350-401 : Implementing Cisco Enterprise Network Core Technologies (ENCOR) : Part 03
-
Which of the following routing protocols can be used for routing on IoT networks? (Select the best answer.)
- EIGRP
- IS-IS
- OSPF
- RPL
Explanation:
Routing Protocol for Lowpower and Lossy Networks (RPL) can be used for routing on Internet of Things (IoT) networks. RPL is an IP version 6 (IPv6) routing protocol that is defined in Request for Comments (RFC) 6550. An IoT network is considered to be a Low-power and Lossy Network (LLN).
IoT networks connect embedded devices. Embedded devices, or smart objects, are typically lowpower, lowmemory devices with limited processing capabilities. These devices are used in a variety of applications, such as environmental monitoring, healthcare monitoring, process automation, and location tracking. Many embedded devices can transmit data wirelessly, and some are capable of transmitting over a wired connection. However, connectivity is generally unreliable and bandwidth is often constrained.
IoT networks require a routing protocol that can handle the limitations of embedded devices. Neither Enhanced Interior Gateway Routing Protocol (EIGRP), Intermediate System to Intermediate System (IS-IS), nor Open Shortest Path First (OSPF) meets the requirements for routing an IoT network, as specified by the Internet Engineering Task Force (IETF) Routing over LLNs (ROLL) working group. In addition to RPL, IPv6 over Low Power Wireless Personal Area Networks (6LoWPAN) and Constrained Application Protocol (CoAP) have been created to address the challenges of routing an IoT network. -
You administer the network shown above. No VLANs are configured on any of the switches.
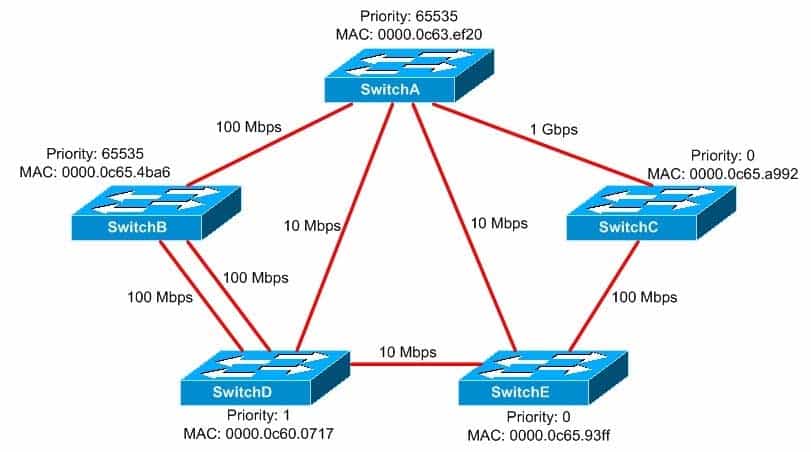
350-401 Part 03 Q02 030 Which of the following switches is the root bridge for the network? (Select the best answer.)
- SwitchA
- SwitchB
- SwitchC
- SwitchD
- SwitchE
Explanation:
SwitchE is the root bridge for the network. The root bridge is the switch with the lowest bridge ID. The bridge ID is composed of a 2byte bridge priority and a 6byte Media Access
Control (MAC) address. The bridge priority is considered first in the determination of the lowest bridge ID. The bridge priority can be set by issuing the spanning-tree priorityvalue command, where value is a number from 0 through 65535? the default priority is 32768.
SwitchC and SwitchE both have a priority of 0. When two or more switches have the lowest priority, the switch with the lowest MAC address becomes the root bridge. MAC addresses are written in hexadecimal format. With MAC addresses, numbers are lower than letters and the hexadecimal value A is lower than the hexadecimal value F. Because SwitchE has a lower MAC address than SwitchC, SwitchE is the root bridge.
SwitchA is not the root bridge for the network, because it has the highest priority value, not the lowest priority value. Although link speed is somewhat relevant in determining the root port for a switch, link speed is irrelevant in determining the root bridge.
