DP-300 : Administering Relational Databases on Microsoft Azure : Part 02
DP-300 : Administering Relational Databases on Microsoft Azure : Part 02
-
You are creating a new notebook in Azure Databricks that will support R as the primary language but will also support Scala and SQL.
Which switch should you use to switch between languages?
- \\[<language>]
- %<language>
- \\[<language>]
- @<language>
Explanation:
You can override the default language by specifying the language magic command %<language> at the beginning of a cell. The supported magic commands are: %python, %r, %scala, and %sql.
-
DRAG DROP
You are creating a managed data warehouse solution on Microsoft Azure.
You must use PolyBase to retrieve data from Azure Blob storage that resides in parquet format and load the data into a large table called FactSalesOrderDetails.
You need to configure Azure Synapse Analytics to receive the data.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
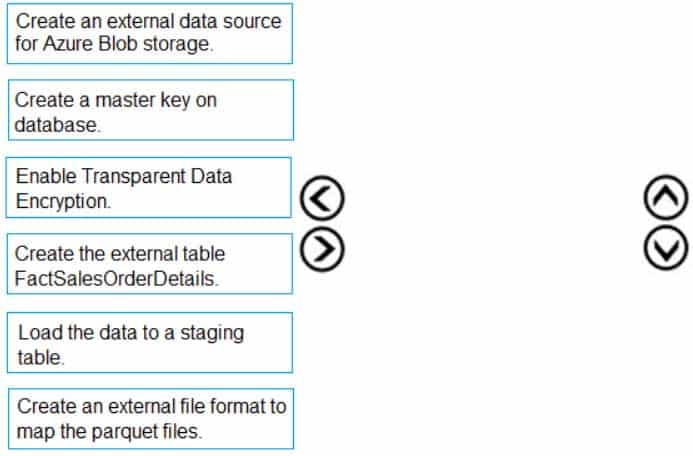
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q02 019 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q02 019 Answer Explanation:To query the data in your Hadoop data source, you must define an external table to use in Transact-SQL queries. The following steps describe how to configure the external table.
Step 1: Create a master key on database.
1. Create a master key on the database. The master key is required to encrypt the credential secret.(Create a database scoped credential for Azure blob storage.)
Step 2: Create an external data source for Azure Blob storage.
2. Create an external data source with CREATE EXTERNAL DATA SOURCE..Step 3: Create an external file format to map the parquet files.
3. Create an external file format with CREATE EXTERNAL FILE FORMAT.Step 4. Create an external table FactSalesOrderDetails
4. Create an external table pointing to data stored in Azure storage with CREATE EXTERNAL TABLE. -
HOTSPOT
You configure version control for an Azure Data Factory instance as shown in the following exhibit.
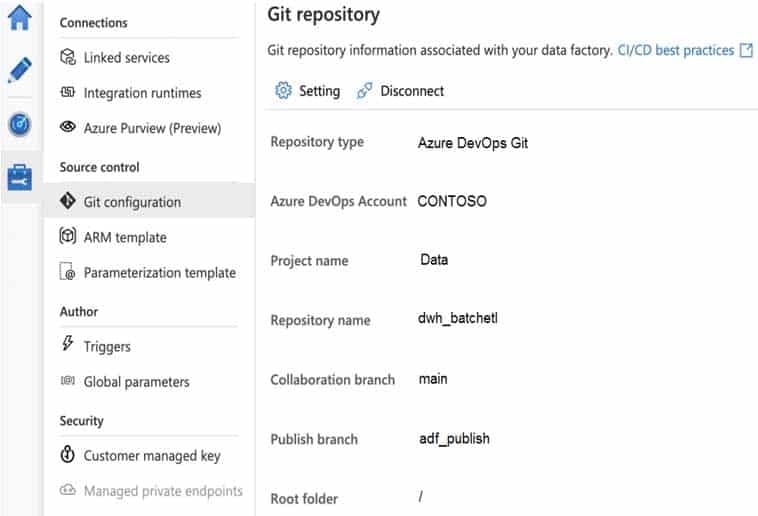
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q03 020 Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q03 021 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q03 021 Answer Explanation:Box 1: adf_publish
By default, data factory generates the Resource Manager templates of the published factory and saves them into a branch called adf_publish. To configure a custom publish branch, add a publish_config.json file to the root folder in the collaboration branch. When publishing, ADF reads this file, looks for the field publishBranch, and saves all Resource Manager templates to the specified location. If the branch doesn’t exist, data factory will automatically create it. And example of what this file looks like is below:{
“publishBranch”: “factory/adf_publish”
}Box 2: /dwh_barchlet/ adf_publish/contososales
RepositoryName: Your Azure Repos code repository name. Azure Repos projects contain Git repositories to manage your source code as your project grows. You can create a new repository or use an existing repository that’s already in your project. -
You plan to build a structured streaming solution in Azure Databricks. The solution will count new events in five-minute intervals and report only events that arrive during the interval.
