DP-300 : Administering Relational Databases on Microsoft Azure : Part 01
DP-300 : Administering Relational Databases on Microsoft Azure : Part 01
-
Case study
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
General Overview
Contoso, Ltd. is a financial data company that has 100 employees. The company delivers financial data to customers.
Physical Locations
Contoso has a datacenter in Los Angeles and an Azure subscription. All Azure resources are in the US West 2 Azure region. Contoso has a 10-Gb ExpressRoute connection to Azure.
The company has customers worldwide.
Existing Environment
Active Directory
Contoso has a hybrid Azure Active Directory (Azure AD) deployment that syncs to on-premises Active Directory.
Database Environment
Contoso has SQL Server 2017 on Azure virtual machines shown in the following table.

DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q01 001 SQL1 and SQL2 are in an Always On availability group and are actively queried. SQL3 runs jobs, provides historical data, and handles the delivery of data to customers.
The on-premises datacenter contains a PostgreSQL server that has a 50-TB database.
Current Business Model
Contoso uses Microsoft SQL Server Integration Services (SSIS) to create flat files for customers. The customers receive the files by using FTP.
Requirements
Planned Changes
Contoso plans to move to a model in which they deliver data to customer databases that run as platform as a service (PaaS) offerings. When a customer establishes a service agreement with Contoso, a separate resource group that contains an Azure SQL database will be provisioned for the customer. The database will have a complete copy of the financial data. The data to which each customer will have access will depend on the service agreement tier. The customers can change tiers by changing their service agreement.
The estimated size of each PaaS database is 1 TB.
Contoso plans to implement the following changes:
– Move the PostgreSQL database to Azure Database for PostgreSQL during the next six months.
– Upgrade SQL1, SQL2, and SQL3 to SQL Server 2019 during the next few months.
– Start onboarding customers to the new PaaS solution within six months.Business Goals
Contoso identifies the following business requirements:
– Use built-in Azure features whenever possible.
– Minimize development effort whenever possible.
– Minimize the compute costs of the PaaS solutions.
– Provide all the customers with their own copy of the database by using the PaaS solution.
– Provide the customers with different table and row access based on the customer’s service agreement.
– In the event of an Azure regional outage, ensure that the customers can access the PaaS solution with minimal downtime. The solution must provide automatic failover.
– Ensure that users of the PaaS solution can create their own database objects but be prevented from modifying any of the existing database objects supplied by Contoso.Technical Requirements
Contoso identifies the following technical requirements:
– Users of the PaaS solution must be able to sign in by using their own corporate Azure AD credentials or have Azure AD credentials supplied to them by Contoso. The solution must avoid using the internal Azure AD of Contoso to minimize guest users.
– All customers must have their own resource group, Azure SQL server, and Azure SQL database. The deployment of resources for each customer must be done in a consistent fashion.
– Users must be able to review the queries issued against the PaaS databases and identify any new objects created.
– Downtime during the PostgreSQL database migration must be minimized.Monitoring Requirements
Contoso identifies the following monitoring requirements:
– Notify administrators when a PaaS database has a higher than average CPU usage.
– Use a single dashboard to review security and audit data for all the PaaS databases.
– Use a single dashboard to monitor query performance and bottlenecks across all the PaaS databases.
– Monitor the PaaS databases to identify poorly performing queries and resolve query performance issues automatically whenever possible.PaaS Prototype
During prototyping of the PaaS solution in Azure, you record the compute utilization of a customer’s Azure SQL database as shown in the following exhibit.

DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q01 002 Role Assignments
For each customer’s Azure SQL Database server, you plan to assign the roles shown in the following exhibit.
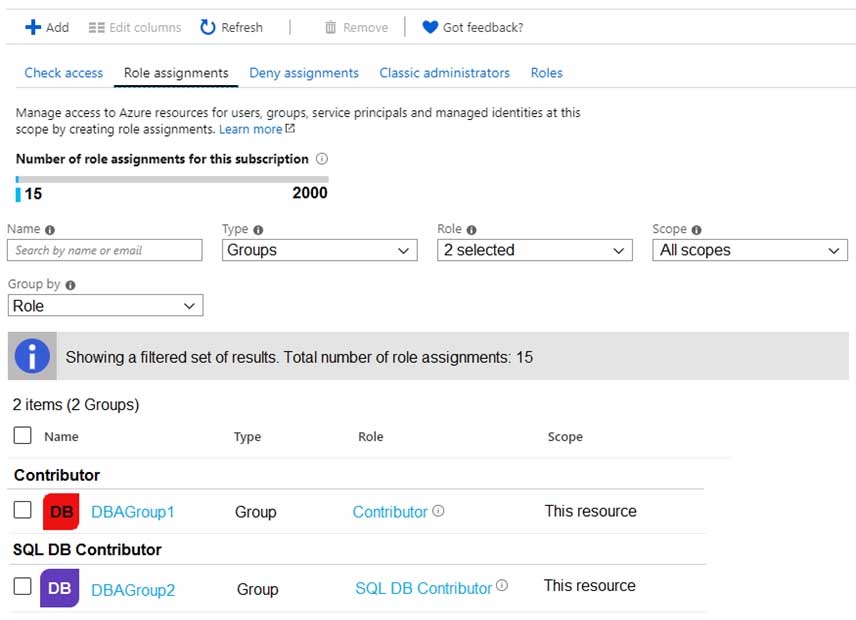
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q01 003 -
What should you use to migrate the PostgreSQL database?
