DP-300 : Administering Relational Databases on Microsoft Azure : Part 07
DP-300 : Administering Relational Databases on Microsoft Azure : Part 07
-
You need to trigger an Azure Data Factory pipeline when a file arrives in an Azure Data Lake Storage Gen2 container.
Which resource provider should you enable?
- Microsoft.EventHub
- Microsoft.EventGrid
- Microsoft.Sql
- Microsoft.Automation
Explanation:
Event-driven architecture (EDA) is a common data integration pattern that involves production, detection, consumption, and reaction to events. Data integration scenarios often require Data Factory customers to trigger pipelines based on events happening in storage account, such as the arrival or deletion of a file in Azure Blob Storage account. Data Factory natively integrates with Azure Event Grid, which lets you trigger pipelines on such events. -
HOTSPOT
You have an Azure Data Factory instance named ADF1 and two Azure Synapse Analytics workspaces named WS1 and WS2.
ADF1 contains the following pipelines:
– P1:Uses a copy activity to copy data from a nonpartitioned table in a dedicated SQL pool of WS1 to an Azure Data Lake Storage Gen2 account
– P2:Uses a copy activity to copy data from text-delimited files in an Azure Data Lake Storage Gen2 account to a nonpartitioned table in a dedicated SQL pool of WS2You need to configure P1 and P2 to maximize parallelism and performance.
Which dataset settings should you configure for the copy activity of each pipeline? To answer, select the appropriate options in the answer area.

DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q02 081 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q02 081 Answer Explanation:P1: Set the Partition option to Dynamic Range.
The SQL Server connector in copy activity provides built-in data partitioning to copy data in parallel.P2: Set the Copy method to PolyBase
Polybase is the most efficient way to move data into Azure Synapse Analytics. Use the staging blob feature to achieve high load speeds from all types of data stores, including Azure Blob storage and Data Lake Store. (Polybase supports Azure Blob storage and Azure Data Lake Store by default.) -
You have the following Azure Data Factory pipelines:
– Ingest Data from System1
– Ingest Data from System2
– Populate Dimensions
– Populate FactsIngest Data from System1 and Ingest Data from System2 have no dependencies. Populate Dimensions must execute after Ingest Data from System1 and Ingest Data from System2. Populate Facts must execute after the Populate Dimensions pipeline. All the pipelines must execute every eight hours.
What should you do to schedule the pipelines for execution?
- Add a schedule trigger to all four pipelines.
- Add an event trigger to all four pipelines.
- Create a parent pipeline that contains the four pipelines and use an event trigger.
- Create a parent pipeline that contains the four pipelines and use a schedule trigger.
-
You have an Azure Data Factory pipeline that performs an incremental load of source data to an Azure Data Lake Storage Gen2 account.
Data to be loaded is identified by a column named LastUpdatedDate in the source table.
You plan to execute the pipeline every four hours.
You need to ensure that the pipeline execution meets the following requirements:
– Automatically retries the execution when the pipeline run fails due to concurrency or throttling limits.
– Supports backfilling existing data in the table.Which type of trigger should you use?
- tumbling window
- on-demand
- event
- schedule
Explanation:The Tumbling window trigger supports backfill scenarios. Pipeline runs can be scheduled for windows in the past.
Incorrect Answers:
D: Schedule trigger does not support backfill scenarios. Pipeline runs can be executed only on time periods from the current time and the future. -
You have an Azure Data Factory that contains 10 pipelines.
You need to label each pipeline with its main purpose of either ingest, transform, or load. The labels must be available for grouping and filtering when using the monitoring experience in Data Factory.
What should you add to each pipeline?
- an annotation
- a resource tag
- a run group ID
- a user property
- a correlation ID
Explanation:
Azure Data Factory annotations help you easily filter different Azure Data Factory objects based on a tag. You can define tags so you can see their performance or find errors faster. -
HOTSPOT
You have an Azure data factory that has two pipelines named PipelineA and PipelineB.
PipelineA has four activities as shown in the following exhibit.

DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q06 082 PipelineB has two activities as shown in the following exhibit.

DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q06 083 You create an alert for the data factory that uses Failed pipeline runs metrics for both pipelines and all failure types. The metric has the following settings:
– Operator: Greater than
– Aggregation type: Total
– Threshold value: 2
– Aggregation granularity (Period): 5 minutes
– Frequency of evaluation: Every 5 minutesData Factory monitoring records the failures shown in the following table.