The output will be sent to a Delta Lake table.
Which output mode should you use?
- complete
- append
- update
Explanation:Complete mode: You can use Structured Streaming to replace the entire table with every batch.
Incorrect Answers:
B: By default, streams run in append mode, which adds new records to the table. -
HOTSPOT
You are performing exploratory analysis of bus fare data in an Azure Data Lake Storage Gen2 account by using an Azure Synapse Analytics serverless SQL pool.
You execute the Transact-SQL query shown in the following exhibit.
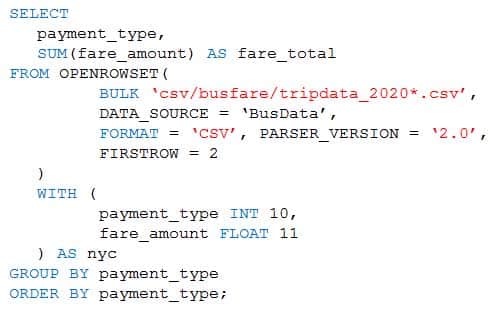
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q05 022 Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.

DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q05 023 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q05 023 Answer Explanation:Box 1: CSV files that have file named beginning with “tripdata_2020”
Box 2: a header
FIRSTROW = ‘first_row’Specifies the number of the first row to load. The default is 1 and indicates the first row in the specified data file. The row numbers are determined by counting the row terminators. FIRSTROW is 1-based.
-
You have a SQL pool in Azure Synapse that contains a table named dbo.Customers. The table contains a column name Email.
You need to prevent nonadministrative users from seeing the full email addresses in the Email column. The users must see values in a format of aXXX@XXXX.com instead.
What should you do?
- From the Azure portal, set a mask on the Email column.
- From the Azure portal, set a sensitivity classification of Confidential for the Email column.
- From Microsoft SQL Server Management Studio, set an email mask on the Email column.
- From Microsoft SQL Server Management Studio, grant the SELECT permission to the users for all the columns in the dbo.Customers table except Email.
Explanation:
The Email masking method, which exposes the first letter and replaces the domain with XXX.com using a constant string prefix in the form of an email address. -
You have an Azure Databricks workspace named workspace1 in the Standard pricing tier. Workspace1 contains an all-purpose cluster named cluster1.
You need to reduce the time it takes for cluster1 to start and scale up. The solution must minimize costs.
What should you do first?
- Upgrade workspace1 to the Premium pricing tier.
- Configure a global init script for workspace1.
- Create a pool in workspace1.
- Create a cluster policy in workspace1.
Explanation:
You can use Databricks Pools to Speed up your Data Pipelines and Scale Clusters Quickly.
Databricks Pools, a managed cache of virtual machine instances that enables clusters to start and scale 4 times faster. -
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1.
You have files that are ingested and loaded into an Azure Data Lake Storage Gen2 container named container1.
You plan to insert data from the files into Table1 and transform the data. Each row of data in the files will produce one row in the serving layer of Table1.
You need to ensure that when the source data files are loaded to container1, the DateTime is stored as an additional column in Table1.
Solution: In an Azure Synapse Analytics pipeline, you use a Get Metadata activity that retrieves the DateTime of the files.
Does this meet the goal?
- Yes
- No
Explanation:
Instead use a server less SQL pool to create an external table with the extra column. -
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1.
You have files that are ingested and loaded into an Azure Data Lake Storage Gen2 container named container1.