- Azure Data Box
- AzCopy
- Azure Database Migration Service
- Azure Site Recovery
-
- This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
Litware, Inc. is a renewable energy company that has a main office in Boston. The main office hosts a sales department and the primary datacenter for the company.
Physical Locations
Litware has a manufacturing office and a research office is separate locations near Boston. Each office has its own datacenter and internet connection.
Existing Environment
Network Environment
The manufacturing and research datacenters connect to the primary datacenter by using a VPN.
The primary datacenter has an ExpressRoute connection that uses both Microsoft peering and private peering. The private peering connects to an Azure virtual network named HubVNet.
Identity Environment
Litware has a hybrid Azure Active Directory (Azure AD) deployment that uses a domain named litwareinc.com. All Azure subscriptions are associated to the litwareinc.com Azure AD tenant.
Database Environment
The sales department has the following database workload:
– An on-premises named SERVER1 hosts an instance of Microsoft SQL Server 2012 and two 1-TB databases.
– A logical server named SalesSrv01A contains a geo-replicated Azure SQL database named SalesSQLDb1. SalesSQLDb1 is in an elastic pool named SalesSQLDb1Pool. SalesSQLDb1 uses database firewall rules and contained database users.
– An application named SalesSQLDb1App1 uses SalesSQLDb1.The manufacturing office contains two on-premises SQL Server 2016 servers named SERVER2 and SERVER3. The servers are nodes in the same Always On availability group. The availability group contains a database named ManufacturingSQLDb1
Database administrators have two Azure virtual machines in HubVnet named VM1 and VM2 that run Windows Server 2019 and are used to manage all the Azure databases.
Licensing Agreement
Litware is a Microsoft Volume Licensing customer that has License Mobility through Software Assurance.
Current Problems
SalesSQLDb1 experiences performance issues that are likely due to out-of-date statistics and frequent blocking queries.
Requirements
Planned Changes
Litware plans to implement the following changes:
– Implement 30 new databases in Azure, which will be used by time-sensitive manufacturing apps that have varying usage patterns. Each database will be approximately 20 GB.
– Create a new Azure SQL database named ResearchDB1 on a logical server named ResearchSrv01. ResearchDB1 will contain Personally Identifiable Information (PII) data.
– Develop an app named ResearchApp1 that will be used by the research department to populate and access ResearchDB1.
– Migrate ManufacturingSQLDb1 to the Azure virtual machine platform.
– Migrate the SERVER1 databases to the Azure SQL Database platform.Technical Requirements
Litware identifies the following technical requirements:
– Maintenance tasks must be automated.
– The 30 new databases must scale automatically.
– The use of an on-premises infrastructure must be minimized.
– Azure Hybrid Use Benefits must be leveraged for Azure SQL Database deployments.
– All SQL Server and Azure SQL Database metrics related to CPU and storage usage and limits must be analyzed by using Azure built-in functionality.Security and Compliance Requirements
Litware identifies the following security and compliance requirements:
– Store encryption keys in Azure Key Vault.
– Retain backups of the PII data for two months.
– Encrypt the PII data at rest, in transit, and in use.
– Use the principle of least privilege whenever possible.
– Authenticate database users by using Active Directory credentials.
– Protect Azure SQL Database instances by using database-level firewall rules.
– Ensure that all databases hosted in Azure are accessible from VM1 and VM2 without relying on public endpoints.Business Requirements
Litware identifies the following business requirements:
– Meet an SLA of 99.99% availability for all Azure deployments.
– Minimize downtime during the migration of the SERVER1 databases.
– Use the Azure Hybrid Use Benefits when migrating workloads to Azure.
– Once all requirements are met, minimize costs whenever possible.-
HOTSPOT
You are planning the migration of the SERVER1 databases. The solution must meet the business requirements.
What should you include in the migration plan? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q02 004 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q02 004 Answer Explanation:Azure Database Migration service
Box 1: Premium 4-VCore
Scenario: Migrate the SERVER1 databases to the Azure SQL Database platform.
– Minimize downtime during the migration of the SERVER1 databases.Premimum 4-vCore is for large or business critical workloads. It supports online migrations, offline migrations, and faster migration speeds.
Incorrect Answers:
The Standard pricing tier suits most small- to medium- business workloads, but it supports offline migration only.Box 2: A VPN gateway
You need to create a Microsoft Azure Virtual Network for the Azure Database Migration Service by using the Azure Resource Manager deployment model, which provides site-to-site connectivity to your on-premises source servers by using either ExpressRoute or VPN. -
HOTSPOT
You need to recommend the appropriate purchasing model and deployment option for the 30 new databases. The solution must meet the technical requirements and the business requirements.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q02 005 Question 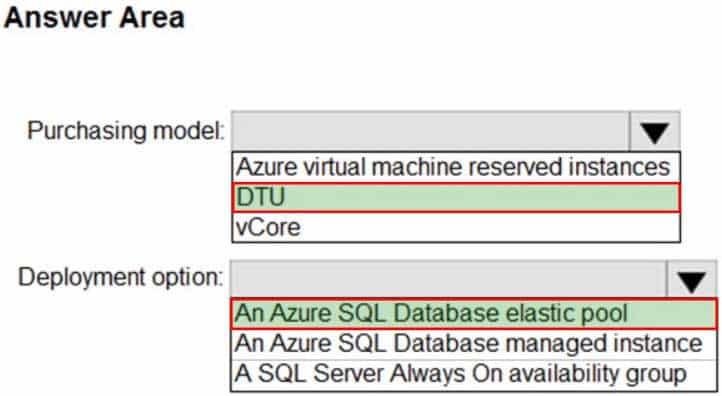
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q02 005 Answer Explanation:Box 1: DTU
Scenario:
– The 30 new databases must scale automatically.
