to produce based on historical demand from the sales data.Technical Requirements
Litware identifies the following technical requirements:
– Minimize the number of different Azure services needed to achieve the business goals.
– Use platform as a service (PaaS) offerings whenever possible and avoid having to provision virtual machines that must be managed by Litware.
– Ensure that the analytical data store is accessible only to the company’s on-premises network and Azure services.
– Use Azure Active Directory (Azure AD) authentication whenever possible.
– Use the principle of least privilege when designing security.
– Stage Inventory data in Azure Data Lake Storage Gen2 before loading the data into the analytical data store. Litware wants to remove transient data from Data Lake Storage once the data is no longer in use. Files that have a modified date that is older than 14 days must be removed.
– Limit the business analysts’ access to customer contact information, such as phone numbers, because this type of data is not analytically relevant.
– Ensure that you can quickly restore a copy of the analytical data store within one hour in the event of corruption or accidental deletion.Planned Environment
Litware plans to implement the following environment:
– The application development team will create an Azure event hub to receive real-time sales data, including store number, date, time, product ID, customer loyalty number, price, and discount amount, from the point of sale (POS) system and output the data to data storage in Azure.
– Customer data, including name, contact information, and loyalty number, comes from Salesforce, a SaaS application, and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
– Product data, including product ID, name, and category, comes from Salesforce and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
– Daily inventory data comes from a Microsoft SQL server located on a private network.
– Litware currently has 5 TB of historical sales data and 100 GB of customer data. The company expects approximately 100 GB of new data per month for the next year.
– Litware will build a custom application named FoodPrep to provide store employees with the calculation results of how many prepared food items to produce every four hours.
– Litware does not plan to implement Azure ExpressRoute or a VPN between the on-premises network and Azure.-
What should you recommend to prevent users outside the Litware on-premises network from accessing the analytical data store?
- a server-level virtual network rule
- a database-level virtual network rule
- a server-level firewall IP rule
- a database-level firewall IP rule
Explanation:Scenario: Ensure that the analytical data store is accessible only to the company’s on-premises network and Azure services.
Virtual network rules are one firewall security feature that controls whether the database server for your single databases and elastic pool in Azure SQL Database or for your databases in SQL Data Warehouse accepts communications that are sent from particular subnets in virtual networks.
Server-level, not database-level: Each virtual network rule applies to your whole Azure SQL Database server, not just to one particular database on the server. In other words, virtual network rule applies at the server-level, not at the database-level.
-
What should you recommend using to secure sensitive customer contact information?
- Transparent Data Encryption (TDE)
- row-level security
- column-level security
- data sensitivity labels
Explanation:Scenario: Limit the business analysts’ access to customer contact information, such as phone numbers, because this type of data is not analytically relevant.
Labeling: You can apply sensitivity-classification labels persistently to columns by using new metadata attributes that have been added to the SQL Server database engine. This metadata can then be used for advanced, sensitivity-based auditing and protection scenarios.
Incorrect Answers:
A: Transparent Data Encryption (TDE) encrypts SQL Server, Azure SQL Database, and Azure Synapse Analytics data files, known as encrypting data at rest. TDE does not provide encryption across communication channels.
-
-
DRAG DROP
You have an Azure data factory.
You need to ensure that pipeline-run data is retained for 120 days. The solution must ensure that you can query the data by using the Kusto query language.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.