You plan to insert data from the files into Table1 and transform the data. Each row of data in the files will produce one row in the serving layer of Table1.
You need to ensure that when the source data files are loaded to container1, the Date Time is stored as an additional column in Table1.
Solution: You use an Azure Synapse Analytics server less SQL pool to create an external table that has an additional Date Time column.
Does this meet the goal?
- Yes
- No
Explanation:
In dedicated SQL pools you can only use Parquet native external tables. Native external tables are generally available in server less SQL pools. -
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1.
You have files that are ingested and loaded into an Azure Data Lake Storage Gen2 container named container1.
You plan to insert data from the files into Table1 and transform the data. Each row of data in the files will produce one row in the serving layer of Table1.
You need to ensure that when the source data files are loaded to container1, the DateTime is stored as an additional column in Table1.
Solution: You use a dedicated SQL pool to create an external table that has an additional DateTime column.
Does this meet the goal?
- Yes
- No
Explanation:Instead use a server less SQL pool to create an external table with the extra column.
Note: In dedicated SQL pools you can only use Parquet native external tables. Native external tables are generally available in server less SQL pools.
-
HOTSPOT
You are provisioning an Azure SQL database in the Azure portal as shown in the following exhibit.
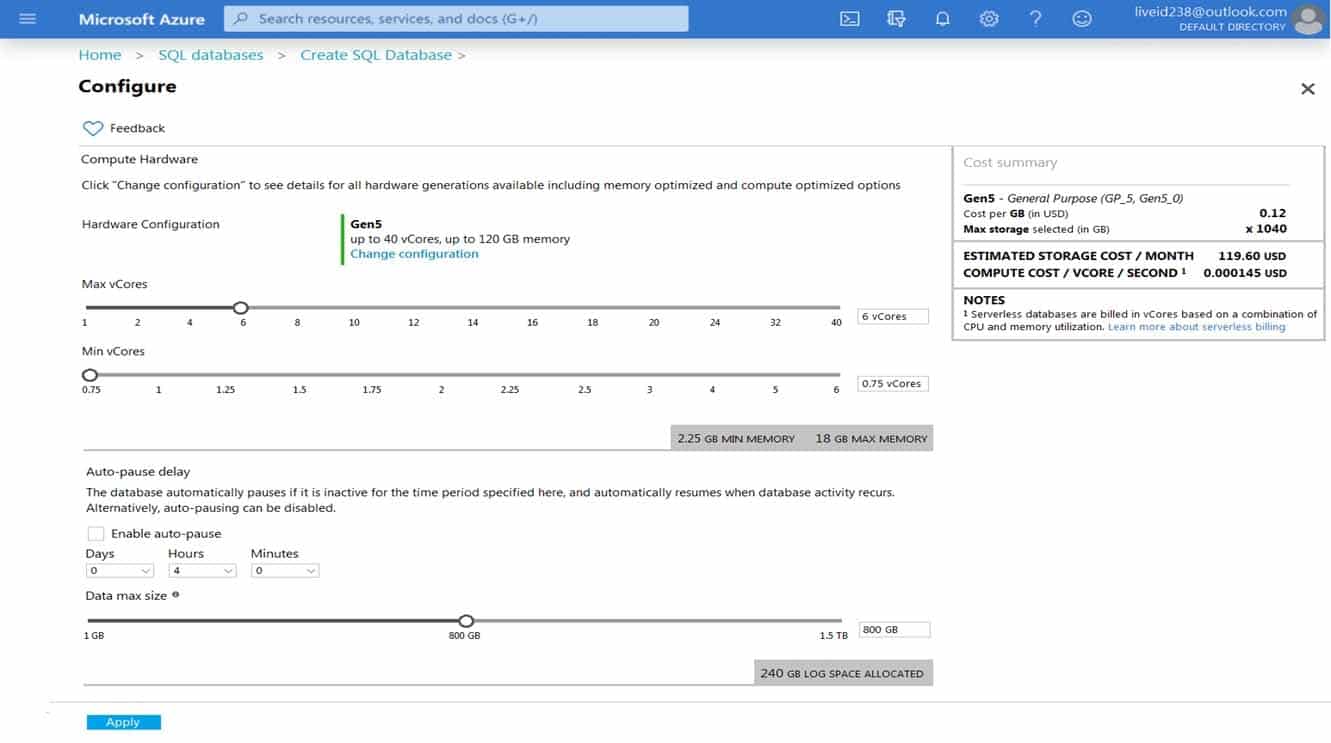
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q11 024 Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q11 025 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q11 025 Answer -
You plan to deploy an app that includes an Azure SQL database and an Azure web app. The app has the following requirements:
– The web app must be hosted on an Azure virtual network.