– Once all requirements are met, minimize costs whenever possible.You can configure resources for the pool based either on the DTU-based purchasing model or the vCore-based purchasing model.
In short, for simplicity, the DTU model has an advantage. Plus, if you’re just getting started with Azure SQL Database, the DTU model offers more options at the lower end of performance, so you can get started at a lower price point than with vCore.Box 2: An Azure SQL database elastic pool
Azure SQL Database elastic pools are a simple, cost-effective solution for managing and scaling multiple databases that have varying and unpredictable usage demands. The databases in an elastic pool are on a single server and share a set number of resources at a set price. Elastic pools in Azure SQL Database enable SaaS developers to optimize the price performance for a group of databases within a prescribed budget while delivering performance elasticity for each database.
-
- This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
Contoso, Ltd. is a clothing retailer based in Seattle. The company has 2,000 retail stores across the United States and an emerging online presence.
The network contains an Active Directory forest named contoso.com. The forest is integrated with an Azure Active Directory (Azure AD) tenant named contoso.com. Contoso has an Azure subscription associated to the contoso.com Azure AD tenant.
Existing Environment
Transactional Data
Contoso has three years of customer, transaction, operational, sourcing, and supplier data comprised of 10 billion records stored across multiple on-premises Microsoft SQL Server servers. The SQL Server instances contain data from various operations systems. The data is loaded into the instances by using SQL Server Integration Services (SSIS) packages.
You estimate that combining all product sales transactions into a company-wide sales transactions dataset will result in a single table that contains 5 billion rows, with one row per transaction.
Most queries targeting the sales transactions data will be used to identify which products were sold in retail stores and which products were sold online during different time periods. Sales transaction data that is older than three years will be removed monthly.
You plan to create a retail store table that will contain the address of each retail store. The table will be approximately 2 MB. Queries for retail store sales will include the retail store addresses.
You plan to create a promotional table that will contain a promotion ID. The promotion ID will be associated to a specific product. The product will be identified by a product ID. The table will be approximately 5 GB.
Streaming Twitter Data
The ecommerce department at Contoso develops an Azure logic app that captures trending Twitter feeds referencing the company’s products and pushes the products to Azure Event Hubs.
Planned Changes and Requirements
Planned Changes
Contoso plans to implement the following changes:
– Load the sales transaction dataset to Azure Synapse Analytics.
– Integrate on-premises data stores with Azure Synapse Analytics by using SSIS packages.
– Use Azure Synapse Analytics to analyze Twitter feeds to assess customer sentiments about products.Sales Transaction Dataset Requirements
Contoso identifies the following requirements for the sales transaction dataset:
– Partition data that contains sales transaction records. Partitions must be designed to provide efficient loads by month. Boundary values must belong to the partition on the right.
– Ensure that queries joining and filtering sales transaction records based on product ID complete as quickly as possible.
– Implement a surrogate key to account for changes to the retail store addresses.
– Ensure that data storage costs and performance are predictable.
– Minimize how long it takes to remove old records.Customer Sentiment Analytics Requirements
Contoso identifies the following requirements for customer sentiment analytics:
– Allow Contoso users to use PolyBase in an Azure Synapse Analytics dedicated SQL pool to query the content of the data records that host the Twitter feeds. Data must be protected by using row-level security (RLS). The users must be authenticated by using their own Azure AD credentials.
– Maximize the throughput of ingesting Twitter feeds from Event Hubs to Azure Storage without purchasing additional throughput or capacity units.
– Store Twitter feeds in Azure Storage by using Event Hubs Capture. The feeds will be converted into Parquet files.
– Ensure that the data store supports Azure AD-based access control down to the object level.
– Minimize administrative effort to maintain the Twitter feed data records.
– Purge Twitter feed data records that are older than two years.Data Integration Requirements
Contoso identifies the following requirements for data integration:
– Use an Azure service that leverages the existing SSIS packages to ingest on-premises data into datasets stored in a dedicated SQL pool of Azure Synapse Analytics and transform the data.
– Identify a process to ensure that changes to the ingestion and transformation activities can be version-controlled and developed independently by multiple data engineers.-
You need to design a data retention solution for the Twitter feed data records. The solution must meet the customer sentiment analytics requirements.
Which Azure Storage functionality should you include in the solution?
- time-based retention
- change feed
- lifecycle management
- soft delete
Explanation:The lifecycle management policy lets you:
– Delete blobs, blob versions, and blob snapshots at the end of their lifecyclesScenario:
– Purge Twitter feed data records that are older than two years.
– Store Twitter feeds in Azure Storage by using Event Hubs Capture. The feeds will be converted into Parquet files.
– Minimize administrative effort to maintain the Twitter feed data records.Incorrect Answers:
A: Time-based retention policy support: Users can set policies to store data for a specified interval. When a time-based retention policy is set, blobs can be created and read, but not modified or deleted. After the retention period has expired, blobs can be deleted but not overwritten. -
You need to implement the surrogate key for the retail store table. The solution must meet the sales transaction dataset requirements.
What should you create?
- a table that has a FOREIGN KEY constraint
- a table the has an IDENTITY property
- a user-defined SEQUENCE object
- a system-versioned temporal table
Explanation:Scenario: Contoso requirements for the sales transaction dataset include:
– Implement a surrogate key to account for changes to the retail store addresses.A surrogate key on a table is a column with a unique identifier for each row. The key is not generated from the table data. Data modelers like to create surrogate keys on their tables when they design data warehouse models. You can use the IDENTITY property to achieve this goal simply and effectively without affecting load performance.
