DP-203 : Data Engineering on Microsoft Azure : Part 05
DP-203 : Data Engineering on Microsoft Azure : Part 05
-
HOTSPOT
You are designing an Azure Synapse Analytics dedicated SQL pool.
Groups will have access to sensitive data in the pool as shown in the following table.
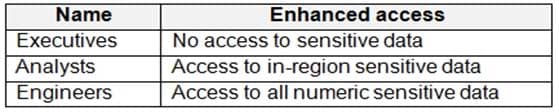
DP-203 Data Engineering on Microsoft Azure Part 05 Q01 073 You have policies for the sensitive data. The policies vary be region as shown in the following table.

DP-203 Data Engineering on Microsoft Azure Part 05 Q01 074 You have a table of patients for each region. The tables contain the following potentially sensitive columns.

DP-203 Data Engineering on Microsoft Azure Part 05 Q01 075 You are designing dynamic data masking to maintain compliance.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

DP-203 Data Engineering on Microsoft Azure Part 05 Q01 076 Question 
DP-203 Data Engineering on Microsoft Azure Part 05 Q01 076 Answer -
DRAG DROP
You have an Azure Synapse Analytics SQL pool named Pool1 on a logical Microsoft SQL server named Server1.
You need to implement Transparent Data Encryption (TDE) on Pool1 by using a custom key named key1.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

DP-203 Data Engineering on Microsoft Azure Part 05 Q02 077 Question 
DP-203 Data Engineering on Microsoft Azure Part 05 Q02 077 Answer Explanation:Step 1: Assign a managed identity to Server1
You will need an existing Managed Instance as a prerequisite.Step 2: Create an Azure key vault and grant the managed identity permissions to the vault
Create Resource and setup Azure Key Vault.Step 3: Add key1 to the Azure key vault
The recommended way is to import an existing key from a .pfx file or get an existing key from the vault. Alternatively, generate a new key directly in Azure Key Vault.Step 4: Configure key1 as the TDE protector for Server1
Provide TDE Protector keyStep 5: Enable TDE on Pool1
-
You have a data warehouse in Azure Synapse Analytics.
You need to ensure that the data in the data warehouse is encrypted at rest.
What should you enable?
- Advanced Data Security for this database
- Transparent Data Encryption (TDE)
- Secure transfer required
- Dynamic Data Masking
Explanation:Azure SQL Database currently supports encryption at rest for Microsoft-managed service side and client-side encryption scenarios.
– Support for server encryption is currently provided through the SQL feature called Transparent Data Encryption.
– Client-side encryption of Azure SQL Database data is supported through the Always Encrypted feature. -
You are designing a streaming data solution that will ingest variable volumes of data.
You need to ensure that you can change the partition count after creation.
Which service should you use to ingest the data?
- Azure Event Hubs Dedicated
- Azure Stream Analytics
- Azure Data Factory
- Azure Synapse Analytics
Explanation:You can’t change the partition count for an event hub after its creation except for the event hub in a dedicated cluster. -
You are designing a date dimension table in an Azure Synapse Analytics dedicated SQL pool. The date dimension table will be used by all the fact tables.
Which distribution type should you recommend to minimize data movement?
-
HASH
-
REPLICATE -
ROUND_ROBIN
Explanation:A replicated table has a full copy of the table available on every Compute node. Queries run fast on replicated tables since joins on replicated tables don’t require data movement. Replication requires extra storage, though, and isn’t practical for large tables.
Incorrect Answers:
A: A hash distributed table is designed to achieve high performance for queries on large tables.
C: A round-robin table distributes table rows evenly across all distributions. The rows are distributed randomly. Loading data into a round-robin table is fast. Keep in mind that queries can require more data movement than the other distribution methods. -
-
HOTSPOT
You develop a dataset named DBTBL1 by using Azure Databricks.