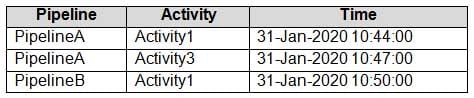
DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q06 084 For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q06 085 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q06 085 Answer Explanation:Box 1: No
Just one failure within the 5-minute interval.Box 2: No
Just two failures within the 5-minute interval.Box 3: No
Just two failures within the 5-minute interval. -
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes mapping data flow, and then inserts the data into the data warehouse.
Does this meet the goal?
- Yes
- No
Explanation:
If you need to transform data in a way that is not supported by Data Factory, you can create a custom activity, not a mapping flow,5 with your own data processing logic and use the activity in the pipeline. You can create a custom activity to run R scripts on your HDInsight cluster with R installed. -
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You schedule an Azure Databricks job that executes an R notebook, and then inserts the data into the data warehouse.
Does this meet the goal?
- Yes
- No
Explanation:
Must use an Azure Data Factory, not an Azure Databricks job. -
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes an Azure Databricks notebook, and then inserts the data into the data warehouse.
Does this meet the goal?
- Yes
- No
Explanation:
If you need to transform data in a way that is not supported by Data Factory, you can create a custom activity, not an Azure Databricks notebook, with your own data processing logic and use the activity in the pipeline. You can create a custom activity to run R scripts on your HDInsight cluster with R installed. -
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that copies the data to a staging table in the data warehouse, and then uses a stored procedure to execute the R script.
Does this meet the goal?
- Yes
- No
Explanation:
If you need to transform data in a way that is not supported by Data Factory, you can create a custom activity with your own data processing logic and use the activity in the pipeline. You can create a custom activity to run R scripts on your HDInsight cluster with R installed. -
DRAG DROP
You have an Azure subscription that contains an Azure SQL managed instance named SQLMi1 and a SQL Agent job named Backupdb. Backupdb performs a daily backup of the databases hosted on SQLMi1.
You need to be notified by email if the job fails.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q11 086 Question 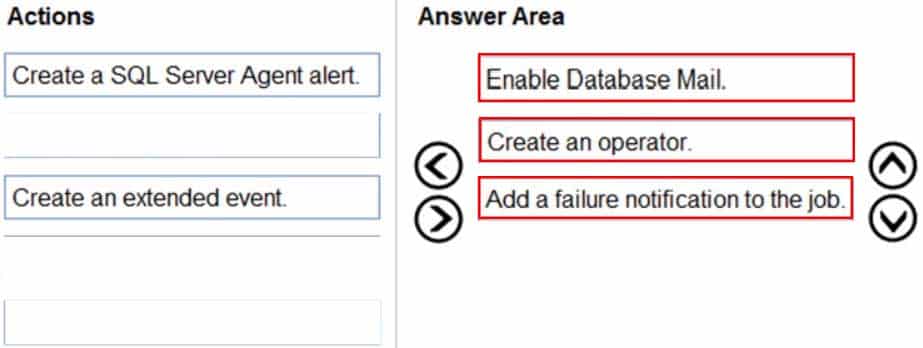
DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q11 086 Answer -
DRAG DROP
You have SQL Server on an Azure virtual machine.
You need to use Policy-Based Management in Microsoft SQL Server to identify stored procedures that do not comply with your naming conventions.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q12 087 Question 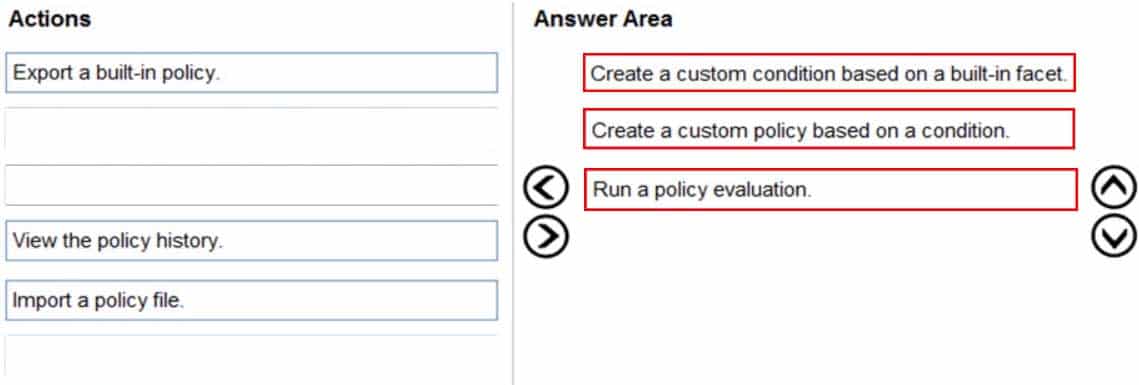
DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q12 087 Answer -
You have an Azure SQL managed instance named SQLMI1 that hosts 10 databases.