-
HOTSPOT
You need to design an analytical storage solution for the transactional data. The solution must meet the sales transaction dataset requirements.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q03 006 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q03 006 Answer Explanation:Box 1: Hash
Scenario:
Ensure that queries joining and filtering sales transaction records based on product ID complete as quickly as possible.A hash distributed table can deliver the highest query performance for joins and aggregations on large tables.
Box 2: Round-robin
Scenario:
You plan to create a promotional table that will contain a promotion ID. The promotion ID will be associated to a specific product. The product will be identified by a product ID. The table will be approximately 5 GB.A round-robin table is the most straightforward table to create and delivers fast performance when used as a staging table for loads. These are some scenarios where you should choose Round robin distribution:
– When you cannot identify a single key to distribute your data.
– If your data doesn’t frequently join with data from other tables.
– When there are no obvious keys to join.Incorrect Answers:
Replicated: Replicated tables eliminate the need to transfer data across compute nodes by replicating a full copy of the data of the specified table to each compute node. The best candidates for replicated tables are tables with sizes less than 2 GB compressed and small dimension tables.
-
-
You have 20 Azure SQL databases provisioned by using the vCore purchasing model.
You plan to create an Azure SQL Database elastic pool and add the 20 databases.
Which three metrics should you use to size the elastic pool to meet the demands of your workload? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- total size of all the databases
- geo-replication support
- number of concurrently peaking databases * peak CPU utilization per database
- maximum number of concurrent sessions for all the databases
- total number of databases * average CPU utilization per database
Explanation:CE: Estimate the vCores needed for the pool as follows:
For vCore-based purchasing model: MAX(<Total number of DBs X average vCore utilization per DB>, <Number of concurrently peaking DBs X Peak vCore utilization per DB)A: Estimate the storage space needed for the pool by adding the number of bytes needed for all the databases in the pool.
-
DRAG DROP
You have SQL Server 2019 on an Azure virtual machine that contains an SSISDB database.
A recent failure causes the master database to be lost.
You discover that all Microsoft SQL Server integration Services (SSIS) packages fail to run on the virtual machine.
Which four actions should you perform in sequence to resolve the issue? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct.
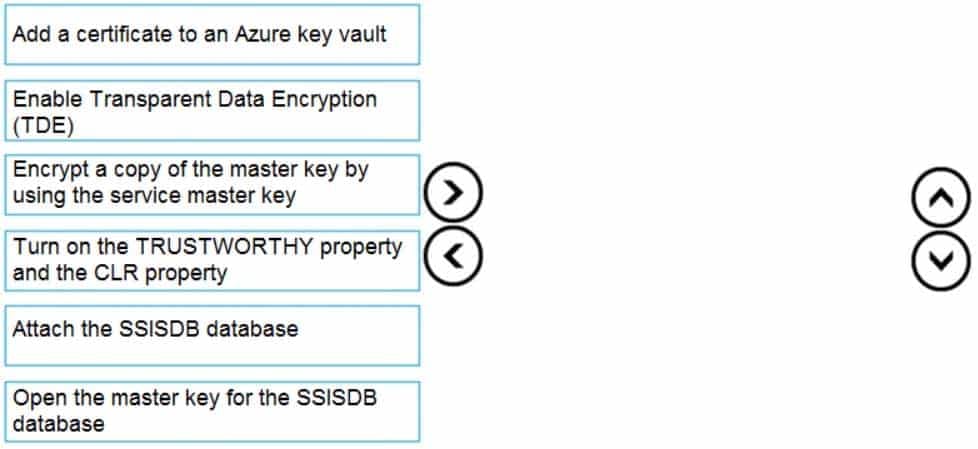
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q05 007 Question 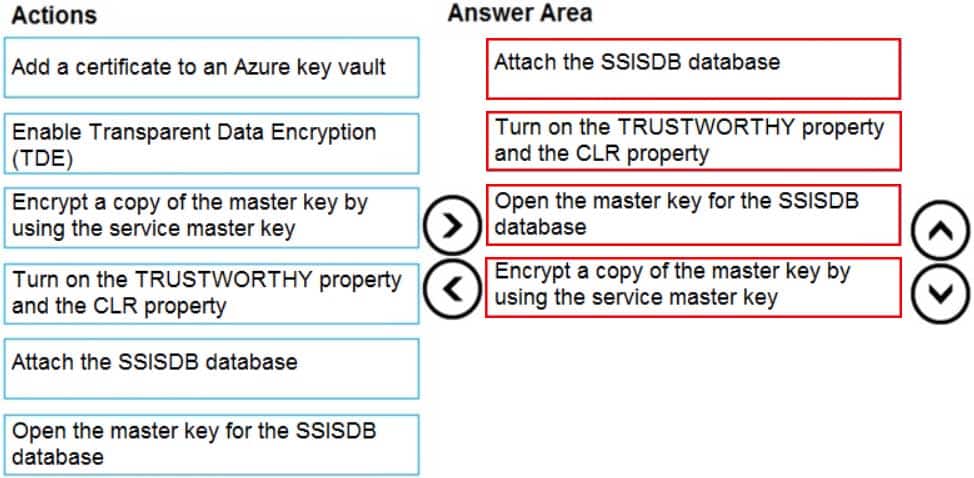
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q05 007 Answer Explanation:Step 1: Attach the SSISDB database
Step 2: Turn on the TRUSTWORTHY property and the CLR property
If you are restoring the SSISDB database to an SQL Server instance where the SSISDB catalog was never created, enable common language runtime (clr)Step 3: Open the master key for the SSISDB database
Restore the master key by this method if you have the original password that was used to create SSISDB.open master key decryption by password = ‘LS1Setup!’ –‘Password used when creating SSISDB’
Alter Master Key Add encryption by Service Master KeyStep 4: Encrypt a copy of the mater key by using the service master key
-
You have an Azure SQL database that contains a table named factSales. FactSales contains the columns shown in the following table.

DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q06 008 FactSales has 6 billion rows and is loaded nightly by using a batch process. You must provide the greatest reduction in space for the database and maximize performance.
Which type of compression provides the greatest space reduction for the database?
- page compression
- row compression
- column store compression
- column store archival compression
Explanation:Column store tables and indexes are always stored with column store compression. You can further reduce the size of column store data by configuring an additional compression called archival compression.
Note: Column store — The column store index is also logically organized as a table with rows and columns, but the data is physically stored in a column-wise data format.
Incorrect Answers:
B: Row store — The row store index is the traditional style that has been around since the initial release of SQL Server.For row store tables and indexes, use the data compression feature to help reduce the size of the database.
-
You have a Microsoft SQL Server 2019 database named DB1 that uses the following database-level and instance-level features.
– Clustered columnstore indexes
– Automatic tuning
– Change tracking
– PolyBaseYou plan to migrate DB1 to an Azure SQL database.
What feature should be removed or replaced before DB1 can be migrated?
- Clustered columnstore indexes
- PolyBase
- Change tracking
- Automatic tuning
Explanation:This table lists the key features for PolyBase and the products in which they’re available.
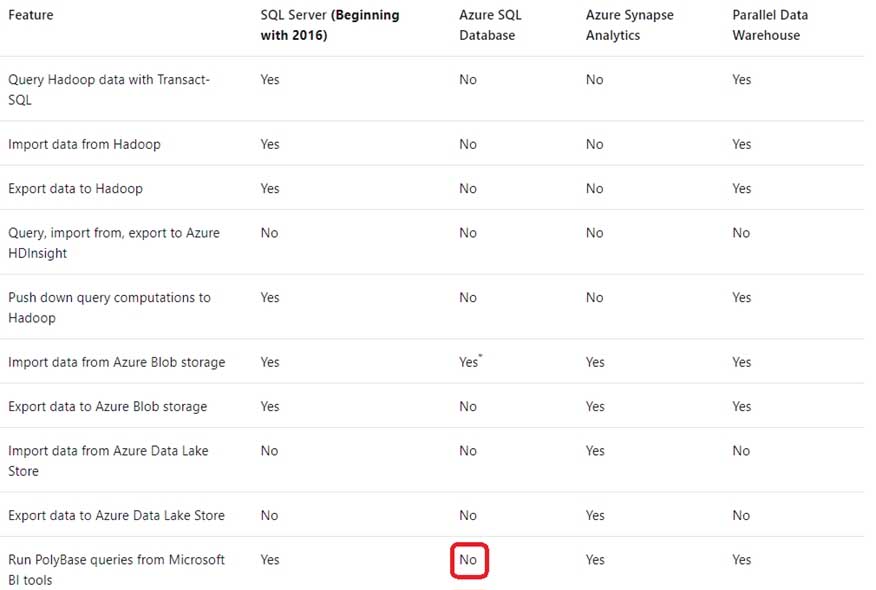
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q07 009 Incorrect Answers:
C: Change tracking is a lightweight solution that provides an efficient change tracking mechanism for applications. It applies to both Azure SQL Database and SQL Server.D: Azure SQL Database and Azure SQL Managed Instance automatic tuning provides peak performance and stable workloads through continuous performance tuning based on AI and machine learning.
-
You have a Microsoft SQL Server 2019 instance in an on-premises datacenter. The instance contains a 4-TB database named DB1.
You plan to migrate DB1 to an Azure SQL Database managed instance.
What should you use to minimize downtime and data loss during the migration?
- distributed availability groups
- database mirroring
- Always On Availability Group
- Azure Database Migration Service
-
HOTSPOT
You have an on-premises Microsoft SQL Server 2016 server named Server1 that contains a database named DB1.
You need to perform an online migration of DB1 to an Azure SQL Database managed instance by using Azure Database Migration Service.