DP-203 Data Engineering on Microsoft Azure Part 04 Q11 067 Question 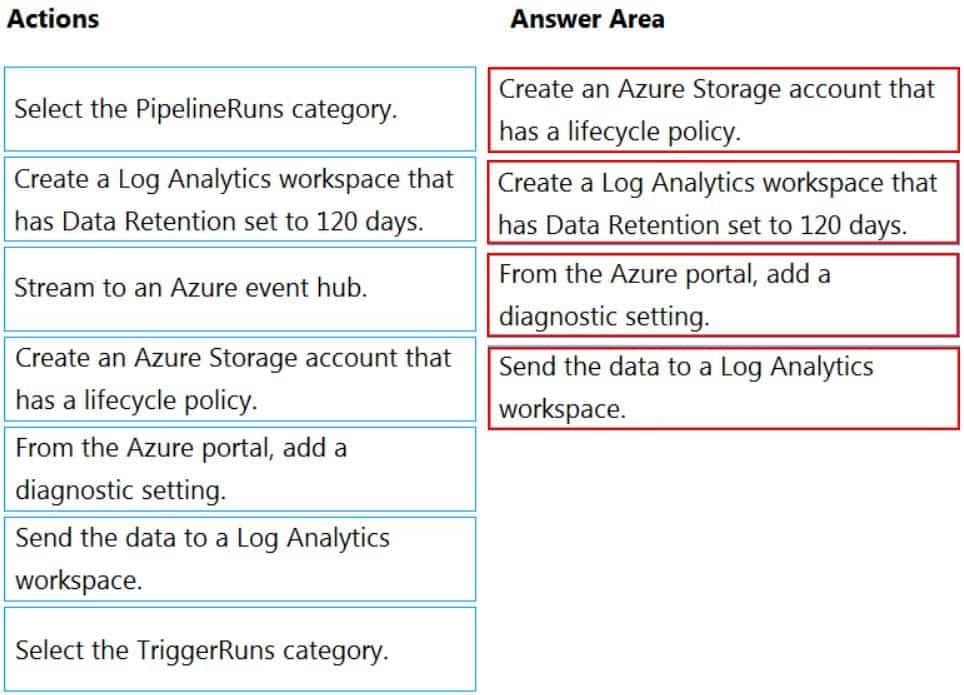
DP-203 Data Engineering on Microsoft Azure Part 04 Q11 067 Answer Explanation:Step 1: Create an Azure Storage account that has a lifecycle policy
To automate common data management tasks, Microsoft created a solution based on Azure Data Factory. The service, Data Lifecycle Management, makes frequently accessed data available and archives or purges other data according to retention policies. Teams across the company use the service to reduce storage costs, improve app performance, and comply with data retention policies.Step 2: Create a Log Analytics workspace that has Data Retention set to 120 days.
Data Factory stores pipeline-run data for only 45 days. Use Azure Monitor if you want to keep that data for a longer time. With Monitor, you can route diagnostic logs for analysis to multiple different targets, such as a Storage Account: Save your diagnostic logs to a storage account for auditing or manual inspection. You can use the diagnostic settings to specify the retention time in days.Step 3: From Azure Portal, add a diagnostic setting.
Step 4: Send the data to a log Analytics workspace,
Event Hub: A pipeline that transfers events from services to Azure Data Explorer.Keeping Azure Data Factory metrics and pipeline-run data.
Configure diagnostic settings and workspace.
Create or add diagnostic settings for your data factory.
1. In the portal, go to Monitor. Select Settings > Diagnostic settings.
2. Select the data factory for which you want to set a diagnostic setting.
3. If no settings exist on the selected data factory, you’re prompted to create a setting. Select Turn on diagnostics.
4. Give your setting a name, select Send to Log Analytics, and then select a workspace from Log Analytics Workspace.
5. Select Save. -
You have an Azure Synapse Analytics dedicated SQL pool.
You need to ensure that data in the pool is encrypted at rest. The solution must NOT require modifying applications that query the data.
What should you do?
- Enable encryption at rest for the Azure Data Lake Storage Gen2 account.
- Enable Transparent Data Encryption (TDE) for the pool.
- Use a customer-managed key to enable double encryption for the Azure Synapse workspace.
- Create an Azure key vault in the Azure subscription grant access to the pool.
Explanation:Transparent Data Encryption (TDE) helps protect against the threat of malicious activity by encrypting and decrypting your data at rest. When you encrypt your database, associated backups and transaction log files are encrypted without requiring any changes to your applications. TDE encrypts the storage of an entire database by using a symmetric key called the database encryption key. -
DRAG DROP
You have an Azure Active Directory (Azure AD) tenant that contains a security group named Group1. You have an Azure Synapse Analytics dedicated SQL pool named dw1 that contains a schema named schema1.
You need to grant Group1 read-only permissions to all the tables and views in schema1. The solution must use the principle of least privilege.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.

