350-401 : Implementing Cisco Enterprise Network Core Technologies (ENCOR) : Part 02
-
Which of the following commands can you issue to enable RSTP? (Select 2 choices.)
- spanning-tree mode mst
- spanning-tree mode pvst
- spanning-tree mode rapid-pvst
- no spanning-tree mode
Explanation:
You can issue the spanning-tree mode mst command or the spanning-tree mode rapid-pvst command to enable Rapid Spanning Tree Protocol (RSTP). RSTP, which is defined in the Institute of Electrical and Electronics Engineers (IEEE) 802.1w standard, is used to improve the slow transition of a Spanning Tree Protocol (STP) port to the forwarding state, thereby increasing convergence speed. A switch port will pass through the following RSTP states:
– Discarding
– Learning
– ForwardingWhen RSTP is enabled on a switch port, the port first enters the discarding state, in which a port receives bridge protocol data units (BPDUs) and directs them to the system module, however, the port neither sends BPDUs nor forwards any frames. The switch port then transitions to the learning state, in which it begins to transmit BPDUs and learn addressing information. Finally, a switch port transitions to the forwarding state, in which the switch port forwards frames. If a switch port determines at any time during the RSTP state process that a switching loop would be caused by entering the forwarding state, the switch port again enters the discarding state, in which the switch receives BPDUs and directs them to the system module but does not send BPDUs or forward frames.
The spanning-tree mode mst command enables Multiple Spanning Tree (MST), which uses RSTP. MST, which is defined in the IEEE 802.1s standard, is used to enable multiple spanning trees for groups of one or more virtual LANs (VLANs).
The spanning-tree mode pvst command enables PerVLAN Spanning Tree Plus (PVST+), which uses STP, not RSTP. PVST+, which is defined in the IEEE 802.1D standard, creates a separate spanning tree instance for each VLAN and can be used with 802.1Q encapsulation. By contrast, PVST can only be used with InterSwitch Link (ISL).
The spanning-tree mode rapid-pvst command enables RapidPVST+, which uses RSTP. RapidPVST+, which is defined in the IEEE 802.1w standard, combines the rapid transition of ports by RSTP with the creation of spanning trees for each VLAN by PVST+.
The no spanning-tree mode command is not used to enable RSTP. Rather, it is used to configure a switch with the default switch mode, PVST+. -
You issue the ip as-path access-list 1 permit ^7_23$ command on a BGP router.
Which of the following paths are allowed by the AS path filter? (Select the best answer.)
- paths that originate from AS 7 or AS 23
- paths that pass through AS 7 or AS 23
- paths that originate from AS 7 and are learned from AS 23
- paths that are learned from AS 7 and originate from AS 23
Explanation:
Paths that are learned from Border Gateway Protocol (BGP) autonomous system (AS) 7 and originate from AS 23 are allowed by the AS path filter. Regular expressions are used to locate character strings that match a particular pattern.
The caret (^) character indicates that the subsequent characters should match the start of the string. Each router in the path prepends its AS number to the beginning of the AS path; therefore, the first AS number in the AS path is the AS from which the path is learned. Therefore, the ip aspath accesslist 1 permit ^7_23$ command allows paths that are learned from AS 7.The dollar sign ($) character indicates that the preceding characters should match the end of the string. The originating router will insert its AS number into the AS path, and subsequent routers will prepend their AS numbers to the beginning of the AS path string. The last AS number in the AS path is the originating AS; therefore, the ip aspath accesslist 1 permit ^7_23$ command allows paths that originate from AS 23.
The underscore (_) character is used to indicate a comma, a brace, the start or end of an input string, or a space. When used between two AS path numbers, the _ character indicates that the ASes are directly connected. Therefore, the ip aspath accesslist 1 permit ^7_23$ command indicates that AS 7 is directly connected to AS 23.
The ip aspath accesslist 1 permit ^7_23$ command does not permit paths that originate from AS 7 and are learned from AS 23. To configure an AS path filter that permits paths that originate from AS 7 and are learned from AS 23, you could issue the ip aspath accesslist 1 permit ^23_7$ command.
The ip aspath accesslist 1 permit ^7_23$ command does not permit paths that originate from AS 7 or AS 23; it only permits paths that originate from AS 23. To configure an AS path filter that permits paths that originate from AS 7 or AS 23, you could issue the following command set:
ip aspath accesslist 1 permit _7$
ip aspath accesslist 1 permit _23$The ip aspath accesslist 1 permit ^7_23$ command does not permit paths that pass through AS 7 or AS 23. To configure an AS path filter that permits paths that pass through AS 7 or AS 23, you could issue the following command set:
ip aspath accesslist 1 permit _7_
ip aspath accesslist 1 permit _23_ -
Switch1 and Switch2 are configured as a VSS. Switch1 has a higher priority. Switch2 has a higher switch ID. Both switches are started simultaneously. Which of the following will occur if RRP discovers an incompatibility between the switches? (Select the best answer.)
- Both switches will come up in RPR mode.
- Both switches will come up in NSF/SSO mode.
- Switch1 will come up in NSF/SSO mode, and Switch2 will come up in RPR mode.
- Switch2 will come up in NSF/SSO mode, and Switch1 will come up in RPR mode.
Explanation:
Switch1 will come up in Nonstop Forwarding/Stateful Switchover (NSF/SSO) mode, and Switch2 will come up in routeprocessor redundancy (RPR) mode. Virtual Switching System (VSS) combines two physical Cisco Catalyst switches into a single virtual switch with a unified control plane, which can result in greater network efficiency and bandwidth capacity. One switch chassis becomes the active virtual switch, and the other switch becomes the standby virtual switch. The switch chassis are connected together by a virtual switch link (VSL), which is implemented as an EtherChannel of up to eight physical interfaces. The standby chassis will monitor the VSL to ensure that the active chassis remains functional.
Configuration, monitoring, and troubleshooting must be performed on the active virtual switch? console access is disabled on the standby virtual switch. The active virtual switch is responsible for all control plane functions, such as Simple Network Management Protocol (SNMP), Telnet, Secure Shell (SSH), Spanning Tree Protocol (STP), Link Aggregation Control Protocol (LACP), and Layer 3 routing. The data plane is active on both switches.
Virtual Switch Link Protocol (VSLP) is responsible for establishing the VSS. VSLP has two component protocols: Link Management Protocol (LMP) and Role Resolution Protocol (RRP). The VSS initialization process consists of the following steps:1. The configuration file is pre-parsed for VSL configuration commands.
2. The VSL member interfaces are brought online.
3. LMP verifies link integrity, rejects unidirectional links, and establishes bidirectional communication between switch chassis.
4. LMP exchanges switch IDs in order to detect duplicate IDs.
5. RRP checks hardware versions, software versions, and VSL configurations for compatibility.
6. RRP assigns the active virtual and standby virtual switch roles.
7. Switches come up in NSF/SSO mode or RPR mode.
8. Switches continue the normal boot process.The switch chassis that is started first will always become the active virtual switch unless preemption is configured. If both chassis are started simultaneously, the switch with the highest priority will become the active virtual switch. By default, the priority is set to a value of 100. If priorities are equal, the switch with the lower switch ID will become the active virtual switch. In this scenario, Switch1 has a higher priority and a lower switch ID; therefore, Switch1 will become the active virtual switch and Switch2 will become the standby virtual switch. If the active chassis fails and subsequently recovers, it will assume the role of standby chassis unless preemption is configured.