DBTBL1 contains the following columns:
– SensorTypeID
– GeographyRegionID
– Year
– Month
– Day
– Hour
– Minute
– Temperature
– WindSpeed
OtherYou need to store the data to support daily incremental load pipelines that vary for each GeographyRegionID. The solution must minimize storage costs.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
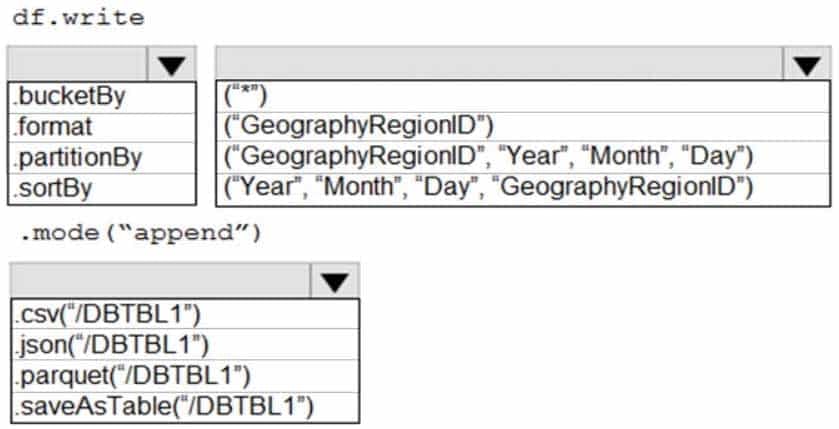
DP-203 Data Engineering on Microsoft Azure Part 05 Q06 078 Question 
DP-203 Data Engineering on Microsoft Azure Part 05 Q06 078 Answer Explanation:Box 1: .partitionBy
Incorrect Answers:
– .format:
Method: format():
Arguments: “parquet”, “csv”, “txt”, “json”, “jdbc”, “orc”, “avro”, etc.– .bucketBy:
Method: bucketBy()
Arguments: (numBuckets, col, col…, coln)
The number of buckets and names of columns to bucket by. Uses Hive’s bucketing scheme on a filesystem.Box 2: (“Year”, “Month”, “Day”,”GeographyRegionID”)
Specify the columns on which to do the partition. Use the date columns followed by the GeographyRegionID column.Box 3: .saveAsTable(“/DBTBL1”)
Method: saveAsTable()
Argument: “table_name”
The table to save to. -
Case study
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.Overview
Litware, Inc. owns and operates 300 convenience stores across the US. The company sells a variety of packaged foods and drinks, as well as a variety of prepared foods, such as sandwiches and pizzas.
Litware has a loyalty club whereby members can get daily discounts on specific items by providing their membership number at checkout.
Litware employs business analysts who prefer to analyze data by using Microsoft Power BI, and data scientists who prefer analyzing data in Azure Databricks notebooks.
Requirements
Business Goals
Litware wants to create a new analytics environment in Azure to meet the following requirements:
– See inventory levels across the stores. Data must be updated as close to real time as possible.
– Execute ad hoc analytical queries on historical data to identify whether the loyalty club discounts increase sales of the discounted products.
– Every four hours, notify store employees about how many prepared food items to produce based on historical demand from the sales data.Technical Requirements
Litware identifies the following technical requirements:
– Minimize the number of different Azure services needed to achieve the business goals.
– Use platform as a service (PaaS) offerings whenever possible and avoid having to provision virtual machines that must be managed by Litware.
– Ensure that the analytical data store is accessible only to the company’s on-premises network and Azure services.
– Use Azure Active Directory (Azure AD) authentication whenever possible.
– Use the principle of least privilege when designing security.
– Stage Inventory data in Azure Data Lake Storage Gen2 before loading the data into the analytical data store. Litware wants to remove transient data from Data Lake Storage once the data is no longer in use. Files that have a modified date that is older than 14 days must be removed.
– Limit the business analysts’ access to customer contact information, such as phone numbers, because this type of data is not analytically relevant.
– Ensure that you can quickly restore a copy of the analytical data store within one hour in the event of corruption or accidental deletion.Planned Environment
Litware plans to implement the following environment:
– The application development team will create an Azure event hub to receive real-time sales data, including store number, date, time, product ID, customer loyalty number, price, and discount amount, from the point of sale (POS) system and output the data to data storage in Azure.
– Customer data, including name, contact information, and loyalty number, comes from Salesforce, a SaaS application, and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
– Product data, including product ID, name, and category, comes from Salesforce and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
– Daily inventory data comes from a Microsoft SQL server located on a private network.
– Litware currently has 5 TB of historical sales data and 100 GB of customer data. The company expects approximately 100 GB of new data per month for the next year.
– Litware will build a custom application named FoodPrep to provide store employees with the calculation results of how many prepared food items to produce every four hours.