You need to implement alerts by using Azure Monitor. The solution must meet the following requirements:
– Minimize costs.
– Aggregate Intelligent Insights telemetry from each database.What should you do?
- From the Diagnostic settings of each database, select Send to Log Analytics.
- From the Diagnostic settings of each database, select Stream to an event hub.
- From the Diagnostic settings of SQLMI1, select Send to Log Analytics.
- From the Diagnostic settings of SQLMI1, select Stream to an event hub.
-
You have an Azure SQL managed instance that hosts multiple databases.
You need to configure alerts for each database based on the diagnostics telemetry of the database.
What should you use?
- Azure SQL Analytics alerts based on metrics
- SQL Health Check alerts based on diagnostics logs
- SQL Health Check alerts based on metrics
- Azure SQL Analytics alerts based on diagnostics logs
- This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
Litware, Inc. is a renewable energy company that has a main office in Boston. The main office hosts a sales department and the primary datacenter for the company.
Physical Locations
Litware has a manufacturing office and a research office is separate locations near Boston. Each office has its own datacenter and internet connection.
Existing Environment
Network Environment
The manufacturing and research datacenters connect to the primary datacenter by using a VPN.
The primary datacenter has an ExpressRoute connection that uses both Microsoft peering and private peering. The private peering connects to an Azure virtual network named HubVNet.
Identity Environment
Litware has a hybrid Azure Active Directory (Azure AD) deployment that uses a domain named litwareinc.com. All Azure subscriptions are associated to the litwareinc.com Azure AD tenant.
Database Environment
The sales department has the following database workload:
– An on-premises named SERVER1 hosts an instance of Microsoft SQL Server 2012 and two 1-TB databases.
– A logical server named SalesSrv01A contains a geo-replicated Azure SQL database named SalesSQLDb1. SalesSQLDb1 is in an elastic pool named SalesSQLDb1Pool. SalesSQLDb1 uses database firewall rules and contained database users.
– An application named SalesSQLDb1App1 uses SalesSQLDb1.The manufacturing office contains two on-premises SQL Server 2016 servers named SERVER2 and SERVER3. The servers are nodes in the same Always On availability group. The availability group contains a database named ManufacturingSQLDb1
Database administrators have two Azure virtual machines in HubVnet named VM1 and VM2 that run Windows Server 2019 and are used to manage all the Azure databases.
Licensing Agreement
Litware is a Microsoft Volume Licensing customer that has License Mobility through Software Assurance.
Current Problems
SalesSQLDb1 experiences performance issues that are likely due to out-of-date statistics and frequent blocking queries.
Requirements
Planned Changes
Litware plans to implement the following changes:
– Implement 30 new databases in Azure, which will be used by time-sensitive manufacturing apps that have varying usage patterns. Each database will be approximately 20 GB.
– Create a new Azure SQL database named ResearchDB1 on a logical server named ResearchSrv01. ResearchDB1 will contain Personally Identifiable Information (PII) data.
– Develop an app named ResearchApp1 that will be used by the research department to populate and access ResearchDB1.
– Migrate ManufacturingSQLDb1 to the Azure virtual machine platform.
– Migrate the SERVER1 databases to the Azure SQL Database platform.Technical Requirements
Litware identifies the following technical requirements:
– Maintenance tasks must be automated.
– The 30 new databases must scale automatically.
– The use of an on-premises infrastructure must be minimized.
– Azure Hybrid Use Benefits must be leveraged for Azure SQL Database deployments.
– All SQL Server and Azure SQL Database metrics related to CPU and storage usage and limits must be analyzed by using Azure built-in functionality.Security and Compliance Requirements
Litware identifies the following security and compliance requirements:
– Store encryption keys in Azure Key Vault.