– The Azure SQL database must be assigned a private IP address.
– The Azure SQL database must allow connections only from a specific virtual network.You need to recommend a solution that meets the requirements.
What should you include in the recommendation?
- Azure Private Link
- a network security group (NSG)
- a database-level firewall
- a server-level firewall
-
You are planning a solution that will use Azure SQL Database. Usage of the solution will peak from October 1 to January 1 each year.
During peak usage, the database will require the following:
– 24 cores
– 500 GB of storage
– 124 GB of memory
– More than 50,000 IOPSDuring periods of off-peak usage, the service tier of Azure SQL Database will be set to Standard.
Which service tier should you use during peak usage?
- Business Critical
- Premium
- Hyperscale
-
HOTSPOT
You have an Azure subscription.
You need to deploy an Azure SQL resource that will support cross database queries by using an Azure Resource Manager (ARM) template.
How should you complete the ARM template? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q14 026 Question 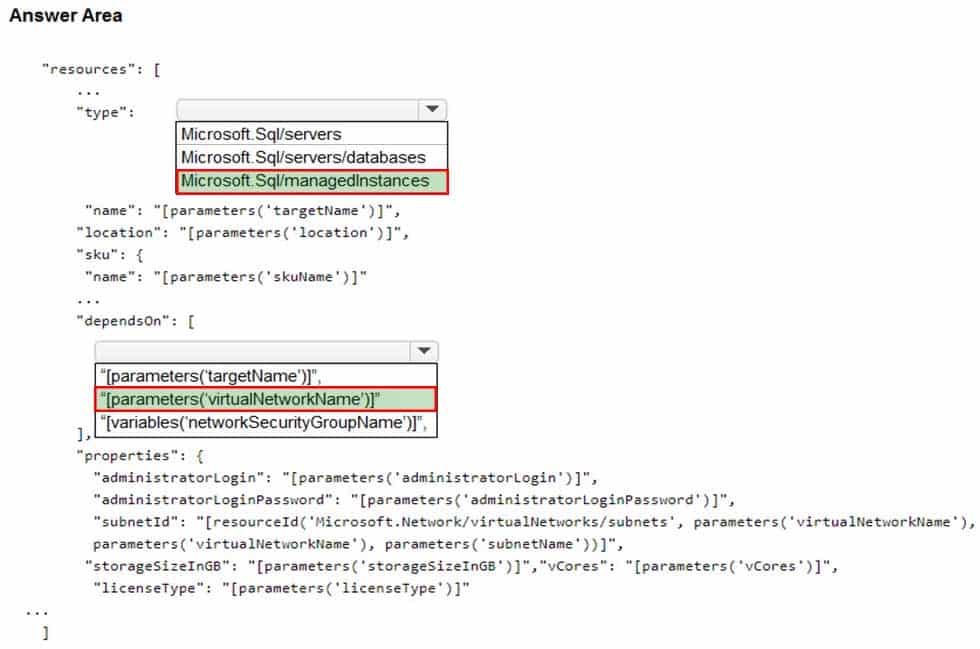
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q14 026 Answer -
HOTSPOT
You have the following Azure Resource Manager template.

DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q15 027 For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q15 028 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q15 028 Answer -
HOTSPOT
You have an on-premises Microsoft SQL Server 2019 instance that hosts a database named DB1.
You plan to perform an online migration of DB1 to an Azure SQL managed instance by using the Azure Database Migration Service.
You need to create a backup of DB1 that is accessible to the Azure Database Migration Service.