– Litware does not plan to implement Azure ExpressRoute or a VPN between the on-premises network and Azure.-
What should you do to improve high availability of the real-time data processing solution?
- Deploy a High Concurrency Databricks cluster.
- Deploy an Azure Stream Analytics job and use an Azure Automation runbook to check the status of the job and to start the job if it stops.
- Set Data Lake Storage to use geo-redundant storage (GRS).
- Deploy identical Azure Stream Analytics jobs to paired regions in Azure.
Explanation:Guarantee Stream Analytics job reliability during service updates
Part of being a fully managed service is the capability to introduce new service functionality and improvements at a rapid pace. As a result, Stream Analytics can have a service update deploy on a weekly (or more frequent) basis. No matter how much testing is done there is still a risk that an existing, running job may break due to the introduction of a bug. If you are running mission critical jobs, these risks need to be avoided. You can reduce this risk by following Azure’s paired region model.Scenario: The application development team will create an Azure event hub to receive real-time sales data, including store number, date, time, product ID, customer loyalty number, price, and discount amount, from the point of sale (POS) system and output the data to data storage in Azure
-
-
HOTSPOT
You have an Azure event hub named retailhub that has 16 partitions. Transactions are posted to retailhub. Each transaction includes the transaction ID, the individual line items, and the payment details. The transaction ID is used as the partition key.
You are designing an Azure Stream Analytics job to identify potentially fraudulent transactions at a retail store. The job will use retailhub as the input. The job will output the transaction ID, the individual line items, the payment details, a fraud score, and a fraud indicator.
You plan to send the output to an Azure event hub named fraudhub.
You need to ensure that the fraud detection solution is highly scalable and processes transactions as quickly as possible.
How should you structure the output of the Stream Analytics job? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-203 Data Engineering on Microsoft Azure Part 05 Q08 079 Question 
DP-203 Data Engineering on Microsoft Azure Part 05 Q08 079 Answer Explanation:Box 1: 16
For Event Hubs you need to set the partition key explicitly.An embarrassingly parallel job is the most scalable scenario in Azure Stream Analytics. It connects one partition of the input to one instance of the query to one partition of the output.
Box 2: Transaction ID
-
HOTSPOT
You have an on-premises data warehouse that includes the following fact tables. Both tables have the following columns: DateKey, ProductKey, RegionKey. There are 120 unique product keys and 65 unique region keys.
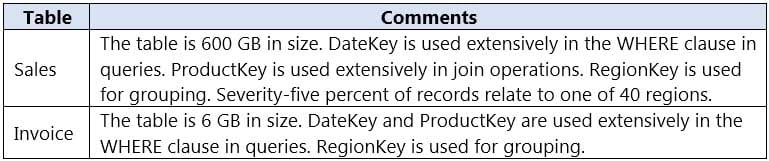
DP-203 Data Engineering on Microsoft Azure Part 05 Q09 080 Queries that use the data warehouse take a long time to complete.
You plan to migrate the solution to use Azure Synapse Analytics. You need to ensure that the Azure-based solution optimizes query performance and minimizes processing skew.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point
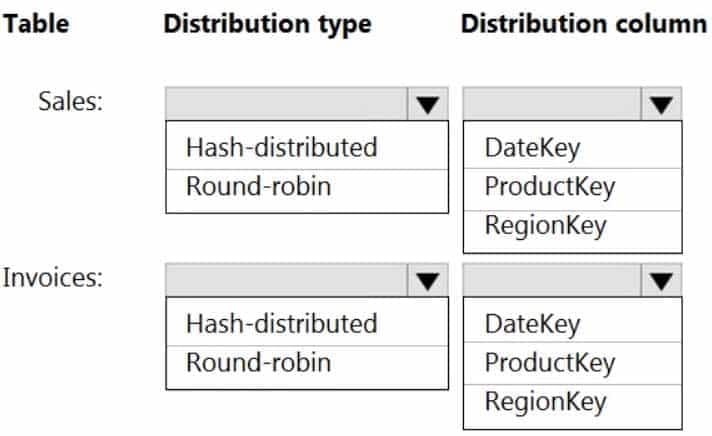
DP-203 Data Engineering on Microsoft Azure Part 05 Q09 081 Question 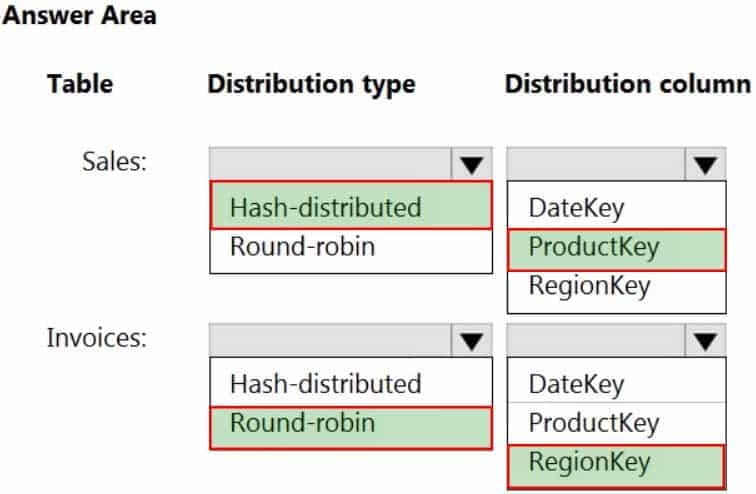
DP-203 Data Engineering on Microsoft Azure Part 05 Q09 081 Answer Explanation:Box 1: Hash-distributed
Box 2: Product Key
Product Key is used extensively in joins.