If RRP determines that both switches are compatible, both chassis will come up in NSF/SSO mode, in which all modules are powered up and can forward traffic. If RRP determines that an incompatibility exists, the standby virtual switch will come up in RPR mode, in which all modules are powered down. In this scenario, Switch1 will come up in NSF/SSO mode and Switch2 will come up in RPR mode. -
DRAG DROP
To complete this question, click Select and Place and follow the instructions.
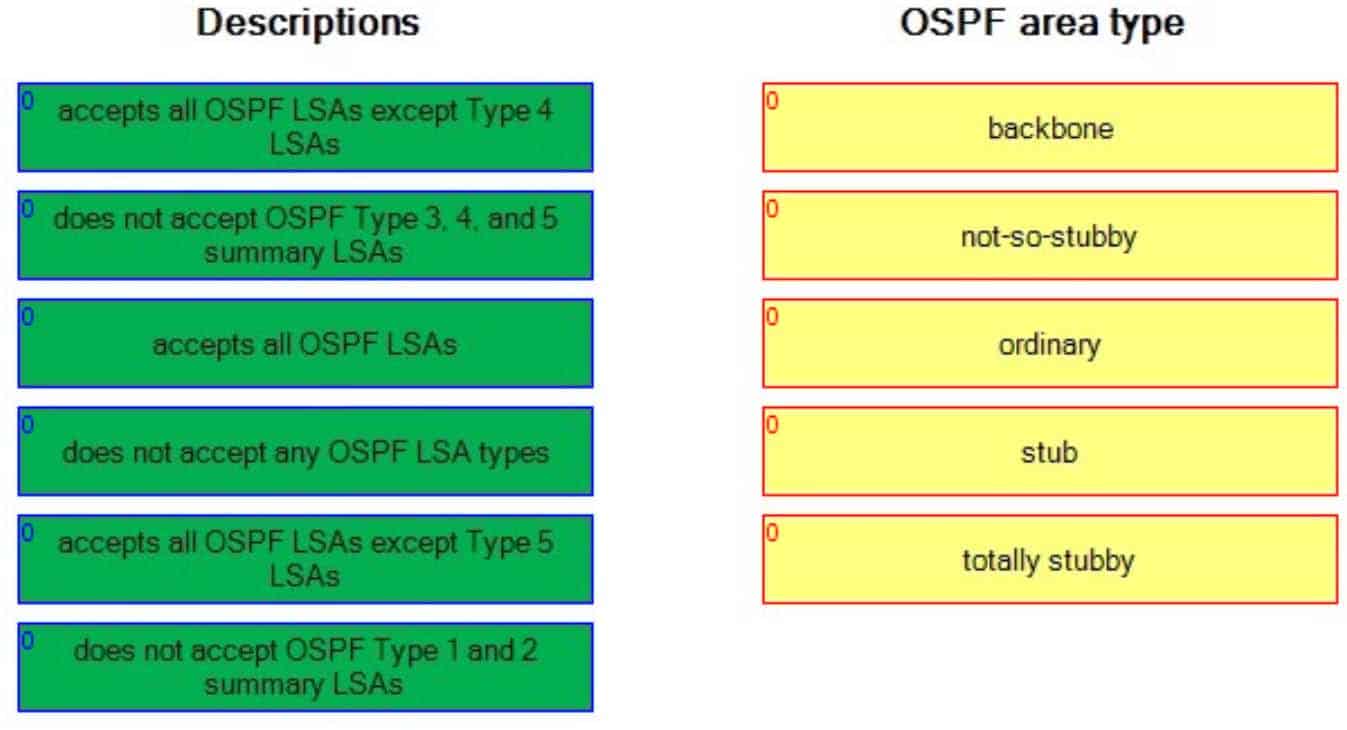
Select a description from a column on the left, and drag it to the corresponding OSPF area type on the right. Some descriptions may be used more than once; not all descriptions will be used.
350-401 Part 02 Q04 019 Question 
350-401 Part 02 Q04 019 Answer Explanation:
A totally stubby area does not accept Open Shortest Path First (OSPF) Type 3, 4, and 5 summary linkstate advertisements (LSAs), which advertise routes outside the area. These LSAs are replaced by a default route at the area border router (ABR). As a result, routing tables are kept small within the totally stubby area. To create a totally stubby area, you should issue the area are aid stub nosummary command in router configuration mode.
The backbone area, Area 0, accepts all OSPF LSAs. All OSPF areas must directly connect to the backbone area or must traverse a virtual link to the backbone area. To configure a router to be part of the backbone area, you should issue the area 0 command in router configuration mode.
An ordinary area, which is also called a standard area, accepts all OSPF LSAs. Every router in an ordinary area contains the same OSPF routing database. To configure an ordinary area, you should issue the area area-id command in router configuration mode.
A stub area accepts all OSPF LSAs except Type 5 LSAs, which advertise external summary routes.
Routers inside the stub area will send all packets destined for another area to the ABR. To configure a stub area, you should issue the area area-id stub command in router configuration mode.
A notsostubby area (NSSA) is basically a stub area that contains one or more autonomous system boundary routers (ASBRs). Like stub areas, NSSAs accept all OSPF LSAs except Type 5 LSAs. External routes from the ASBR are converted to Type 7 LSAs and tunneled through the NSSA to the ABR, where they are converted back to Type 5 LSAs. To configure an NSSA, you should issue the area area-id nssa command in router configuration mode. To configure a totally NSSA, which does not accept summary routes, you should issue the area area-id nssa nosummary command in router configuration mode. -
You administer the network shown above. RouterB and RouterC are running OSPF.
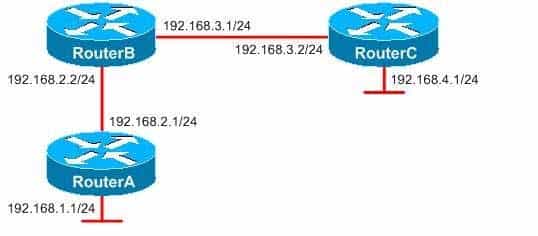
350-401 Part 02 Q05 020 You issue the show ip ospf database external 192.168.1.0 command on RouterB and receive the following output:
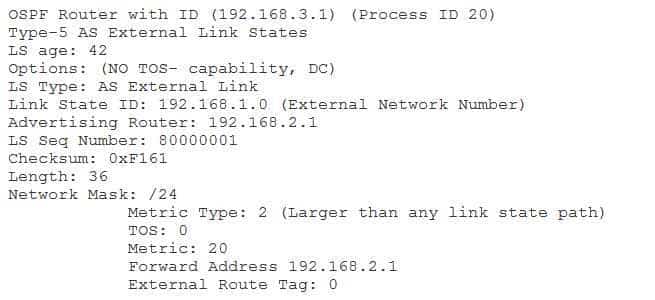
350-401 Part 02 Q05 021 Which of the following statements is true about RouterB regarding the route to 192.168.1.0? (Select the best answer.)