What should you run for the backup and where should you store the backup? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
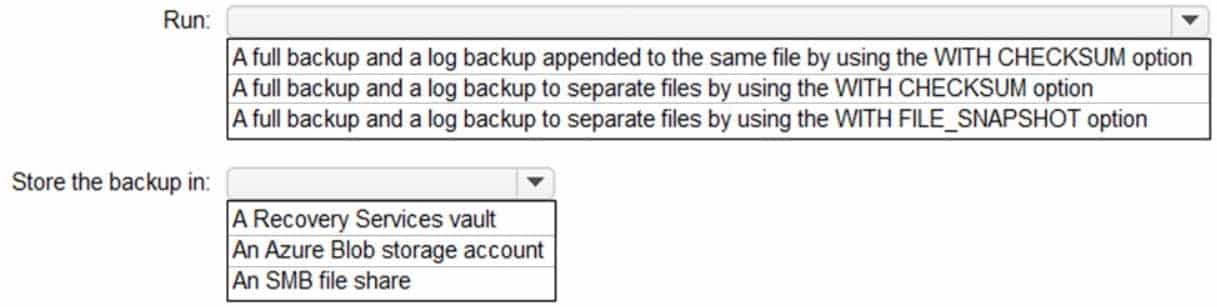
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q16 029 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q16 029 Answer - This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
Litware, Inc. is a renewable energy company that has a main office in Boston. The main office hosts a sales department and the primary datacenter for the company.
Physical Locations
Litware has a manufacturing office and a research office is separate locations near Boston. Each office has its own datacenter and internet connection.
Existing Environment
Network Environment
The manufacturing and research datacenters connect to the primary datacenter by using a VPN.
The primary datacenter has an ExpressRoute connection that uses both Microsoft peering and private peering. The private peering connects to an Azure virtual network named HubVNet.
Identity Environment
Litware has a hybrid Azure Active Directory (Azure AD) deployment that uses a domain named litwareinc.com. All Azure subscriptions are associated to the litwareinc.com Azure AD tenant.
Database Environment
The sales department has the following database workload:
– An on-premises named SERVER1 hosts an instance of Microsoft SQL Server 2012 and two 1-TB databases.
– A logical server named SalesSrv01A contains a geo-replicated Azure SQL database named SalesSQLDb1. SalesSQLDb1 is in an elastic pool named SalesSQLDb1Pool. SalesSQLDb1 uses database firewall rules and contained database users.
– An application named SalesSQLDb1App1 uses SalesSQLDb1.The manufacturing office contains two on-premises SQL Server 2016 servers named SERVER2 and SERVER3. The servers are nodes in the same Always On availability group. The availability group contains a database named ManufacturingSQLDb1
Database administrators have two Azure virtual machines in HubVnet named VM1 and VM2 that run Windows Server 2019 and are used to manage all the Azure databases.
Licensing Agreement
Litware is a Microsoft Volume Licensing customer that has License Mobility through Software Assurance.
Current Problems
SalesSQLDb1 experiences performance issues that are likely due to out-of-date statistics and frequent blocking queries.
Requirements
Planned Changes
Litware plans to implement the following changes:
– Implement 30 new databases in Azure, which will be used by time-sensitive manufacturing apps that have varying usage patterns. Each database will be approximately 20 GB.
– Create a new Azure SQL database named ResearchDB1 on a logical server named ResearchSrv01. ResearchDB1 will contain Personally Identifiable Information (PII) data.
– Develop an app named ResearchApp1 that will be used by the research department to populate and access ResearchDB1.
– Migrate ManufacturingSQLDb1 to the Azure virtual machine platform.
– Migrate the SERVER1 databases to the Azure SQL Database platform.Technical Requirements
Litware identifies the following technical requirements:
– Maintenance tasks must be automated.
– The 30 new databases must scale automatically.
– The use of an on-premises infrastructure must be minimized.
– Azure Hybrid Use Benefits must be leveraged for Azure SQL Database deployments.
– All SQL Server and Azure SQL Database metrics related to CPU and storage usage and limits must be analyzed by using Azure built-in functionality.Security and Compliance Requirements
Litware identifies the following security and compliance requirements:
– Store encryption keys in Azure Key Vault.
– Retain backups of the PII data for two months.
– Encrypt the PII data at rest, in transit, and in use.
– Use the principle of least privilege whenever possible.
– Authenticate database users by using Active Directory credentials.