Hash-distributed tables improve query performance on large fact tables.Box 3: Round-robin
Box 4: Region Key
Round-robin tables are useful for improving loading speed.Consider using the round-robin distribution for your table in the following scenarios:
– When getting started as a simple starting point since it is the default
– If there is no obvious joining key
– If there is not good candidate column for hash distributing the table
– If the table does not share a common join key with other tables
– If the join is less significant than other joins in the query
– When the table is a temporary staging tableNote: A distributed table appears as a single table, but the rows are actually stored across 60 distributions. The rows are distributed with a hash or round-robin algorithm.
-
You have a partitioned table in an Azure Synapse Analytics dedicated SQL pool.
You need to design queries to maximize the benefits of partition elimination.
What should you include in the Transact-SQL queries?
-
JOIN
-
WHERE -
DISTINCT
-
GROUP BY
-
-
You implement an enterprise data warehouse in Azure Synapse Analytics.
You have a large fact table that is 10 terabytes (TB) in size.
Incoming queries use the primary key SaleKey column to retrieve data as displayed in the following table:

DP-203 Data Engineering on Microsoft Azure Part 05 Q11 082 You need to distribute the large fact table across multiple nodes to optimize performance of the table.
Which technology should you use?
- hash distributed table with clustered index
- hash distributed table with clustered Columnstore index
- round robin distributed table with clustered index
- round robin distributed table with clustered Columnstore index
- heap table with distribution replicate
Explanation:Hash-distributed tables improve query performance on large fact tables.
Columnstore indexes can achieve up to 100x better performance on analytics and data warehousing workloads and up to 10x better data compression than traditional rowstore indexes.
Incorrect Answers:
C, D: Round-robin tables are useful for improving loading speed. -
You have an Azure Synapse Analytics dedicated SQL pool that contains a large fact table. The table contains 50 columns and 5 billion rows and is a heap.
Most queries against the table aggregate values from approximately 100 million rows and return only two columns.
You discover that the queries against the fact table are very slow.
Which type of index should you add to provide the fastest query times?
- nonclustered columnstore
- clustered columnstore
- nonclustered
- clustered
Explanation:Clustered column store indexes are one of the most efficient ways you can store your data in dedicated SQL pool.
Column store tables won’t benefit a query unless the table has more than 60 million rows. -
You create an Azure Databricks cluster and specify an additional library to install.
When you attempt to load the library to a notebook, the library in not found.
You need to identify the cause of the issue.
What should you review?
- notebook logs
- cluster event logs
- global init scripts logs
- workspace logs
Explanation:Cluster-scoped Init Scripts: Init scripts are shell scripts that run during the startup of each cluster node before the Spark driver or worker JVM starts. Databricks customers use init scripts for various purposes such as installing custom libraries, launching background processes, or applying enterprise security policies.
Logs for Cluster-scoped init scripts are now more consistent with Cluster Log Delivery and can be found in the same root folder as driver and executor logs for the cluster.