- The nexthop interface is running OSPF.
- The nexthop interface is passive.
- The nexthop interface is configured as a pointtopoint interface.
- RouterB is missing the network command for the 192.168.2.0 network.
Explanation:
The nexthop interface on RouterB is running Open Shortest Path First (OSPF). The output from the show ip ospf database external 192.168.1.0 command indicates that the forwarding address is 192.168.2.1. The forwarding address is a nonzero number only if the following five conditions are met:
– OSPF is enabled on the nexthop interface.
– The nexthop interface is not passive.
– The nexthop interface is not pointtopoint.
– The nexthop interface is not pointtomultipoint.
– The nexthop interface address is a valid address within the subnet specified in the network command.Therefore, the nexthop address must be running OSPF. If the nexthop address were not running OSPF or if any of the above conditions were not met, the forwarding address would be set to 0.0.0.0. This occurs because OSPF does not allow an external route to be used to reach another external OSPF route.
RouterB is not missing the network command for the 192.168.2.0 network. If it were, OSPF would not be enabled on the nexthop interface and the forwarding address would be set to 0.0.0.0.
The next-hop interface is not set for point-to-point or point-to-multipoint operation. If it were, the forwarding address would be set to 0.0.0.0 and you would be required to issue a static route and to redistribute static and connected subnets.The next-hop interface on RouterB is not passive. Configuring an interface as a passive interface prevents a router from sending or receiving OSPF routing information or hello packets on the specified interface. To configure a router as a passive interface, you should issue the passive-interface command in OSPF router configuration mode.
-
SwitchA and SwitchB are Layer 2 switches that are connected by a trunk link that forwards traffic for all VLANs. Server1 uses RouterA as its default gateway. Server2 uses RouterB as its default gateway. RouterA and RouterB are configured to perform interVLAN routing.
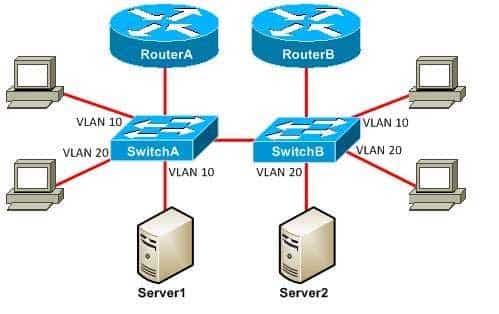
350-401 Part 02 Q06 022 Which of the following statements is true? (Select the best answer.)
- Server1 and Server2 will be unable to communicate.
- Server1 and Server2 will be able to communicate without any problems.
- Server1 will be able to communicate with Server2, but Server2 will not be able to communicate with Server1.
- Server2 will be able to communicate with Server1, but Server1 will not be able to communicate with Server2.
- Server1 and Server2 will be able to communicate, but excess unicast flooding will occur.
Explanation:
Server1 and Server2 will be able to communicate, but excess unicast flooding will occur because of asymmetric routing. When Server1 wants to communicate with Server2, Server1 sends the traffic through SwitchA to its default gateway, RouterA. RouterA routes the traffic through the VLAN 20 subinterface to SwitchA. SwitchA does not know to which port Server2 is connected, so it floods the traffic to all ports that belong to VLAN 20. SwitchB receives the flooded traffic and forwards it directly to Server2.When Server2 wants to respond to Server1, the same process happens in reverse. Server2 sends the traffic through SwitchB to its default gateway, RouterB. RouterB routes the traffic through the VLAN 10 subinterface to SwitchB. SwitchB does not know to which port Server1 is connected, so it floods the traffic to all ports that belong to VLAN 10. SwitchA receives the flooded traffic and forwards it directly to Server1.The behavior exhibited by the network topology in this scenario is called asymmetric routing. The excess unicast flooding occurs because SwitchA does not see traffic from the Media Access Control (MAC) address of Server2 and because SwitchB does not see traffic from the MAC address of Server1. When a switch receives traffic for a destination that is not listed in its forwarding table, it floods the traffic out all ports in that VLAN. If the servers in this scenario send a lot of traffic to one another, other devices connected to the switches can be adversely affected.
It is possible that one of the servers might send a broadcast Address Resolution Protocol (ARP) request, which will cause both switches to learn the MAC address of the server. This will cause the excess unicast flooding to stop. However, the server’s MAC address will eventually age out of the forwarding table, and the excess unicast flooding will resume.
-
You administer the network shown in the diagram.
350-401 Part 02 Q07 023 You want to configure a 6to4 tunnel between RouterA and RouterB. You issue the show runningconfig command on RouterA and receive the following partial output:
interface FastEthernet 0/0
ip address 192.168.1.1 255.255.255.0Which of the following command sets should you issue on RouterA? (Select the best answer.)
-
RouterA(config)#interface tunnel 0RouterA(configif)#ip address 192.168.1.1 RouterA(configif)#tunnel source FastEthernet 0/0 RouterA(configif)#tunnel mode ipv6ip 6to4
-
RouterA(config)#interface tunnel 0RouterA(configif)#ip address 192.168.1.1 RouterA(configif)#tunnel source 2002:C0A8:0101::1/64 RouterA(configif)#tunnel mode 6to4
-
RouterA(config)#interface tunnel 0 RouterA(configif)#ipv6 address 2002:C0A8:0101::1/64 RouterA(configif)#tunnel source FastEthernet 0/0 RouterA(configif)#tunnel mode ipv6ip 6to4 RouterA(configif)#exit RouterA(config)#ipv6 route 2002::/16 tunnel 0
-
RouterA(config)#interface tunnel 0 RouterA(configif)#ipv6 address 2002:C0A8:0101::1/64 RouterA(configif)#tunnel mode 6to4 RouterA(configif)#exit RouterA(config)#ipv6 route 2002::/16 tunnel 0
Explanation:
You should issue the following commands on RouterA:RouterA(config)#interface tunnel 0 RouterA(configif)#ipv6 address 2002:C0A8:0101::1/64 RouterA(configif)#tunnel source FastEthernet 0/0 RouterA(configif)#tunnel mode ipv6ip 6to4 RouterA(configif)#exit RouterA(config)#ipv6 route 2002::/16 tunnel 0
First, you should create the tunnel by issuing the interface tunnel tunnel number command. Issuing the interface tunnel 0 command will create the Tunnel 0 interface and place the router in interface configuration mode.
Next, you should assign an IPv6 address for the tunnel by issuing the ipv6 address ipv6 address command. The IPv6 address for a 6to4 tunnel interface begins with 2002::/16, and the 32 bits following the 2002::/16 prefix correspond to the IPv4 address of the tunnel source. To calculate the IPv6 address prefix that should be used for the tunnel, you should convert the IPv4 address of the tunnel source from dotted decimal to hexadecimal and append it to the 2002::/16 prefix. In this scenario, the tunnel source is the IPv4 address of the FastEthernet 0/0 interface, which is 192.168.1.1. The dotted decimal address 192.168.1.1 converts to the hexadecimal address C0A8:0101. Therefore, the IPv6 address prefix 2002:C0A8:0101::/64 should be used for the tunnel? the IPv6 address 2002:C0A8:0101::1/64 is a valid host address for this prefix.