– Protect Azure SQL Database instances by using database-level firewall rules.
– Ensure that all databases hosted in Azure are accessible from VM1 and VM2 without relying on public endpoints.Business Requirements
Litware identifies the following business requirements:
– Meet an SLA of 99.99% availability for all Azure deployments.
– Minimize downtime during the migration of the SERVER1 databases.
– Use the Azure Hybrid Use Benefits when migrating workloads to Azure.
– Once all requirements are met, minimize costs whenever possible.-
DRAG DROP
You create all of the tables and views for ResearchDB1.
You need to implement security for ResearchDB1. The solution must meet the security and compliance requirements.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
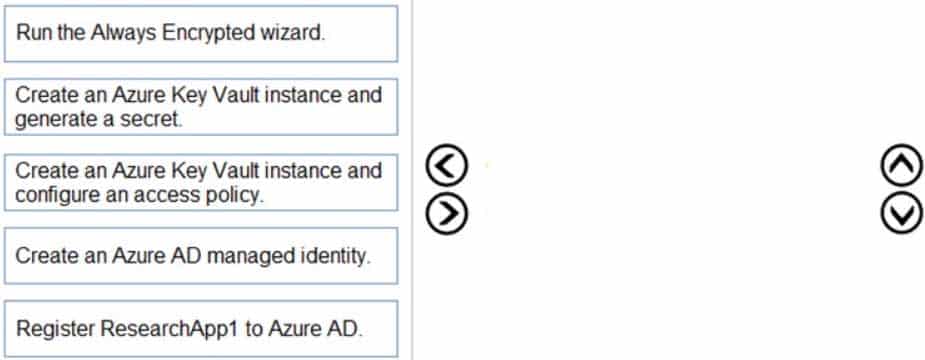
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q17 030 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q17 030 Answer -
DRAG DROP
You need to configure user authentication for the SERVER1 databases. The solution must meet the security and compliance requirements.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q17 031 Question 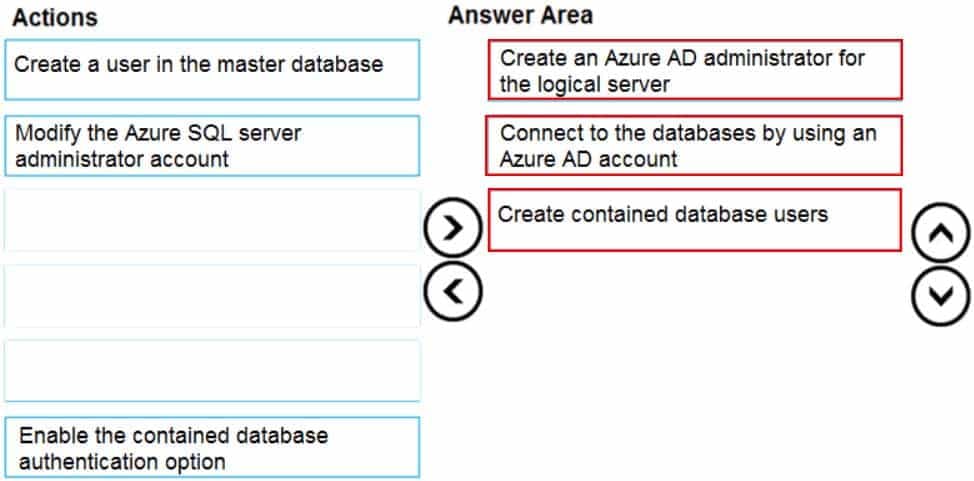
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q17 031 Answer Explanation:Scenario: Authenticate database users by using Active Directory credentials.
The configuration steps include the following procedures to configure and use Azure Active Directory authentication.
1. Create and populate Azure AD.
2. Optional: Associate or change the active directory that is currently associated with your Azure Subscription.
3. Create an Azure Active Directory administrator. (Step 1)
4. Connect to the databases using an Azure AD account (the Administrator account that was configured in the previous step). (Step 2)
5. Create contained database users in your database mapped to Azure AD identities. (Step 3)
-
-
Case study
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
General Overview
Contoso, Ltd. is a financial data company that has 100 employees. The company delivers financial data to customers.