SwitchB is not the root bridge for the network; like SwitchA, SwitchB also has the highest priority value, not the lowest priority value. SwitchB contains redundant links to SwitchD, but redundant links are irrelevant in determining the root bridge. To avoid a switching loop, at least one of the redundant links between SwitchB and SwitchD will be blocked.
SwitchC is not the root bridge for the network. If the bridge priority of SwitchE were higher than 0, SwitchC would be the root bridge because a priority of 0 is the lowest configurable priority value.
SwitchD is not the root bridge for the network. Although SwitchD has the lowest MAC address on the network, the bridge priority is considered first in the determination of the root bridge. If all of the switches on the network had the same bridge priority values, SwitchD would be the root bridge because it has the lowest MAC address. -
You administer the EIGRP network shown above.
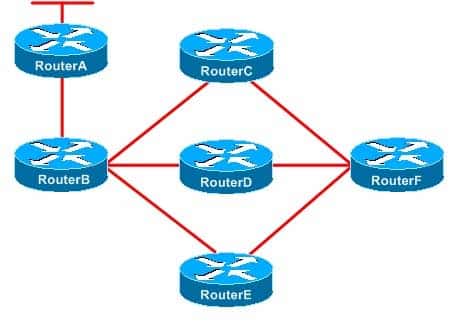
350-401 Part 03 Q03 031 RouterB is configured to send only a summary route to RouterE. RouterC is configured as a stub router.
The link between RouterA and RouterB fails.
Which of the following routers will send a query to RouterF? (Select the best answer.)- only RouterC
- only RouterD
- only RouterE
- only RouterC and RouterD
- only RouterD and RouterE
- RouterC, RouterD, and RouterE
Explanation:
Only RouterD will send a query to RouterF. Query packets are sent to find routes to a destination network. When a router loses the best route to a destination and does not have a feasible successor, it floods query packets to its neighbors. If a neighbor has a route to the destination network, it replies with the route. However, if a neighbor does not have a route to the destination network, it queries its neighbors, those neighbors query their neighbors, and so on. This process continues until either a router replies with the route or there are no routers left to query. The network cannot converge until all the replies have been received, which can cause a router to become stuck in active (SIA).
Limiting Enhanced Interior Gateway Routing Protocol (EIGRP) queries prevents queries from consuming bandwidth and processor resources and prevents routers from becoming SIA. You can display which routers have not yet replied to a query by issuing the show ip eigrp topology active command, as shown in the following output:
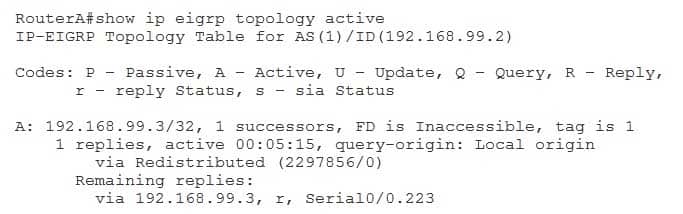
350-401 Part 03 Q03 032 The eigrp stub command limits EIGRP queries by creating a stub router. Stub routers advertise only a specified set of routes and therefore typically need only a default route from a hub router. A hub router detects that a router is a stub router by examining the Type-Length-Value (TLV) field within EIGRP hello packets sent by the router. The hub router will specify in its neighbor table that the router is a stub router and will no longer send query packets to that stub router, thereby limiting how far EIGRP queries spread throughout a network. Because RouterC is configured as a stub router, RouterB will not send queries to RouterC, and RouterC will therefore not propagate those queries to RouterF. Although hub routers will not send queries to stub routers, stub routers can initiate queries of their own.
The ip summary address eigrp as number address mask command limits EIGRP queries by configuring route summarization. If a neighbor router has a summarized route but does not have the specific route to the destination network in the query, the neighbor router will reply that it does not have a route to the destination network and will not query its neighbors. Thus route summarization creates a query boundary that prevents queries from propagating throughout the network. In this scenario, RouterB is configured to send only a summary route to RouterE; therefore, RouterE will not send queries to RouterF.