Alternatively, you can have the tunnel use the IPv6 address that is configured for another router interface by issuing the ipv6 unnumbered interface command. However, for a 6to4 tunnel, the interface must be configured with an IPv6 address that corresponds to the IPv4 address of the tunnel source.
Next, you should configure the tunnel source by issuing the tunnel source {ipv4address | interface} command. In this scenario, you should issue either the tunnel source 192.168.1.1 command or the tunnel source FastEthernet 0/0 command.
You should then configure the tunnel mode for 6to4 operation by issuing the tunnel mode ipv6ip 6to4 command. The following tunnel mode commands can be used for IPv6 overlay tunnel creation:
– tunnel mode ipv6ip 6to4 – creates a 6to4 tunnel
– tunnel mode ipv6ip – creates a manual IPv6 tunnel
– tunnel mode gre ipv6 – creates a Generic Routing Encapsulation (GRE) tunnel
– tunnel mode ipv6ip autotunnel – creates an IPv4compatible tunnel
-tunnel mode ipv6ip isatap – creates an IntraSite Automatic Tunnel Addressing
Protocol (ISATAP) tunnelThe complete procedure for setting up an IPv6 tunnel differs for each of the tunnel types listed above.
Finally, you should exit interface configuration mode and configure a static route to direct IPv6 traffic to the 6to4 tunnel by issuing the ipv6 route ipv6prefix/prefixlength tunnel tunnelnumber command in global configuration mode. The prefix 2002::/16 must always be used for 6to4 tunnels.
After you have issued the commands to create the tunnel on RouterA, you should issue similar commands on RouterB to create the other side of the tunnel.
The following command set is incorrect because an IPv6 address, not an IPv4 address, should be configured for the tunnel:RouterA(config)#interface tunnel 0 RouterA(configif)#ip address 192.168.1.1 RouterA(configif)#tunnel source FastEthernet 0/0 RouterA(configif)#tunnel mode ipv6ip 6to4
Additionally, the ipv6 route 2002::/16 tunnel 0 command is missing.
The following command set is incorrect because an IPv6 address, not an IPv4 address, should be configured for the tunnel:
RouterA(config)#interface tunnel 0 RouterA(configif)#ip address 192.168.1.1 RouterA(configif)#tunnel source 2002:C0A8:0101::1/64 RouterA(configif)#tunnel mode 6to4
Additionally, the tunnel source should specify an IPv4 address or an IPv4enabled interface, not an IPv6 address. Furthermore, the tunnel mode 6to4 command is not a valid Cisco command. Finally, the ipv6 route 2002::/16 tunnel 0 command is missing.
The following command set is incorrect because the tunnel mode is incorrectly specified by the tunnel mode 6to4 command:RouterA(config)#interface tunnel 0 RouterA(configif)#ipv6 address 2002:C0A8:0101::1/64 RouterA(configif)#tunnel source 192.168.1.1 RouterA(configif)#tunnel mode 6to4 RouterA(configif)#exit RouterA(config)#ip route 2002::/16 tunnel 0
Although the tunnel source 192.168.1.1 command in this command set is specified differently from the tunnel source FastEthernet 0/0 command in the correct command set, both are valid methods of specifying the tunnel source.
-
-
You issue the following commands on SwitchA:
SwitchA(config)#interface portchannel 1 SwitchA(configif)#ip address 192.168.1.1 255.255.255.0 SwitchA(configif)#lacp maxbundle 2 SwitchA(configif)#interface range gi 3/2 - 3 SwitchA(configifrange)#channelprotocol lacp SwitchA(configifrange)#channelgroup 1 mode active
You want to add interface Gi 3/1 to the channel group.
Which of the following commands should you issue to configure Gi 3/1 as a standby interface? (Select the best answer.)
- lacp portpriority 22222
- lacp portpriority 44444
- lacp systempriority 22222
- lacp systempriority 44444
Explanation:
You should issue the lacp port-priority 44444 command. The lacp portp-riority valuecommand configures a Link Aggregation Control Protocol (LACP) interface with a port priority, which is used to determine which interfaces are active interfaces and which interfaces are standby interfaces. The value parameter is a value from 1 through 65535? if no priority value is defined, the default port priority value of 32768 is used. Ports with lower priority values are used as active interfaces before ports with higher priority values. If multiple ports have the same priority value, ports with lower port numbers are used before ports with higher port numbers.
The lacp max-bundle 2 command configures a maximum of two active ports on the LACP EtherChannel. Any additional ports that are configured for the EtherChannel are placed in the standby state based on port priority values. In this scenario, Gi 3/2 and Gi 3/3 are not assigned a port priority value. Therefore, the default port priority value of 32768 is used. To configure Gi 3/1 to be used as a standby interface, the port priority value of Gi 3/1 must be higher than 32768. Therefore, you should issue the lacp port-priority
44444command.
The lacp port-priority 22222 command would configure interface Gi 3/1 with a lower port priority value than that of Gi 3/2 and Gi 3/3. If you were to issue this command, interface Gi 3/1 would become an active interface? interface Gi 3/3 would become a standby interface because Gi 3/2 and Gi 3/3 have the same priority value and Gi 3/3 is a higher port number than Gi 3/2.
The lacp system-priority command configures a switch with an LACP system priority. The system priority value can be from 1 through 65535? if no priority value is defined, the default system priority value of 32768 is used. The switch with the lowest system priority makes the decisions regarding which ports are active on the EtherChannel. If two switches have the same priority, the switch with the lowest Media Access Control (MAC) address makes the decisions regarding which ports are active on the EtherChannel. The lacp system-priority 22222 command configures a switch with a system priority lower than the default value, and the lacp systempriority 44444 command configures a switch with a system priority higher than the default value. However, neither lacp systempriority command can be used to configure an interface as a standby interface. -
Which of the following steps in the NAT order of operation typically occur after NAT insidetooutside translation? (Select 3 choices.)
- decryption
- encryption
- redirect to web cache
- check inbound access list
- check outbound access list
- inspect CBAC
- policy routing
- IP routing
Explanation:
The following steps of the Network Address Translation (NAT) order of operation typically occur after NAT insidetooutside translation:– Encryption
– Check outbound access list
– Inspect Contextbased Access Control (CBAC)NAT enables a network to communicate with a separate network, such as the Internet, by translating traffic from IP addresses on the local network to another set of IP addresses that can communicate with the remote network. NAT insidetooutside translation, which is also known as localtoglobal translation, occurs when the NAT router maps an inside network source IP address to an outside network source IP address before forwarding the packet to the next hop. When a NAT router performs NAT insidetooutside translation, the following operations occur in order:
1. If IP Security (IPSec) is implemented, check inbound access list
2. Decryption
3. Check inbound access list
4. Check inbound rate limits
5. Inbound accounting
6. Redirect to web cache
7. Policy routing
8. IP routing
9. NAT insidetooutside translation
10. Check crypto map and mark for encryption
11. Check outbound access list
12. Inspect CBAC
13. Transmission Control Protocol (TCP) intercept
14. Encryption
15. Queueing
Conversely, when a NAT router performs NAT outsidetoinside, or globaltolocal, translation, the NAT outsidetoinside translation operation immediately follows the redirect to web cache operation. Otherwise, the order of operation is the same:1. If IPSec is implemented, check inbound access list
2. Decryption
3. Check inbound access list
4. Check inbound rate limits
5. Inbound accounting
6. Redirect to web cache
7. NAT outsidetoinside translation
8. Policy routing
9. IP routing
10. Check crypto map and mark for encryption
11. Check outbound access list
12. Inspect CBAC
13. TCP intercept
14. Encryption
15. Queueing -
Which of the following are benefits of using VRRP? (Select 3 choices.)