– Retain backups of the PII data for two months.
– Encrypt the PII data at rest, in transit, and in use.
– Use the principle of least privilege whenever possible.
– Authenticate database users by using Active Directory credentials.
– Protect Azure SQL Database instances by using database-level firewall rules.
– Ensure that all databases hosted in Azure are accessible from VM1 and VM2 without relying on public endpoints.Business Requirements
Litware identifies the following business requirements:
– Meet an SLA of 99.99% availability for all Azure deployments.
– Minimize downtime during the migration of the SERVER1 databases.
– Use the Azure Hybrid Use Benefits when migrating workloads to Azure.
– Once all requirements are met, minimize costs whenever possible.-
You need to provide an implementation plan to configure data retention for ResearchDB1. The solution must meet the security and compliance requirements.
What should you include in the plan?
- Configure the Deleted databases settings for ResearchSrv01.
- Deploy and configure an Azure Backup server.
- Configure the Advanced Data Security settings for ResearchDB1.
- Configure the Manage Backups settings for ResearchSrv01.
-
HOTSPOT
You need to recommend a configuration for ManufacturingSQLDb1 after the migration to Azure. The solution must meet the business requirements.
What should you include in the recommendation? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q15 088 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q15 088 Answer Explanation:Box 1: Node majority with witness
As a general rule when you configure a quorum, the voting elements in the cluster should be an odd number. Therefore, if the cluster contains an even number of voting nodes, you should configure a disk witness or a file share witness.Note: Mode: Node majority with witness (disk or file share)
Nodes have votes. In addition, a quorum witness has a vote. The cluster quorum is the majority of voting nodes in the active cluster membership plus a witness vote. A quorum witness can be a designated disk witness or a designated file share witness.Box 2: Azure Standard Load Balancer
Microsoft guarantees that a Load Balanced Endpoint using Azure Standard Load Balancer, serving two or more Healthy Virtual Machine Instances, will be available 99.99% of the time.Scenario: Business Requirements
Litware identifies business requirements include: meet an SLA of 99.99% availability for all Azure deployments.Incorrect Answers:
Basic Balancer: No SLA is provided for Basic Load Balancer.Note: There are two main options for setting up your listener: external (public) or internal. The external (public) listener uses an internet facing load balancer and is associated with a public Virtual IP (VIP) that is accessible over the internet. An internal listener uses an internal load balancer and only supports clients within the same Virtual Network.
-
What should you do after a failover of SalesSQLDb1 to ensure that the database remains accessible to SalesSQLDb1App1?
- Configure SalesSQLDb1 as writable.
- Update the connection strings of SalesSQLDb1App1.
- Update the firewall rules of SalesSQLDb1.
- Update the users in SalesSQLDb1.
Explanation:
Scenario: SalesSQLDb1 uses database firewall rules and contained database users.
-
-
Case study
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
General Overview
Contoso, Ltd. is a financial data company that has 100 employees. The company delivers financial data to customers.
Physical Locations
Contoso has a datacenter in Los Angeles and an Azure subscription. All Azure resources are in the US West 2 Azure region. Contoso has a 10-Gb ExpressRoute connection to Azure.
The company has customers worldwide.
Existing Environment
Active Directory
Contoso has a hybrid Azure Active Directory (Azure AD) deployment that syncs to on-premises Active Directory.
Database Environment
Contoso has SQL Server 2017 on Azure virtual machines shown in the following table.

DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q16 089 SQL1 and SQL2 are in an Always On availability group and are actively queried. SQL3 runs jobs, provides historical data, and handles the delivery of data to customers.
The on-premises datacenter contains a PostgreSQL server that has a 50-TB database.
Current Business Model
Contoso uses Microsoft SQL Server Integration Services (SSIS) to create flat files for customers. The customers receive the files by using FTP.
Requirements
Planned Changes
Contoso plans to move to a model in which they deliver data to customer databases that run as platform as a service (PaaS) offerings. When a customer establishes a service agreement with Contoso, a separate resource group that contains an Azure SQL database will be provisioned for the customer. The database will have a complete copy of the financial data. The data to which each customer will have access will depend on the service agreement tier. The customers can change tiers by changing their service agreement.
The estimated size of each PaaS database is 1 TB.
Contoso plans to implement the following changes:
– Move the PostgreSQL database to Azure Database for PostgreSQL during the next six months.