DP-203 Data Engineering on Microsoft Azure Part 04 Q13 068 Question 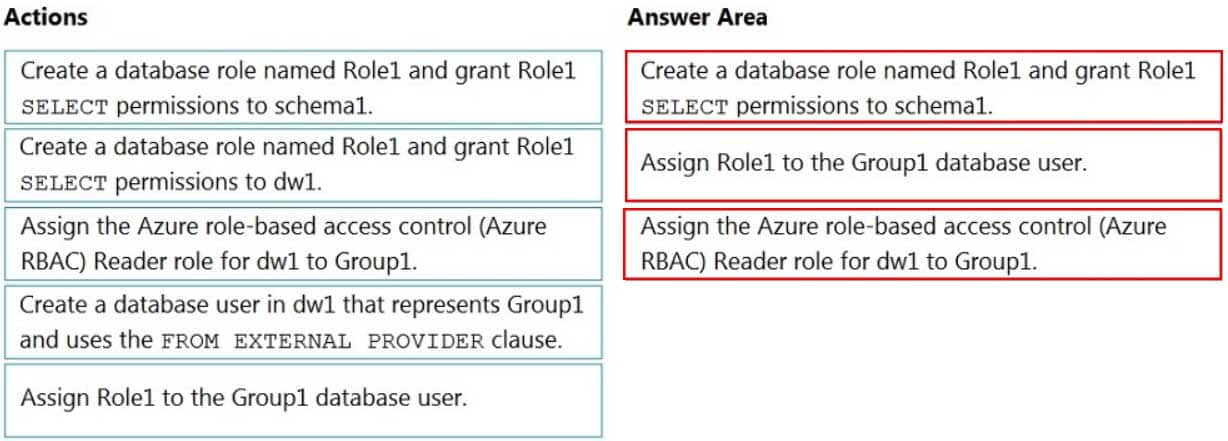
DP-203 Data Engineering on Microsoft Azure Part 04 Q13 068 Answer Explanation:Step 1: Create a database role named Role1 and grant Role1 SELECT permissions to schema
You need to grant Group1 read-only permissions to all the tables and views in schema1.
Place one or more database users into a database role and then assign permissions to the database role.Step 2: Assign Rol1 to the Group database user
Step 3: Assign the Azure role-based access control (Azure RBAC) Reader role for dw1 to Group1
-
HOTSPOT
You have an Azure subscription that contains a logical Microsoft SQL server named Server1. Server1 hosts an Azure Synapse Analytics SQL dedicated pool named Pool1.
You need to recommend a Transparent Data Encryption (TDE) solution for Server1. The solution must meet the following requirements:
– Track the usage of encryption keys.
– Maintain the access of client apps to Pool1 in the event of an Azure datacenter outage that affects the availability of the encryption keys.What should you include in the recommendation? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-203 Data Engineering on Microsoft Azure Part 04 Q14 069 Question 
DP-203 Data Engineering on Microsoft Azure Part 04 Q14 069 Answer Explanation:Box 1: TDE with customer-managed keys
Customer-managed keys are stored in the Azure Key Vault. You can monitor how and when your key vaults are accessed, and by whom. You can do this by enabling logging for Azure Key Vault, which saves information in an Azure storage account that you provide.Box 2: Create and configure Azure key vaults in two Azure regions
The contents of your key vault are replicated within the region and to a secondary region at least 150 miles away, but within the same geography to maintain high durability of your keys and secrets. -
You plan to create an Azure Synapse Analytics dedicated SQL pool.
You need to minimize the time it takes to identify queries that return confidential information as defined by the company’s data privacy regulations and the users who executed the queues.
Which two components should you include in the solution? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- sensitivity-classification labels applied to columns that contain confidential information
- resource tags for databases that contain confidential information
- audit logs sent to a Log Analytics workspace
- dynamic data masking for columns that contain confidential information
Explanation:A: You can classify columns manually, as an alternative or in addition to the recommendation-based classification:

DP-203 Data Engineering on Microsoft Azure Part 04 Q15 070 1. Select Add classification in the top menu of the pane.
2. In the context window that opens, select the schema, table, and column that you want to classify, and the information type and sensitivity label.
3. Select Add classification at the bottom of the context window.C: An important aspect of the information-protection paradigm is the ability to monitor access to sensitive data. Azure SQL Auditing has been enhanced to include a new field in the audit log called data_sensitivity_information. This field logs the sensitivity classifications (labels) of the data that was returned by a query. Here’s an example:

DP-203 Data Engineering on Microsoft Azure Part 04 Q15 071 -
You are designing an enterprise data warehouse in Azure Synapse Analytics that will contain a table named Customers. Customers will contain credit card information.