- VRRP supports up to 1,024 virtual routers per physical router interface.
- VRRP provides one virtual IP address for a group of routers.
- VRRP can be used with routers from different vendors.
- VRRP allows load balancing across multiple WAN links.
- VRRP supports MD5 authentication.
Explanation:
Virtual Router Redundancy Protocol (VRRP) provides one virtual IP address for a group of routers, VRRP can be used with routers from different vendors, and VRRP supports Message Digest 5 (MD5) authentication. VRRP is a standardsbased protocol that enables a group of routers to form a single virtual router. With VRRP, several routers are grouped to appear like a single default gateway for the network. VRRP uses the IP address of a physical interface on the master virtual router, which is the router in the group with the highest VRRP priority. The other routers in the group are known as backup virtual routers. If the master virtual router fails, the backup virtual router with the highest priority will assume the role of the master virtual router, thereby providing uninterrupted service for the network. When the original master virtual router comes back online, it reestablishes its role as the master virtual router.
Because VRRP is a standardsbased protocol, VRRP can be used with routers from many different vendors. VRRP is defined in Request for Comments (RFC) 3768. By contrast, Hot Standby Router Protocol (HSRP) and Gateway Load Balancing Protocol (GLBP) are both Ciscoproprietary protocols. Therefore, HSRP and GLBP cannot be used with routers from multiple vendors.
VRRP supports plaintext and MD5 authentication. When a router receives a VRRP packet for its VRRP group, it validates the authentication string. If the authentication string does not match the string that is configured on the router, the VRRP packet is discarded. When plaintext authentication is configured, the authentication string is sent unencrypted. When MD5 authentication is configured, each VRRP packet is sent with a keyed MD5 hash of that packet? if the receiving device does not generate the same hash, the packet is ignored.
Because only the VRRP master virtual router can be the default gateway, VRRP does not allow load balancing across multiple WAN links. By contrast, GLBP allows up to four primary active virtual forwarders (AVFs) to load balance across multiple WAN links. The virtual router has its own virtual IP address and up to four virtual Media Access Control (MAC) addresses, one for each of the primary AVFs in the group. One of the routers in the GLBP group is elected the active virtual gateway (AVG) and performs the administrative tasks for the standby group, such as responding to Address Resolution Protocol (ARP) requests. When a client sends an ARP request for the IP address of the default gateway, the AVG responds with one of the virtual MAC addresses in the group. Because multiple routers in the GLBP group can actively forward traffic, GLBP provides load balancing as well as local redundancy.GLBP, not VRRP, can support up to 1,024 virtual routers per physical router interface. VRRP and HSRP both support up to 255 virtual routers per physical router interface. -
DRAG DROP
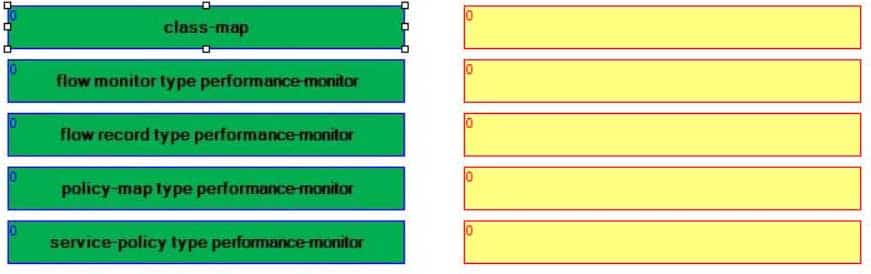
Select the commands on the left, and place them on the right in the order that you should issue them when configuring Cisco Performance Monitor.
350-401 Part 02 Q11 024 Question 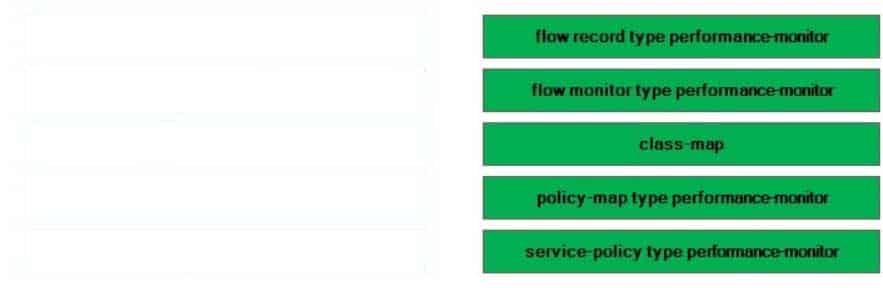
350-401 Part 02 Q11 024 Answer Explanation:
Cisco Performance Monitor enables you to monitor traffic flow information, such as packet count, byte count, drops, jitter, and roundtrip time (RTT). To configure Cisco Performance Monitor, you must perform the following tasks:1. Create a flow record.
2. Configure a flow monitor.
3. Create one or more classes.
4. Create a policy.Associate the policy with an interface.
First, create a Performance Monitor flow record by issuing the flow record type performancemonitor command from global configuration mode. The flow record is used to specify the data that will be collected. To configure the flow record, issue the match and collect commands.
Next, configure a Performance Monitor flow monitor by issuing the flow monitor type performancemonitor command from global configuration mode. The flow monitor allows you to associate a flow record with a flow exporter. A flow exporter is used to send Performance Monitor data to a remote system.
Third, create one or more classes by issuing the class-map command from global configuration mode. A Performance Monitor class map is configured like any other class map by issuing match statements to specify the classification criteria.
Fourth, create a Performance Monitor policy by issuing the policy-map type performancemonitor command from global configuration mode. A Performance Monitor policy associates a class with a flow monitor.
Finally, associate the Performance Monitor policy with an interface by issuing the service-policy type performancemonitor command from interface configuration mode. Issuing this command activates the Performance Monitor policy. -
You have issued the following commands on RouterA:
pseudowireclass boson
ip pmtuRouterA receives a packet that is larger than the path MTU and that has a DF bit set to 1.
Which of the following will RouterA do? (Select 2 choices.)
- RouterA will forward the packet.
- RouterA will drop the packet.
- RouterA will return an ICMP unreachable message to the sender.
- RouterA will fragment the packet before L2TP/IP encapsulation occurs.
- RouterA will fragment the packet after L2TP/IP encapsulation has occurred.
Explanation:
When RouterA receives a packet that is larger than the path maximum transmission unit (MTU) and that has a Don’t Fragment (DF) bit set to 1, RouterA will drop the packet and will return an Internet Control Message Protocol (ICMP) unreachable message to the sender. The ip pmtu command enables path MTU discovery (PMTUD) so that fragmentation issues can be avoided on the service provider backbone.