Physical Locations
Contoso has a datacenter in Los Angeles and an Azure subscription. All Azure resources are in the US West 2 Azure region. Contoso has a 10-Gb ExpressRoute connection to Azure.
The company has customers worldwide.
Existing Environment
Active Directory
Contoso has a hybrid Azure Active Directory (Azure AD) deployment that syncs to on-premises Active Directory.
Database Environment
Contoso has SQL Server 2017 on Azure virtual machines shown in the following table.

DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q18 032 SQL1 and SQL2 are in an Always On availability group and are actively queried. SQL3 runs jobs, provides historical data, and handles the delivery of data to customers.
The on-premises datacenter contains a PostgreSQL server that has a 50-TB database.
Current Business Model
Contoso uses Microsoft SQL Server Integration Services (SSIS) to create flat files for customers. The customers receive the files by using FTP.
Requirements
Planned Changes
Contoso plans to move to a model in which they deliver data to customer databases that run as platform as a service (PaaS) offerings. When a customer establishes a service agreement with Contoso, a separate resource group that contains an Azure SQL database will be provisioned for the customer. The database will have a complete copy of the financial data. The data to which each customer will have access will depend on the service agreement tier. The customers can change tiers by changing their service agreement.
The estimated size of each PaaS database is 1 TB.
Contoso plans to implement the following changes:
– Move the PostgreSQL database to Azure Database for PostgreSQL during the next six months.
– Upgrade SQL1, SQL2, and SQL3 to SQL Server 2019 during the next few months.
– Start onboarding customers to the new PaaS solution within six months.Business Goals
Contoso identifies the following business requirements:
– Use built-in Azure features whenever possible.
– Minimize development effort whenever possible.
– Minimize the compute costs of the PaaS solutions.
– Provide all the customers with their own copy of the database by using the PaaS solution.
– Provide the customers with different table and row access based on the customer’s service agreement.
– In the event of an Azure regional outage, ensure that the customers can access the PaaS solution with minimal downtime. The solution must provide automatic failover.
– Ensure that users of the PaaS solution can create their own database objects but be prevented from modifying any of the existing database objects supplied by Contoso.Technical Requirements
Contoso identifies the following technical requirements:
– Users of the PaaS solution must be able to sign in by using their own corporate Azure AD credentials or have Azure AD credentials supplied to them by Contoso. The solution must avoid using the internal Azure AD of Contoso to minimize guest users.
– All customers must have their own resource group, Azure SQL server, and Azure SQL database. The deployment of resources for each customer must be done in a consistent fashion.
– Users must be able to review the queries issued against the PaaS databases and identify any new objects created.
– Downtime during the PostgreSQL database migration must be minimized.Monitoring Requirements
Contoso identifies the following monitoring requirements:
– Notify administrators when a PaaS database has a higher than average CPU usage.
– Use a single dashboard to review security and audit data for all the PaaS databases.
– Use a single dashboard to monitor query performance and bottlenecks across all the PaaS databases.
– Monitor the PaaS databases to identify poorly performing queries and resolve query performance issues automatically whenever possible.PaaS Prototype
During prototyping of the PaaS solution in Azure, you record the compute utilization of a customer’s Azure SQL database as shown in the following exhibit.
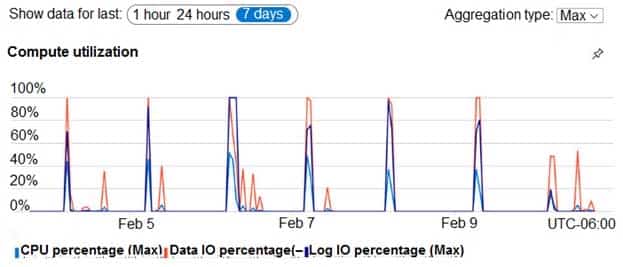
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q18 033 Role Assignments
For each customer’s Azure SQL Database server, you plan to assign the roles shown in the following exhibit.