How should you configure the backup of DB1? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q09 010 Question 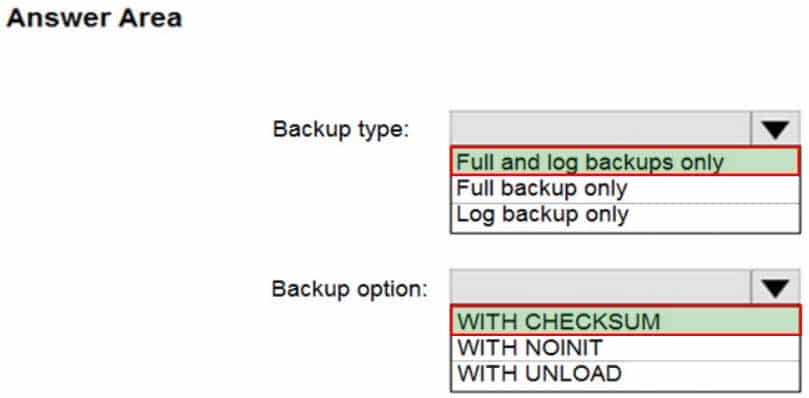
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q09 010 Answer Explanation:Box 1: Full and log backups only
Make sure to take every backup on a separate backup media (backup files). Azure Database Migration Service doesn’t support backups that are appended to a single backup file. Take full backup and log backups to separate backup files.Box 2: WITH CHECKSUM
Azure Database Migration Service uses the backup and restore method to migrate your on-premises databases to SQL Managed Instance. Azure Database Migration Service only supports backups created using checksum.Incorrect Answers:
NOINIT Indicates that the backup set is appended to the specified media set, preserving existing backup sets. If a media password is defined for the media set, the password must be supplied. NOINIT is the default.UNLOAD
Specifies that the tape is automatically rewound and unloaded when the backup is finished. UNLOAD is the default when a session begins. -
DRAG DROP
You have a resource group named App1Dev that contains an Azure SQL Database server named DevServer1. DevServer1 contains an Azure SQL database named DB1. The schema and permissions for DB1 are saved in a Microsoft SQL Server Data Tools (SSDT) database project.
You need to populate a new resource group named App1Test with the DB1 database and an Azure SQL Server named TestServer1. The resources in App1Test must have the same configurations as the resources in App1Dev.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q10 011 Question 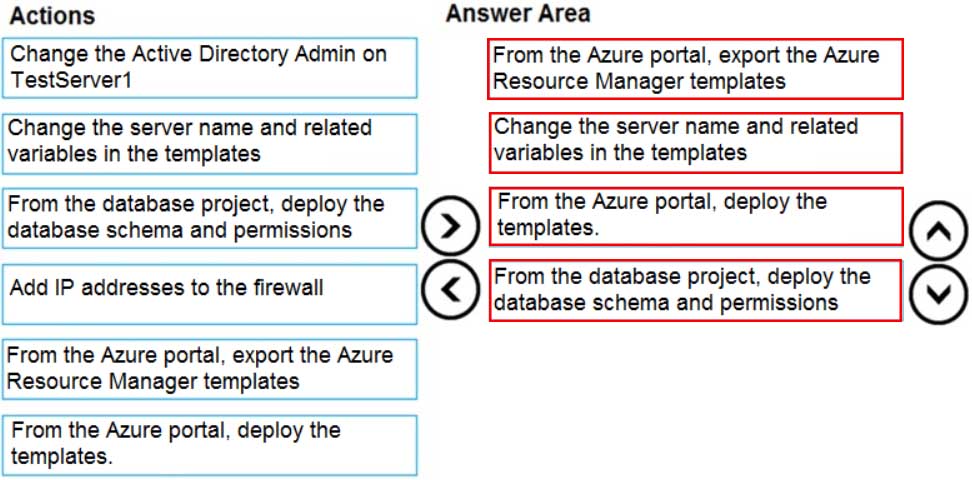
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q10 011 Answer -
HOTSPOT
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and an Azure Data Lake Storage Gen2 account named Account1.
You plan to access the files in Account1 by using an external table.
You need to create a data source in Pool1 that you can reference when you create the external table.
How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
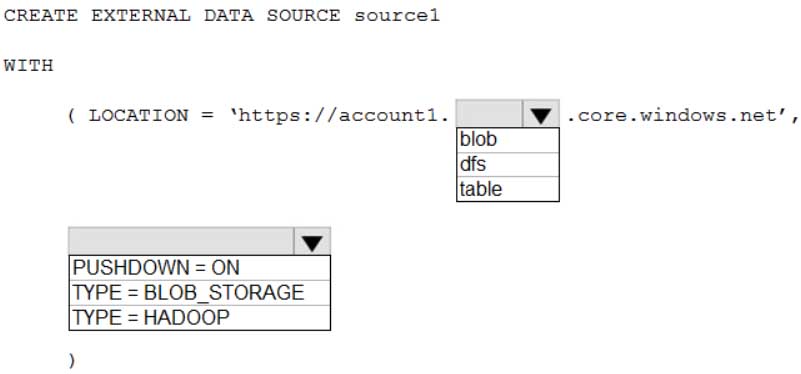
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q11 012 Question 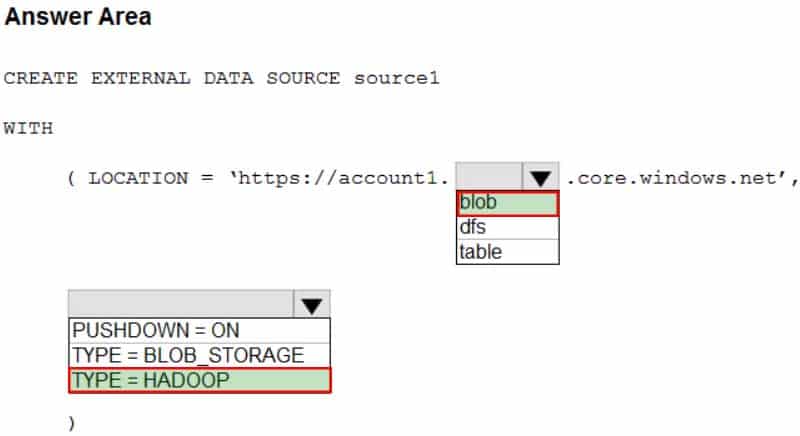
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q11 012 Answer Explanation:Box 1: blob
The following example creates an external data source for Azure Data Lake Gen2
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = ‘https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/’,
TYPE = HADOOP)Box 2: HADOOP
-
HOTSPOT
You plan to develop a dataset named Purchases by using Azure Databricks. Purchases will contain the following columns:
– ProductID
– ItemPrice
– LineTotal
– Quantity
– StoreID
– Minute
– Month
– Hour
– Year
– DayYou need to store the data to support hourly incremental load pipelines that will vary for each StoreID. The solution must minimize storage costs.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
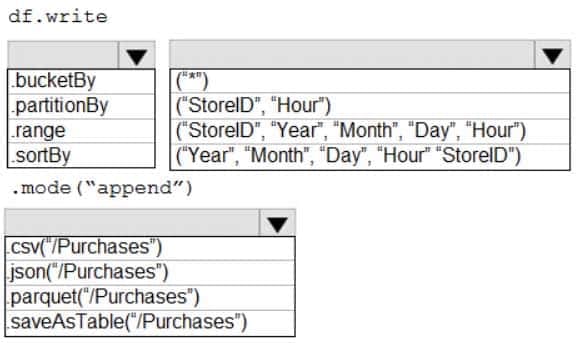
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q12 013 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q12 013 Answer Explanation:Box 1: .partitionBy
Example:
df.write.partitionBy(“y”,”m”,”d”).mode(SaveMode.Append)
.parquet(“/data/hive/warehouse/db_name.db/” + tableName)
Box 2: (“Year”,”Month”,”Day”,”Hour”,”StoreID”)
Box 3: .parquet(“/Purchases”)
-
You are designing a streaming data solution that will ingest variable volumes of data.