With PMTUD, the DF bit is copied from the IP header to the Layer 2 encapsulation header. If an IP packet is larger than the MTU of any interface on the path, the packet is dropped or fragmented based on the DF bit. If the DF bit is set to 0, the packet is fragmented before Layer 2 Tunneling Protocol (L2TP)/IP encapsulation occurs and is then forwarded. If the DF bit is set to 1, the packet is dropped and the router will return an ICMP unreachable message to the sender. -
DRAG DROP
Select the ping mpls ipv4 return codes on the left, and drag then to their corresponding definitions on the right.
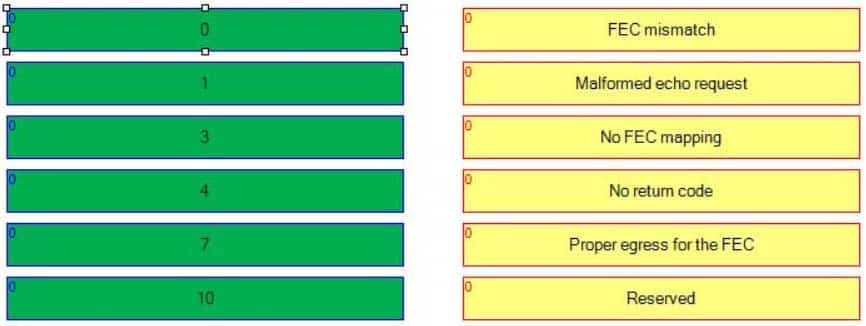
350-401 Part 02 Q13 025 Question 
350-401 Part 02 Q13 025 Answer Explanation:
The ping mpls ipv4 command can be used to verify Multiprotocol Label Switching (MPLS) label switched path (LSP) connectivity. The output will display symbolic and numeric return codes. The following list contains all of the numeric return codes along with their corresponding symbols and definitions:
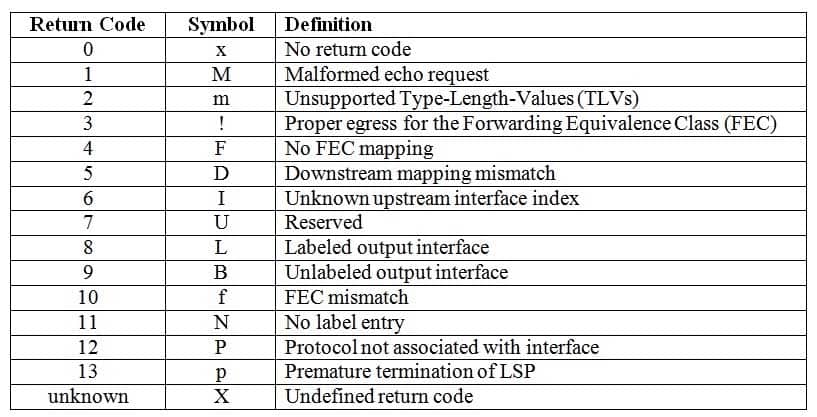
350-401 Part 02 Q13 026 A successful MPLS ping will have a return code of 3 and will look similar to the following output:
-
You want to establish an EtherChannel between SwitchA and SwitchB.
Which of the following modes can you configure on both of the switches to establish the EtherChannel over PAgP? (Select the best answer.)
- on
- passive
- active
- desirable
- auto
Explanation:
You can configure both switches to operate in desirable mode to establish the EtherChannel over Port Aggregation Protocol (PAgP). Alternatively, you can set one switch to auto and the other switch to desirable.PAgP is a Ciscoproprietary protocol that groups individual physical PAgPconfigured ports into a single logical link, called an EtherChannel. The ports that constitute an EtherChannel are grouped according to various parameters, such as hardware, port, and administrative limitations. Once PAgP has created an EtherChannel, it adds the EtherChannel to the spanning tree as a single switch port. Because PAgP is a Cisco-proprietary protocol, it can be used only on Cisco switches.
Link Aggregation Control Protocol (LACP) is a newer, standardsbased alternative to PAgP that is defined by the Institute of Electrical and Electronics Engineers (IEEE) 802.3ad standard. LACP is available on switches newer than the Catalyst 2950 switch, which offers only PAgP. Like PAgP, LACP identifies neighboring ports and their group capabilities; however, LACP goes further by assigning roles to the EtherChannel’s endpoints. Because LACP is a standardsbased protocol, it can be used between Cisco and nonCisco switches.
The following table displays the channelgroup configurations that will establish an EtherChannel:
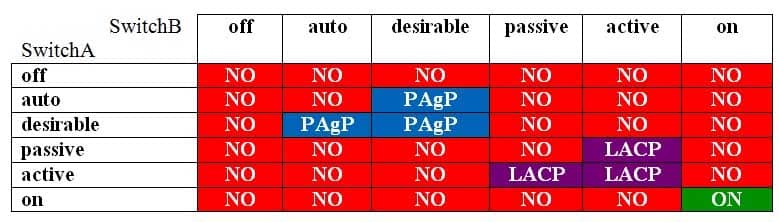
350-401 Part 02 Q14 027 The channelgroup command configures the EtherChannel mode. The syntax of the channelgroup command is channelgroup number mode {on | active | passive | {auto | desirable} [nonsilent]}, where number is the port channel interface number. The on keyword configures the channel group to unconditionally create the channel with no LACP or PAgP negotiation.
The active and passive keywords can be used only with LACP. The active keyword configures the channel group to actively negotiate LACP, and the passive keyword configures the channel group to listen for LACP negotiation to be offered. Either or both sides of the link must be set to active to establish an EtherChannel over LACP? setting both sides to passive will not establish an EtherChannel over LACP.The auto, desirable, and nonsilent keywords can be used only with PAgP. The desirable keyword configures the channel group to actively negotiate PAgP, and the autokeyword configures the channel group to listen for PAgP negotiation to be offered. Either or both sides of the link must be set to desirable to establish an EtherChannel over PAgP; setting both sides to auto will not establish an EtherChannel over PAgP. The optional nonsilent keyword requires that a port receive PAgP packets before the port is added to the channel.
-
You issue the following commands on the routers on your network:
RouterMain(config)#username Router1 password Boson RouterMain(config)#username Router2 password Boson RouterMain(config)#username Router3 password Boson RouterMain(config)#interface s0/1 RouterMain(configif)#encapsulation ppp RouterMain(configif)#ppp authentication chap RouterMain(configif)#exit RouterMain(config)#interface s0/2 RouterMain(configif)#encapsulation ppp RouterMain(configif)#ppp authentication chap RouterMain(configif)#exit RouterMain(config)#interface s0/3 RouterMain(configif)#encapsulation ppp RouterMain(configif)#ppp authentication chap Router1(config)#username routermain password boson Router1(config)#interface s0/1 Router1(configif)#encapsulation ppp Router1(configif)#ppp authentication chap Router2(config)#username RouterMain password Boson Router2(config)#interface s0/1 Router2(configif)#encapsulation ppp Router2(configif)#ppp authentication chap Router3(config)#username RouterMain password boson Router3(config)#interface s0/1 Router3(configif)#encapsulation ppp Router3(configif)#ppp authentication chap
Which of the following routers will be able to connect successfully to RouterMain? (Select the best answer.)