You need to recommend a solution to provide salespeople with the ability to view all the entries in Customers. The solution must prevent all the salespeople from viewing or inferring the credit card information.
What should you include in the recommendation?
- data masking
- Always Encrypted
- column-level security
- row-level security
Explanation:SQL Database dynamic data masking limits sensitive data exposure by masking it to non-privileged users.
The Credit card masking method exposes the last four digits of the designated fields and adds a constant string as a prefix in the form of a credit card.
Example: XXXX-XXXX-XXXX-1234
-
You develop data engineering solutions for a company.
A project requires the deployment of data to Azure Data Lake Storage.
You need to implement role-based access control (RBAC) so that project members can manage the Azure Data Lake Storage resources.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- Create security groups in Azure Active Directory (Azure AD) and add project members.
- Configure end-user authentication for the Azure Data Lake Storage account.
- Assign Azure AD security groups to Azure Data Lake Storage.
- Configure Service-to-service authentication for the Azure Data Lake Storage account.
- Configure access control lists (ACL) for the Azure Data Lake Storage account.
Explanation:AC: Create security groups in Azure Active Directory. Assign users or security groups to Data Lake Storage Gen1 accounts.
E: Assign users or security groups as ACLs to the Data Lake Storage Gen1 file system
-
You have an Azure Data Factory version 2 (V2) resource named Df1. Df1 contains a linked service.
You have an Azure Key vault named vault1 that contains an encryption key named key1.
You need to encrypt Df1 by using key1.
What should you do first?
- Add a private endpoint connection to vaul1.
- Enable Azure role-based access control on vault1.
- Remove the linked service from Df1.
- Create a self-hosted integration runtime.
Explanation:Linked services are much like connection strings, which define the connection information needed for Data Factory to connect to external resources.
Incorrect Answers:
D: A self-hosted integration runtime copies data between an on-premises store and cloud storage. -
You are designing an Azure Synapse Analytics dedicated SQL pool.
You need to ensure that you can audit access to Personally Identifiable Information (PII).
What should you include in the solution?
- column-level security
- dynamic data masking
- row-level security (RLS)
- sensitivity classifications
Explanation:Data Discovery & Classification is built into Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse Analytics. It provides basic capabilities for discovering, classifying, labeling, and reporting the sensitive data in your databases.
Your most sensitive data might include business, financial, healthcare, or personal information. Discovering and classifying this data can play a pivotal role in your organization’s information-protection approach. It can serve as infrastructure for:
– Helping to meet standards for data privacy and requirements for regulatory compliance.
– Various security scenarios, such as monitoring (auditing) access to sensitive data.
– Controlling access to and hardening the security of databases that contain highly sensitive data. -
HOTSPOT
You have an Azure subscription that contains an Azure Data Lake Storage account. The storage account contains a data lake named DataLake1.
You plan to use an Azure data factory to ingest data from a folder in DataLake1, transform the data, and land the data in another folder.
You need to ensure that the data factory can read and write data from any folder in the DataLake1 file system. The solution must meet the following requirements:
– Minimize the risk of unauthorized user access.
– Use the principle of least privilege.
– Minimize maintenance effort.How should you configure access to the storage account for the data factory? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-203 Data Engineering on Microsoft Azure Part 04 Q20 072 Question 
DP-203 Data Engineering on Microsoft Azure Part 04 Q20 072 Answer Explanation:Box 1: Azure Active Directory (Azure AD)
On Azure, managed identities eliminate the need for developers having to manage credentials by providing an identity for the Azure resource in Azure AD and using it to obtain Azure Active Directory (Azure AD) tokens.Box 2: a managed identity
A data factory can be associated with a managed identity for Azure resources, which represents this specific data factory. You can directly use this managed identity for Data Lake Storage Gen2 authentication, similar to using your own service principal. It allows this designated factory to access and copy data to or from your Data Lake Storage Gen2.Note: The Azure Data Lake Storage Gen2 connector supports the following authentication types.
– Account key authentication
– Service principal authentication
– Managed identities for Azure resources authentication