-
You have an Azure data factory.
You need to examine the pipeline failures from the last 60 days.
What should you use?
- the Activity log blade for the Data Factory resource
- the Monitor & Manage app in Data Factory
- the Resource health blade for the Data Factory resource
- Azure Monitor
Explanation:Data Factory stores pipeline-run data for only 45 days. Use Azure Monitor if you want to keep that data for a longer time. -
You are monitoring an Azure Stream Analytics job.
The Backlogged Input Events count has been 20 for the last hour.
You need to reduce the Backlogged Input Events count.
What should you do?
- Drop late arriving events from the job.
- Add an Azure Storage account to the job.
- Increase the streaming units for the job.
- Stop the job.
Explanation:General symptoms of the job hitting system resource limits include:
– If the backlog event metric keeps increasing, it’s an indicator that the system resource is constrained (either because of output sink throttling, or high CPU).Note: Backlogged Input Events: Number of input events that are backlogged. A non-zero value for this metric implies that your job isn’t able to keep up with the number of incoming events. If this value is slowly increasing or consistently non-zero, you should scale out your job: adjust Streaming Units.
-
You are designing an Azure Databricks interactive cluster. The cluster will be used infrequently and will be configured for auto-termination.
You need to use that the cluster configuration is retained indefinitely after the cluster is terminated. The solution must minimize costs.
What should you do?
- Pin the cluster.
- Create an Azure runbook that starts the cluster every 90 days.
- Terminate the cluster manually when processing completes.
- Clone the cluster after it is terminated.
Explanation:Azure Databricks retains cluster configuration information for up to 70 all-purpose clusters terminated in the last 30 days and up to 30 job clusters recently terminated by the job scheduler. To keep an all-purpose cluster configuration even after it has been terminated for more than 30 days, an administrator can pin a cluster to the cluster list. -
You have an Azure data solution that contains an enterprise data warehouse in Azure Synapse Analytics named DW1.
Several users execute ad hoc queries to DW1 concurrently.
You regularly perform automated data loads to DW1.
You need to ensure that the automated data loads have enough memory available to complete quickly and successfully when the adhoc queries run.
What should you do?
- Hash distribute the large fact tables in DW1 before performing the automated data loads.
- Assign a smaller resource class to the automated data load queries.
- Assign a larger resource class to the automated data load queries.
- Create sampled statistics for every column in each table of DW1.
Explanation:The performance capacity of a query is determined by the user’s resource class. Resource classes are pre-determined resource limits in Synapse SQL pool that govern compute resources and concurrency for query execution.
Resource classes can help you configure resources for your queries by setting limits on the number of queries that run concurrently and on the compute-resources assigned to each query. There’s a trade-off between memory and concurrency.Smaller resource classes reduce the maximum memory per query, but increase concurrency.
Larger resource classes increase the maximum memory per query, but reduce concurrency. -
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and a database named DB1. DB1 contains a fact table named Table1.
You need to identify the extent of the data skew in Table1.
What should you do in Synapse Studio?
- Connect to the built-in pool and run DBCC PDW_SHOWSPACEUSED.
- Connect to the built-in pool and run DBCC CHECKALLOC.
- Connect to Pool1 and query sys.dm_pdw_node_status.
- Connect to Pool1 and query sys.dm_pdw_nodes_db_partition_stats.
Explanation:A quick way to check for data skew is to use DBCC PDW_SHOWSPACEUSED. The following SQL code returns the number of table rows that are stored in each of the 60 distributions. For balanced performance, the rows in your distributed table should be spread evenly across all the distributions.
DBCC PDW_SHOWSPACEUSED(‘dbo.FactInternetSales’);
-
HOTSPOT
You need to collect application metrics, streaming query events, and application log messages for an Azure Databrick cluster.