- Router1
- Router2
- Router3
- Router1 and Router2
- Router2 and Router3
- Router1 and Router3
- Router1, Router2, and Router3
Explanation:
Only Router2 will be able to connect successfully to RouterMain. The syntax of the username command is username hostname password password. By default, the hostname parameter is the host name configured in the hostname command of the peer router. However, you can use the ppp chap hostname command to specify a separate host name that is used only for Challenge Handshake Authentication Protocol (CHAP) authentication. Since the ppp chap hostname command has not been issued on the routers in this scenario, the host name that should be specified in the username command is the normal host name for each router.
Router1 will not be able to connect successfully to RouterMain, because the host name and password are specified incorrectly in the username command on Router1. The host name and password specified in the username command are case-sensitive. Therefore, the host name “routermain” does not match the host name “RouterMain”, and the password “boson” does not match the password “Boson”. To enable Router1 to connect, you should issue the username RouterMain password Boson command.
Router3 will not be able to connect successfully to RouterMain. Although the host name is specified correctly in the username command on Router3, the password is specified incorrectly? the password “boson” does not match the password “Boson”. To enable Router3 to connect, you should issue the username RouterMain password Boson command. -
Which of the following statements are true regarding OSPFv3? (Select 3 choices.)
- OSPFv3 does not support IPv6.
- Enabling OSPFv3 on an interface enables the OSPFv3 routing process on the router.
- Network addresses are included in the OSPFv3 process when the network command is issued.
- OSPFv3 sends hello messages and LSAs over multicast addresses 224.0.0.5 and 224.0.0.6.
- The BDR is elected before the DR is elected.
- OSPFv3 uses MD5 to secure communication.
- OSPFv3 supports multiple instances on a single link.
Explanation:
Enabling Open Shortest Path First version 3 (OSPFv3) on an interface enables the OSPFv3 routing process on the router. Additionally, the backup designated router (BDR) is elected before the designated router (DR) is elected. Finally, OSPFv3 supports multiple instances on a link. To enable OSPFv3 on an interface, you should issue the ipv6 ospf processid area areaid command in interface configuration mode. To enter router configuration mode for OSPFv3, you should issue the ipv6 router ospf processid command or the router ospfv3 [processid] command in global configuration mode.
The DR and BDR election process for OSPFv3 multiaccess segments is handled the same way as it is handled in OSPFv2: the BDR is elected first, and then the DR is elected. The router with the highest priority, as long as it has not already declared itself as the DR, becomes the BDR. Of those routers that have declared themselves as the DR, the router with the highest priority is elected to become the DR. If priority values are equal, the router with the highest router ID is elected. To change the OSPF priority of a router, you should issue the ip ospf priority value command, where value is an integer from 0 through 255. The default OSPF priority is 1, and a router with an OSPF priority of 0 will never be elected the DR or BDR.
OSPFv3 supports both IPv4 and IPv6. OSPFv3, which is described in Request for Comments (RFC) 2740, was developed as an enhancement to OSPFv2, which supports only IPv4. An OSPFv3 instance can support either IPv4 or IPv6, but not both. However, you can run multiple OSPFv3 instances on a single link. You can issue the ospfv3 processid area areaid {ipv4 | ipv6} [instance instanceid] command to enable OSPFv3 on an interface for a particular address family.
Network addresses are not included in the OSPFv3 process when the network command is issued. The network command is not required, because OSPFv3 is configured directly on each participating interface. Each IPv6 interface is designed to be configured with many different types of IPv6 addresses, such as sitelocal, linklocal, and global unicast. When you configure OSPFv3 on an interface, all IPv6 address prefixes are included? you cannot exclude certain prefixes and allow others.OSPFv3 does not send hello messages or linkstate advertisements (LSAs) over the IPv4 multicast addresses 224.0.0.5 and 224.0.0.6. Instead, OSPFv3 uses the IPv6 multicast addresses FF02::5 and FF02::6. All OSPFv3 routers receive packets destined for FF02::5, which is similar to the OSPFv2 allrouters multicast address 224.0.0.5. OSPFv3 DRs and BDRs receive packets destined for FF02::6, which is similar to the OSPFv2 allDR/BDR multicast address 224.0.0.6.
Unlike OSPFv2, OSPFv3 does not use Message Digest 5 (MD5) to secure communication. Instead, OSPFv3 uses IP Security (IPSec) to secure communication. -
DRAG DROP
Drag the OSFP neighbor relationship states on the left to the corresponding reasons on the right.

350-401 Part 02 Q17 028 Question 
350-401 Part 02 Q17 028 Answer Explanation:
When an Open Shortest Path First (OSPF) neighbor router is powered on, it transitions through the following neighbor states:
-Down
-Init
-2-Way
-Exstart
-Exchange
-Loading
-FullAn OSPF neighbor router begins in the Down state. A neighbor in the Down state has not yet sent a hello packet. When a hello packet is received from the neighbor router but the hello packet does not contain the receiving router’s ID, the neighbor router is in the Init state. The receiving router replies to the neighbor router with a hello packet that contains the neighbor router’s ID as an acknowledgment that the receiving router received the neighbor’s hello packet. If a router is stuck in the Init state, it has sent hello packets but has not received them from the neighbor router. If a router is stuck in the Down or Init state, you should check to see whether an access list is blocking 224.0.0.5, which is used by OSPF to send hello packets. Additionally, you should ensure that Layer 1 and Layer 2 connectivity exists and that authentication is disabled or enabled on both neighbors.
The neighbor router replies with a hello packet that contains the receiving router’s ID. When this occurs, the neighbor router is in the 2Way state. At the end of the 2Way state, the designated router (DR) and backup designated router (BDR) are elected for broadcast and nonbroadcast multiaccess (NBMA) networks. On broadcast and NBMA networks, neighbor routers will proceed to the Full state only with the DR and BDR; routers will remain in the 2Way state with all other neighbor routers. Routers that remain in the 2Way state will contain 2WAY/DROTHER in the output of the show ip ospf neighbor command. If all routers on a segment remain in the 2Way state, you should verify whether all routers on the segment are set to a priority of 0, which prevents any of them from becoming the DR or BDR.
After the DR and BDR are elected, neighbor routers form master-slave relationships in order to establish the method for exchanging linkstate information. Routers in this state are in the Exstart state. Neighbor routers then exchange database descriptor (DBD) packets. These DBD packets contain linkstate advertisement (LSA) headers that describe the contents of the linkstate database. Routers in this state are in the Exchange state. If a router is stuck in the Exstart or Exchange state, you should determine whether there is a problem with mismatched maximum transmission unit (MTU) settings.
Routers then send linkstate request packets to request the contents of the neighbor router’s OSPF database. The neighbor router replies with linkstate update packets that contain the routing database information. Routers in this state are in the Loading state. If a router is stuck in the Loading state, you should determine whether there is a problem with corrupted LSAs.