RouterD is not configured as a stub router, and RouterB is not sending RouterD a summarized route. Therefore, when RouterB sends a query to RouterD, RouterD will send a query to RouterF. -
Which of the following seed metrics is assigned by default when OSPF routes are redistributed into EIGRP? (Select the best answer.)
- 0
- 1
- 20
- infinity
- the metric used by the OSPF route
Explanation:
A default seed metric with the value of infinity is assigned to Open Shortest Path First(OSPF) routes that are redistributed into Enhanced Interior Gateway Routing Protocol (EIGRP). Routes with an infinite metric are ignored by EIGRP and are not entered into the routing table. There is no direct translation of the OSPF cost-based metric into an EIGRP-equivalent metric; the EIGRP metric is based on bandwidth, delay, reliability, and load. Because the OSPF metric cannot be automatically converted into a metric that EIGRPunderstands, EIGRP requires that the metric be defined for all redistributed routes before those routes are entered into the routing table. To assign a default metric for routes redistributed into EIGRP, you should issue the defaultmetric bandwidth delay reliability loading mtu command. To assign a metric to an individual route redistributed from OSPF into EIGRP, you should issue the redistribute ospf processidmetric bandwidth delay reliability loading mtu command.
A default seed metric of infinity is also assigned to routes that are redistributed into Routing Information Protocol (RIP). Like EIGRP, RIP requires that the metric be defined for all redistributed routes before those routes are entered into the routing table. RIP uses hop count as a metric. Valid hopcount values are from 1 through 15; a value of 16 is considered to be infinite. The hopcount metric increases by 1 for each router along the path. Cisco recommends that you set a low value for the hopcount metric for redistributed routes. To assign a default metric for routes redistributed into RIP, you should issue the defaultmetric hopcount command. To assign a metric to an individual route redistributed into RIP, you should issue the redistribute protocolhopcount command. If no metric is assigned during redistribution and no default metric is configured for RIP, the routes are assigned an infinite metric and are ignored by RIP.
A default seed metric of 0 is assigned to routes that are redistributed into Intermediate System to Intermediate System (ISIS). ISIS uses a cost metric assigned to each participating interface. ISIS prefers routes with the lowest cost. Routes redistributed into
IS-IS are designated as Level 2 routes unless otherwise specified.
A default seed metric of 1 is assigned to Border Gateway Protocol (BGP) routes that are redistributed into OSPF. OSPF uses a cost metric based on the bandwidth of each participating interface and prefers internal routes with the lowest cost. By default, all routes redistributed into OSPF are designated as Type 2 external (E2) routes. E2 routes have a metric that remains constant throughout the routing domain. Alternatively, routes redistributed into OSPF can be designated as Type 1 external (E1) routes. With E1 routes, the internal cost of the route is added to the initial metric assigned during redistribution.
A default seed metric of 20 is assigned to routes that are redistributed into OSPF from an internal gateway protocol other than OSPF. When OSPF routes are redistributed from one OSPF routing process to another OSPF routing process, the metrics are preserved and no default seed metric is assigned. Metrics are also preserved when routes are redistributed from one Interior Gateway Routing Protocol (IGRP) or EIGRP routing process into another IGRP or EIGRP routing process. -
What is the size of the IPv6 fragment header? (Select the best answer.)
- 32 bits
- 64 bits
- 20 bytes
- 40 bytes
- 1,280 bytes
Explanation:
The IPv6 fragment header is 64 bits long. The fragment header is used by an IPv6 source to indicate a packet that exceeds the path maximum transmission unit (MTU) size. Unlike IPv4, which enables intervening devices such as routers to fragment packets that exceed the permitted size for a local link, IPv6 requires the traffic originator to ensure that each packet sent is small enough to traverse the entire link without fragmentation. The packet can then be reassembled at the destination.
The IPv6 fragment header is not 32 bits long. However, the IPv6 fragment header contains a 32bit field called the identification field. The identification field is used to uniquely identify each fragmented packet.