– Upgrade SQL1, SQL2, and SQL3 to SQL Server 2019 during the next few months.
– Start onboarding customers to the new PaaS solution within six months.Business Goals
Contoso identifies the following business requirements:
– Use built-in Azure features whenever possible.
– Minimize development effort whenever possible.
– Minimize the compute costs of the PaaS solutions.
– Provide all the customers with their own copy of the database by using the PaaS solution.
– Provide the customers with different table and row access based on the customer’s service agreement.
– In the event of an Azure regional outage, ensure that the customers can access the PaaS solution with minimal downtime. The solution must provide automatic failover.
– Ensure that users of the PaaS solution can create their own database objects but be prevented from modifying any of the existing database objects supplied by Contoso.Technical Requirements
Contoso identifies the following technical requirements:
– Users of the PaaS solution must be able to sign in by using their own corporate Azure AD credentials or have Azure AD credentials supplied to them by Contoso. The solution must avoid using the internal Azure AD of Contoso to minimize guest users.
– All customers must have their own resource group, Azure SQL server, and Azure SQL database. The deployment of resources for each customer must be done in a consistent fashion.
– Users must be able to review the queries issued against the PaaS databases and identify any new objects created.
– Downtime during the PostgreSQL database migration must be minimized.Monitoring Requirements
Contoso identifies the following monitoring requirements:
– Notify administrators when a PaaS database has a higher than average CPU usage.
– Use a single dashboard to review security and audit data for all the PaaS databases.
– Use a single dashboard to monitor query performance and bottlenecks across all the PaaS databases.
– Monitor the PaaS databases to identify poorly performing queries and resolve query performance issues automatically whenever possible.PaaS Prototype
During prototyping of the PaaS solution in Azure, you record the compute utilization of a customer’s Azure SQL database as shown in the following exhibit.
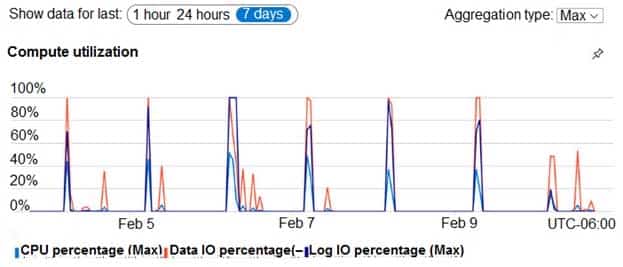
DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q16 090 Role Assignments
For each customer’s Azure SQL Database server, you plan to assign the roles shown in the following exhibit.
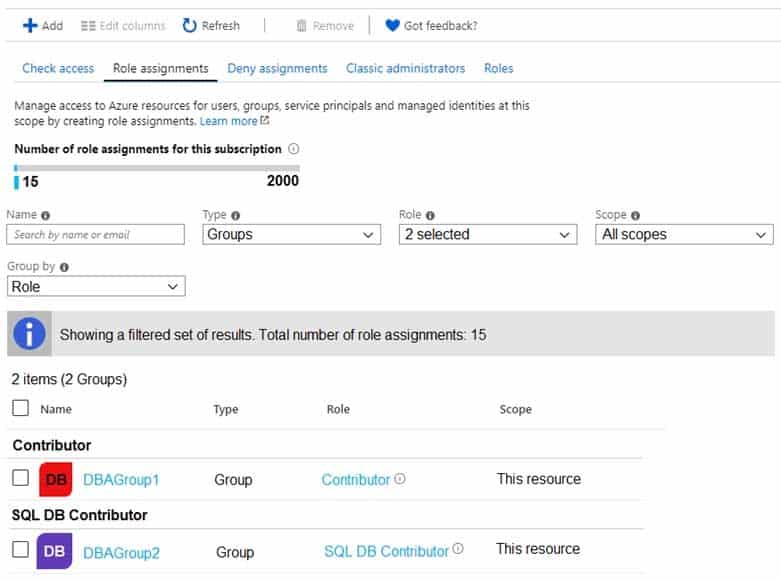
DP-300 Administering Relational Databases on Microsoft Azure Part 07 Q16 091 -
What should you implement to meet the disaster recovery requirements for the PaaS solution?
- Availability Zones
- failover groups
- Always On availability groups
- geo-replication
Explanation:Scenario: In the event of an Azure regional outage, ensure that the customers can access the PaaS solution with minimal downtime. The solution must provide automatic failover.