After the OSPF databases of neighbor routers are fully synchronized, the routers transitionto the Full state, which is the normal OSPF router state. A router will periodically send hello packets to its neighbors to indicate that it is still functional. If a router does not receive a hello packet from a neighbor within the dead timer interval, the neighbor router will transition back to the Down state. -
You administer the network in the following exhibit:
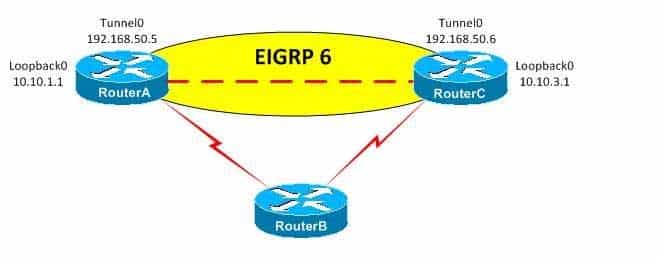
350-401 Part 02 Q18 029 You issue the show runningconfig command on RouterA and receive the following partial output:
interface Loopback0
ip address 10.10.1.1 255.255.255.0
!
interface Tunnel0
ip address 192.168.50.5 255.255.255.0
tunnel source Loopback0
tunnel destination 10.10.3.1RouterA and RouterC are both configured to use RouterB as a gateway of last resort. Additionally, static routes to the Loopback0 interfaces on RouterA and RouterC have beenconfigured on RouterB.
You configure EIGRP on RouterA and then issue the show ip route command, which produces the following partial output:
Gateway of last resort is 172.15.1.2 to network 0.0.0.0
172.15.0.0/24 is subnetted, 1 subnets
C 172.15.1.0 is directly connected, Serial0/0
10.0.0.0/24 is subnetted, 2 subnets
10.10.1.0 is directly connected, Loopback0
10.10.3.0 [90/297372416] via 192.168.50.6, 00:00:01, Tunnel0
C 192.168.50.0/24 is directly connected, Tunnel0
S* 0.0.0.0/0 [1/0] via 172.15.1.2Which of the following is true? (Select the best answer.)
- The Tunnel0 interface and EIGRP adjacency on RouterA will flap.
- The Tunnel0 interface and EIGRP adjacency on RouterA will function properly.
- The Tunnel0 interface on RouterA will function properly, but EIGRP will flap.
- The Tunnel0 interface on RouterA will flap, but the EIGRP adjacency will function properly.
Explanation:
The Tunnel0 interface and Enhanced Interior Gateway Routing Protocol (EIGRP) adjacency on RouterA will flap because the preferred route to the Tunnel0 destination interface is through the tunnel itself, which results in recursive routing. When recursive routing occurs, the Tunnel0 interfaces on both RouterA and RouterC will be temporarily disabled, which breaks the EIGRP adjacency.
The EIGRP adjacency will reestablish when the tunnel interfaces return to the up state. Therefore, if you were to issue the show ip route command on RouterA while the adjacency is established, you would see that the preferred route to the Loopback0 interface on RouterC from RouterA is through Tunnel0, even though the destination interface for Tunnel0 on RouterA is the Loopback0 interface on RouterC.
If the cause of the recursive routing is not fixed, the Tunnel0 interfaces will flap and errorssimilar to the following will be displayed on RouterA:*Mar 1 00:26:15.379: %TUN5RECURDOWN: Tunnel0 temporarily disabled due to recursive routing
*Mar 1 00:26:16.379: %LINEPROTO5UPDOWN: Line protocol on Interface Tunnel0, changed state to down
*Mar 1 00:26:16.487: %DUAL5NBRCHANGE: IPEIGRP(0) 6: Neighbor 192.168.50.6 (Tunnel0) is down: interface downIn this scenario, an EIGRP adjacency has been established between the Tunnel0 interfaceson RouterA and RouterC. When the EIGRP adjacency comes up, the show ip route command displays Tunnel0 as the preferred route to 192.168.50.0 instead of the gateway of last resort. Therefore, the EIGRP 6 domain has been configured to include the 10.10.1.0/24 and 192.168.50.0/24 networks on RouterA and the 10.10.3.0/24 and 192.168.50.0/24 networks on RouterC. As a result, recursive routing to the 10.10.3.0 network through Tunnel0 occurs on RouterA and recursive routing to the 10.10.1.0 network occurs on RouterC.
There are two ways to resolve the recursive routing issue on both RouterA and RouterC in this scenario: remove the 192.168.50.0/24 network from the EIGRP 6 domain, or add a static route to the Tunnel0 destination IP addresses on both RouterA and RouterC. A static route has a lower administrative distance (AD) than EIGRP. Therefore, a static route would fix the recursive routing problem.
-
In a three-node OpenStack architecture, the network node consists of services from which of the following OpenStack components? (Select the best answer.)
- Glance
- Horizon
- Keystone
- Neutron
- Nova
Explanation:
In a three-node OpenStack architecture, the network node consists of services from the Neutron component. OpenStack is an open-source cloud-computing platform. Each OpenStack modular component is responsible for a particular function, and each component has a code name. The following list contains several of the most popular OpenStack components:-Nova -OpenStack Compute: manages pools of computer resources
-Neutron -OpenStack Networking: manages networking and addressing
-Cinder -OpenStack Block Storage: manages blocklevel storage devices
-Glance -OpenStack Image: manages disk and server images
-Swift -OpenStack Object Storage: manages redundant storage systems
-Keystone -OpenStack Identity: is responsible for authentication
-Horizon -OpenStack Dashboard: provides a graphical user interface (GUI)
-Ceilometer -OpenStackTelemetry: provides counterbased tracking that can be used for customer usage billingA three-node OpenStack architecture consists of the network node, the controller node, and the compute node. The network node consists of the following Neutron services:
-Neutron Modular Layer 2 (ML2) PlugIn
-Neutron Layer 2 Agent
-Neutron Layer 3 Agent
-Neutron Dynamic Host Configuration Protocol (DHCP) AgentThe controller node consists of the following services:
-Keystone
-Glance
-Nova Management
-Neutron Server
-Neutron ML2 Plug-In
-Horizon
-Cinder
-Swift
-Ceilometer CoreThe compute node consists of the following services:
-Nova Hypervisor
-Kernel-based Virtual Machine (KVM) or Quick Emulator (QEMU)
-Neutron ML2 Plug-In
-Neutron Layer 2 Agent
-Ceilometer Agent -
Which of the following statements is true regarding hypervisors? (Select the best answer.)
- Both KVM and Xen are Type1 hypervisors.
- Both KVM and Xen are Type2 hypervisors.
- Type1 hypervisors are generally slower than Type2 hypervisors.
- Type2 hypervisors are also called native hypervisors.
Explanation:
Both Kernel based Virtual Machine (KVM) and Xen are Type1 hypervisors. A hypervisor is used to create and run virtual machines (VMs). A Type1 hypervisor runs directly on the host computer’s hardware. Other Type1 hypervisors include HyperV and VMware ESX/ESXi.
KVM and Xen are not Type2 hypervisors. A Type2 hypervisor runs within an operating system on the host computer. VMware Workstation, Parallels Desktop for Mac, and Quick Emulator (QEMU) are Type2 hypervisors.
Type-1 hypervisors are generally faster than Type-2 hypervisors because Type-1 hypervisors run directly on the host computer’s hardware and because Type-2 hypervisors have a host operating system that consumes system resources.
Type-1 hypervisors are also called native hypervisors or baremetal hypervisors. Type-2 hypervisors are also called hosted hypervisors.