You need to ensure that you can change the partition count after creation.
Which service should you use to ingest the data?
- Azure Event Hubs Standard
- Azure Stream Analytics
- Azure Data Factory
- Azure Event Hubs Dedicated
Explanation:The partition count for an event hub in a dedicated Event Hubs cluster can be increased after the event hub has been created.
Incorrect Answers:
A: For Azure Event standard hubs, the partition count isn’t changeable, so you should consider long-term scale when setting partition count. -
HOTSPOT
You are building a database in an Azure Synapse Analytics serverless SQL pool.
You have data stored in Parquet files in an Azure Data Lake Storage Gen2 container.
Records are structured as shown in the following sample.

DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q14 014 The records contain two applicants at most.
You need to build a table that includes only the address fields.
How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
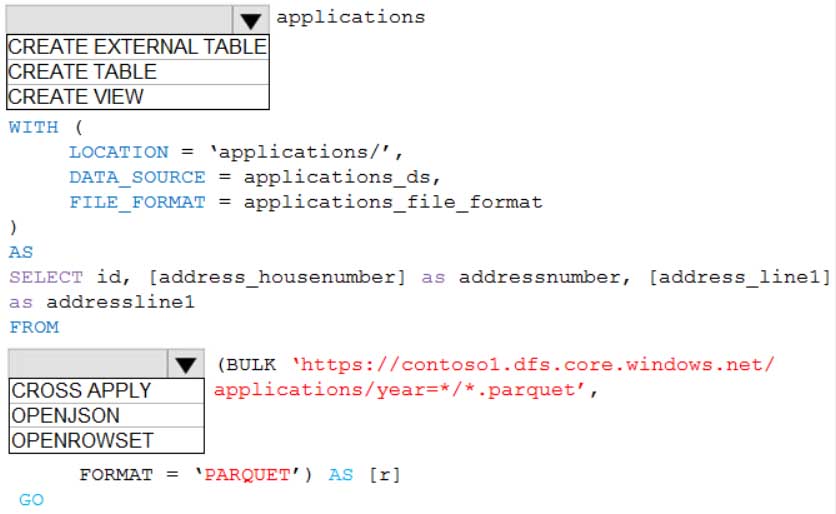
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q14 015 Question 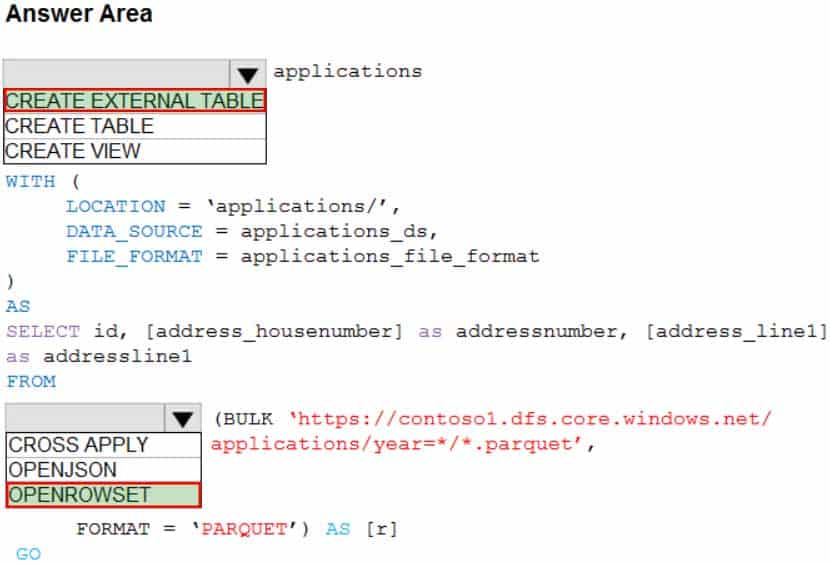
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q14 015 Answer Explanation:Box 1: CREATE EXTERNAL TABLE
An external table points to data located in Hadoop, Azure Storage blob, or Azure Data Lake Storage. External tables are used to read data from files or write data to files in Azure Storage. With Synapse SQL, you can use external tables to read external data using dedicated SQL pool or serverless SQL pool.Syntax:
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,…n ] )
WITH (
LOCATION = ‘folder_or_filepath’,
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_nameBox 2. OPENROWSET
When using serverless SQL pool, CETAS is used to create an external table and export query results to Azure Storage Blob or Azure Data Lake Storage Gen2.Example:
AS
SELECT decennialTime, stateName, SUM(population) AS population
FROM
OPENROWSET(BULK ‘https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=*/*.parquet’,
FORMAT=’PARQUET’) AS [r]
GROUP BY decennialTime, stateName
GO -
You have an Azure Synapse Analytics Apache Spark pool named Pool1.