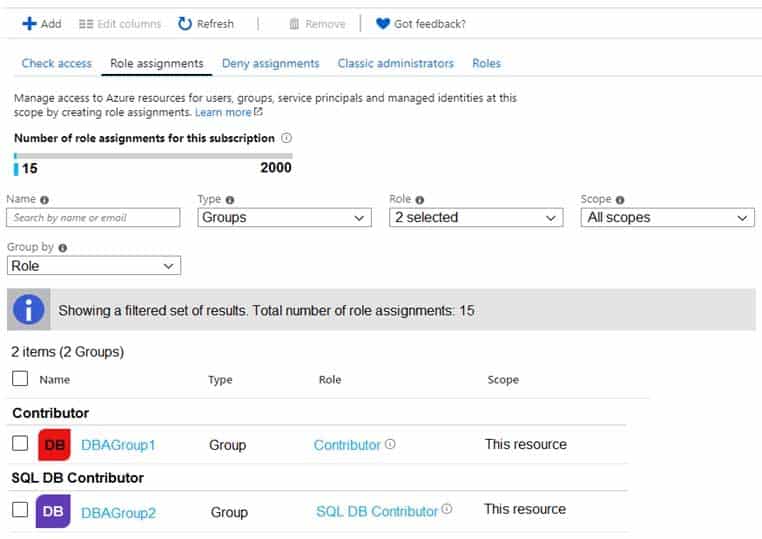
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q18 034 -
HOTSPOT
You are evaluating the role assignments.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q18 035 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q18 035 Answer Explanation:Box 1: Yes
DBAGroup1 is member of the Contributor role.
The Contributor role grants full access to manage all resources, but does not allow you to assign roles in Azure RBAC, manage assignments in Azure Blueprints, or share image galleries.Box 2: No
Box 3: Yes
DBAGroup2 is member of the SQL DB Contributor role.
The SQL DB Contributor role lets you manage SQL databases, but not access to them. Also, you can’t manage their security-related policies or their parent SQL servers. As a member of this role you can create and manage SQL databases. -
You need to recommend a solution to ensure that the customers can create the database objects. The solution must meet the business goals.
What should you include in the recommendation?
- For each customer, grant the customer ddl_admin to the existing schema.
- For each customer, create an additional schema and grant the customer ddl_admin to the new schema.
- For each customer, create an additional schema and grant the customer db_writer to the new schema.
- For each customer, grant the customer db_writer to the existing schema.
-
You are evaluating the business goals.
Which feature should you use to provide customers with the required level of access based on their service agreement?
- dynamic data masking
- Conditional Access in Azure
- service principals
- row-level security (RLS)
-
-
You have a new Azure SQL database. The database contains a column that stores confidential information.
You need to track each time values from the column are returned in a query. The tracking information must be stored for 365 days from the date the query was executed.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- Turn on auditing and write audit logs to an Azure Storage account.
- Add extended properties to the column.
- Turn on auditing and write audit logs to an Event Hub
- Apply sensitivity labels named Highly Confidential to the column.
- Turn on Azure Defender for SQL
Explanation:D: You can apply sensitivity-classification labels persistently to columns by using new metadata attributes that have been added to the SQL Server database engine. This metadata can then be used for advanced, sensitivity-based auditing and protection scenarios.
A: An important aspect of the information-protection paradigm is the ability to monitor access to sensitive data. Azure SQL Auditing has been enhanced to include a new field in the audit log called data_sensitivity_information. This field logs the sensitivity classifications (labels) of the data that was returned by a query. Here’s an example:

DP-300 Administering Relational Databases on Microsoft Azure Part 02 Q19 036 -
You have an Azure virtual machine named VM1 on a virtual network named VNet1. Outbound traffic from VM1 to the internet is blocked.
You have an Azure SQL database named SqlDb1 on a logical server named SqlSrv1.
You need to implement connectivity between VM1 and SqlDb1 to meet the following requirements:
– Ensure that all traffic to the public endpoint of SqlSrv1 is blocked.
– Minimize the possibility of VM1 exfiltrating data stored in SqlDb1.What should you create on VNet1?
- a VPN gateway
- a service endpoint
- a private link
- an ExpressRoute gateway
Explanation:Azure Private Link enables you to access Azure PaaS Services (for example, Azure Storage and SQL Database) and Azure hosted customer-owned/partner services over a private endpoint in your virtual network.
Traffic between your virtual network and the service travels the Microsoft backbone network. Exposing your service to the public internet is no longer necessary.