Which type of library and workspace should you implement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-203 Data Engineering on Microsoft Azure Part 05 Q19 083 Question 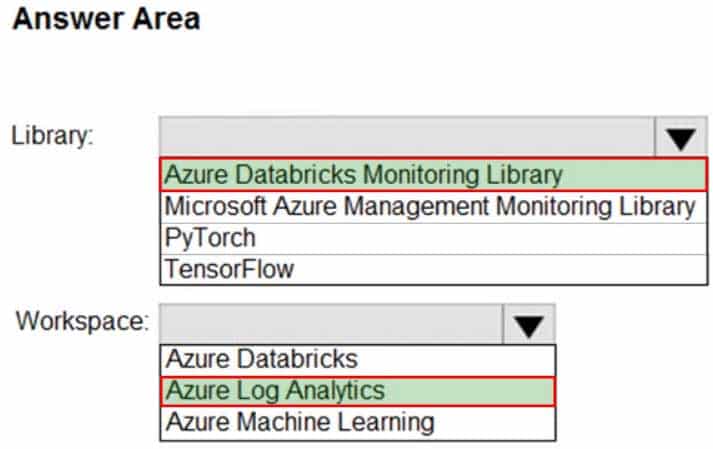
DP-203 Data Engineering on Microsoft Azure Part 05 Q19 083 Answer Explanation:You can send application logs and metrics from Azure Databricks to a Log Analytics workspace. It uses the Azure Databricks Monitoring Library, which is available on GitHub. -
You have a SQL pool in Azure Synapse.
You discover that some queries fail or take a long time to complete.
You need to monitor for transactions that have rolled back.
Which dynamic management view should you query?
-
sys.dm_pdw_request_steps
-
sys.dm_pdw_nodes_tran_database_transactions -
sys.dm_pdw_waits
-
sys.dm_pdw_exec_sessions
Explanation:You can use Dynamic Management Views (DMVs) to monitor your workload including investigating query execution in SQL pool.
If your queries are failing or taking a long time to proceed, you can check and monitor if you have any transactions rolling back.
Example:
— Monitor rollback
SELECT
SUM(CASE WHEN t.database_transaction_next_undo_lsn IS NOT NULL THEN 1 ELSE 0 END),
t.pdw_node_id,
nod.[type]
FROM sys.dm_pdw_nodes_tran_database_transactions t
JOIN sys.dm_pdw_nodes nod ON t.pdw_node_id = nod.pdw_node_id
GROUP BY t.pdw_node_id, nod.[type] -
-
You are monitoring an Azure Stream Analytics job.
You discover that the Backlogged Input Events metric is increasing slowly and is consistently non-zero.
You need to ensure that the job can handle all the events.
What should you do?
- Change the compatibility level of the Stream Analytics job.
- Increase the number of streaming units (SUs).
- Remove any named consumer groups from the connection and use $default.
- Create an additional output stream for the existing input stream.
Explanation:Backlogged Input Events: Number of input events that are backlogged. A non-zero value for this metric implies that your job isn’t able to keep up with the number of incoming events. If this value is slowly increasing or consistently non-zero, you should scale out your job. You should increase the Streaming Units.
Note: Streaming Units (SUs) represents the computing resources that are allocated to execute a Stream Analytics job. The higher the number of SUs, the more CPU and memory resources are allocated for your job.
-
You are designing an inventory updates table in an Azure Synapse Analytics dedicated SQL pool. The table will have a clustered column store index and will include the following columns:

DP-203 Data Engineering on Microsoft Azure Part 05 Q22 084 You identify the following usage patterns:
– Analysts will most commonly analyze transactions for a warehouse.
– Queries will summarize by product category type, date, and/or inventory event type.You need to recommend a partition strategy for the table to minimize query times.
On which column should you partition the table?
- EventTypeID
- ProductCategoryTypeID
- EventDate
- WarehouseID
Explanation:The number of records for each warehouse is big enough for a good partitioning.
Note: Table partitions enable you to divide your data into smaller groups of data. In most cases, table partitions are created on a date column.
When creating partitions on clustered column store tables, it is important to consider how many rows belong to each partition. For optimal compression and performance of clustered columnstore tables, a minimum of 1 million rows per distribution and partition is needed. Before partitions are created, dedicated SQL pool already divides each table into 60 distributed databases.
-
You are designing a star schema for a dataset that contains records of online orders. Each record includes an order date, an order due date, and an order ship date.
You need to ensure that the design provides the fastest query times of the records when querying for arbitrary date ranges and aggregating by fiscal calendar attributes.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- Create a date dimension table that has a DateTime key.
- Use built-in SQL functions to extract date attributes.
- Create a date dimension table that has an integer key in the format of YYYYMMDD.
- In the fact table, use integer columns for the date fields.
- Use DateTime columns for the date fields.