The auto-failover groups feature allows you to manage the replication and failover of a group of databases on a server or all databases in a managed instance to another region. It is a declarative abstraction on top of the existing active geo-replication feature, designed to simplify deployment and management of geo-replicated databases at scale. You can initiate failover manually or you can delegate it to the Azure service based on a user-defined policy.
The latter option allows you to automatically recover multiple related databases in a secondary region after a catastrophic failure or other unplanned event that results in full or partial loss of the SQL Database or SQL Managed Instance availability in the primary region.
-
-
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have two Azure SQL Database servers named Server1 and Server2. Each server contains an Azure SQL database named Database1.
You need to restore Database1 from Server1 to Server2. The solution must replace the existing Database1 on Server2.
Solution: From the Azure portal, you delete Database1 from Server2, and then you create a new database on Server2 by using the backup of Database1 from Server1.
Does this meet the goal?
- Yes
- No
Explanation:Instead restore Database1 from Server1 to the Server2 by using the RESTORE Transact-SQL command and the REPLACE option.
Note: REPLACE should be used rarely and only after careful consideration. Restore normally prevents accidentally overwriting a database with a different database. If the database specified in a RESTORE statement already exists on the current server and the specified database family GUID differs from the database family GUID recorded in the backup set, the database is not restored. This is an important safeguard.
-
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have two Azure SQL Database servers named Server1 and Server2. Each server contains an Azure SQL database named Database1.
You need to restore Database1 from Server1 to Server2. The solution must replace the existing Database1 on Server2.
Solution: You run the Remove-AzSqlDatabase PowerShell cmdlet for Database1 on Server2. You run the Restore-AzSqlDatabase PowerShell cmdlet for Database1 on Server2.
Does this meet the goal?
- Yes
- No
Explanation:Instead restore Database1 from Server1 to the Server2 by using the RESTORE Transact-SQL command and the REPLACE option.
Note: REPLACE should be used rarely and only after careful consideration. Restore normally prevents accidentally overwriting a database with a different database. If the database specified in a RESTORE statement already exists on the current server and the specified database family GUID differs from the database family GUID recorded in the backup set, the database is not restored. This is an important safeguard.
-
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have two Azure SQL Database servers named Server1 and Server2. Each server contains an Azure SQL database named Database1.
You need to restore Database1 from Server1 to Server2. The solution must replace the existing Database1 on Server2.
Solution: You restore Database1 from Server1 to the Server2 by using the RESTORE Transact-SQL command and the REPLACE option.
Does this meet the goal?
- Yes
- No
Explanation:The REPLACE option overrides several important safety checks that restore normally performs. The overridden checks are as follows:
– Restoring over an existing database with a backup taken of another database.With the REPLACE option, restore allows you to overwrite an existing database with whatever database is in the backup set, even if the specified database name differs from the database name recorded in the backup set. This can result in accidentally overwriting a database by a different database.
-
You have an Always On availability group deployed to Azure virtual machines. The availability group contains a database named DB1 and has two nodes named SQL1 and SQL2. SQL1 is the primary replica.
You need to initiate a full backup of DB1 on SQL2.
Which statement should you run?
-
BACKUP DATABASE DB1 TO URL='https://mystorageaccount.blob.core.windows.net/mycontainer/DB1.bak' with (Differential, STATS=5, COMPRESSION);
-
BACKUP DATABASE DB1 TO URL='https://mystorageaccount.blob.core.windows.net/mycontainer/DB1.bak' with (COPY_ONLY, STATS=5, COMPRESSION); -
BACKUP DATABASE DB1 TO URL='https://mystorageaccount.blob.core.windows.net/mycontainer/DB1.bak' with (File_Snapshot, STATS=5, COMPRESSION);
-
BACKUP DATABASE DB1 TO URL='https://mystorageaccount.blob.core.windows.net/mycontainer/DB1.bak' with (NoInit, STATS=5, COMPRESSION);
Explanation:BACKUP DATABASE supports only copy-only full backups of databases, files, or filegroups when it’s executed on secondary replicas. Copy-only backups don’t impact the log chain or clear the differential bitmap.
Incorrect Answers:
A: Differential backups are not supported on secondary replicas. The software displays this error because the secondary replicas support copy-only database backups. -