You plan to load JSON files from an Azure Data Lake Storage Gen2 container into the tables in Pool1. The structure and data types vary by file.
You need to load the files into the tables. The solution must maintain the source data types.
What should you do?
- Load the data by using PySpark.
- Load the data by using the OPENROWSET Transact-SQL command in an Azure Synapse Analytics serverless SQL pool.
- Use a Get Metadata activity in Azure Data Factory.
- Use a Conditional Split transformation in an Azure Synapse data flow.
Explanation:Serverless SQL pool can automatically synchronize metadata from Apache Spark. A serverless SQL pool database will be created for each database existing in serverless Apache Spark pools.
Serverless SQL pool enables you to query data in your data lake. It offers a T-SQL query surface area that accommodates semi-structured and unstructured data queries.To support a smooth experience for in place querying of data that’s located in Azure Storage files, serverless SQL pool uses the OPENROWSET function with additional capabilities.
The easiest way to see to the content of your JSON file is to provide the file URL to the OPENROWSET function, specify csv FORMAT.
-
You are designing a date dimension table in an Azure Synapse Analytics dedicated SQL pool. The date dimension table will be used by all the fact tables.
Which distribution type should you recommend to minimize data movement?
-
HASH
-
REPLICATE -
ROUND_ROBIN
Explanation:A replicated table has a full copy of the table available on every Compute node. Queries run fast on replicated tables since joins on replicated tables don’t require data movement. Replication requires extra storage, though, and isn’t practical for large tables.
Incorrect Answers:
C: A round-robin distributed table distributes table rows evenly across all distributions. The assignment of rows to distributions is random. Unlike hash-distributed tables, rows with equal values are not guaranteed to be assigned to the same distribution.As a result, the system sometimes needs to invoke a data movement operation to better organize your data before it can resolve a query.
-
-
HOTSPOT
From a website analytics system, you receive data extracts about user interactions such as downloads, link clicks, form submissions, and video plays.
The data contains the following columns:
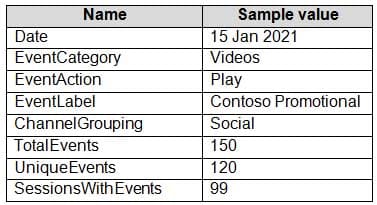
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q17 016 You need to design a star schema to support analytical queries of the data. The star schema will contain four tables including a date dimension.
To which table should you add each column? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q17 017 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q17 017 Answer Explanation:Box 1: FactEvents
Fact tables store observations or events, and can be sales orders, stock balances, exchange rates, temperatures, etc.Box 2: DimChannel
Dimension tables describe business entities – the things you model. Entities can include products, people, places, and concepts including time itself. The most consistent table you’ll find in a star schema is a date dimension table. A dimension table contains a key column (or columns) that acts as a unique identifier, and descriptive columns.Box 3: DimEvent
-
DRAG DROP
You plan to create a table in an Azure Synapse Analytics dedicated SQL pool.
Data in the table will be retained for five years. Once a year, data that is older than five years will be deleted.
You need to ensure that the data is distributed evenly across partitions. The solutions must minimize the amount of time required to delete old data.
How should you complete the Transact-SQL statement? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all.
You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q18 018 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 01 Q18 018 Answer Explanation:Box 1: HASH
Box 2: Order Date Key
In most cases, table partitions are created on a date column.A way to eliminate rollbacks is to use Metadata Only operations like partition switching for data management. For example, rather than execute a DELETE statement to delete all rows in a table where the order_date was in October of 2001, you could partition your data early. Then you can switch out the partition with data for an empty partition from another table.
-
You have an Azure Synapse Analytics workspace named WS1 that contains an Apache Spark pool named Pool1.
You plan to create a database named DB1 in Pool1.
You need to ensure that when tables are created in DB1, the tables are available automatically as external tables to the built-in serverless SQL pool.
Which format should you use for the tables in DB1?
- JSON
- CSV
- Parquet
- ORC
Explanation:Serverless SQL pool can automatically synchronize metadata from Apache Spark. A serverless SQL pool database will be created for each database existing in serverless Apache Spark pools.
For each Spark external table based on Parquet and located in Azure Storage, an external table is created in a serverless SQL pool database. As such, you can shut down your Spark pools and still query Spark external tables from serverless SQL pool.
-
You are designing an anomaly detection solution for streaming data from an Azure IoT hub. The solution must meet the following requirements:
– Send the output to an Azure Synapse.
– Identify spikes and dips in time series data.
– Minimize development and configuration effort.Which should you include in the solution?
- Azure SQL Database
- Azure Databricks
- Azure Stream Analytics
Explanation:Anomalies can be identified by routing data via IoT Hub to a built-in ML model in Azure Stream Analytics