The IPv6 fragment header is neither 20 bytes nor 40 bytes long. A basic IPv4 header without options is 20 bytes long, and a basic IPv6 header without extension headers is 40 bytes long. Although an IPv4 header is shorter than an IPv6 header, it is more complex and contains more fields than an IPv6 header. Several fields that exist in an IPv4 header, such as the Header Checksum field and the Fragment Offset field, do not exist in an IPv6 header. Because many protocols at the Data Link and Transport layers contain mechanisms to verify the integrity of the packet, IPv6 does not contain a redundant method to calculate checksum values.
The IPv6 fragment header is not 1,280 bytes long. The default IPv6 MTU size is 1,280 bytes. IPv6 requires that each device have an MTU of 1,280 bytes or greater. -
Which of the following mutual redistribution scenarios does not require you to configure manual redistribution? (Select the best answer.)
- static routes and RIPv2
- static routes and EIGRP
- OSPF processes with different process IDs
- IS-IS and OSPF processes with the same area number
- IGRP and EIGRP processes with the same ASN
- EIGRP processes with different ASNs
Explanation:
Interior Gateway Routing Protocol (IGRP) processes and Enhanced IGRP (EIGRP) processes with the same autonomous system number (ASN) do not require manual redistribution. Mutual redistribution of IGRP and EIGRP routing processes occurs automatically if the processes share the same ASN; there is no additional configuration required to enable route redistribution between the IGRP and EIGRP processes. However, you must manually configure route redistribution between IGRP and EIGRP processes with different ASNs.
Routing Information Protocol version 2 (RIPv2) automatically redistributes static routes that point to an interface on the router. However, RIP does not redistribute static routes that point to a nexthop IP address unless you issue the redistribute static command from RIP router configuration mode. RIPv2 assigns static routes a metric of 1 and redistributes them as though they were directly connected. Because there is only one routing protocol involved when static routes are redistributed into a RIPv2 routing domain, this is a one way redistribution of routing information.
EIGRP automatically redistributes static routes that point to an interface on the router.
However, EIGRP does not redistribute static routes that point to a nexthop IP addressunless you issue the redistribute static command from EIGRP router configuration mode. The static route is redistributed as an external route. Because there is only one routing protocol involved when static routes are redistributed into an EIGRP routing domain, this is a oneway redistribution of routing information.
Open Shortest Path First (OSPF) processes with different process IDs do not redistribute routes without manual configuration. Although it is possible to run multiple OSPF processes on a single router, it is not recommended, because suboptimal routing and routing loops may occur.
Intermediate System-to-Intermediate System (IS-IS) and OSPF processes with the same area number do not redistribute routes without manual configuration. ISIS and OSPF both assign a default metric to redistributed routes unless otherwise specified. -
DRAG DROP
Select the attributes from the left, and place them on the right in the order they are prioritized by the OSPFv2 Loop-Free Alternate Fast Route feature by default.

350-401 Part 03 Q07 033 Question 
350-401 Part 03 Q07 033 Answer Explanation:
The Open Shortest Path First version 2 (OSPFv2) Loop-Free Alternate Fast Reroute feature is used to reroute traffic if a link fails. Repair paths are calculated and stored in the Routing Information Base (RIB). When a primary path fails, the repair path is used without requiring route recomputation. OSPFv2 Loop-Free Alternate Fast Reroute is not supported on virtual links, but it is supported on VPN routing and forwarding (VRF) OSPF instances. You can configure a traffic engineering (TE) tunnel interface as a repair path but not as a protected interface.
The srlg attribute is considered first in the calculation of a repair path. A shared risk link group (SRLG) is a group of next-hop interfaces that are likely to fail simultaneously. You can issue the srlg command to assign an interface to an SRLG.
The primary path attribute is considered second. You can configure the primary path attribute so that a particular repair path is used.
The interface-disjoint attribute is considered third. You can set the interface-disjoint attribute to prevent selection of pointtopoint interfaces, which have no alternate next hop for rerouting.
The lowest metric attribute is considered fourth. The lowest cost route might not be the most stable route. However, you can configure the metric attribute to ensure that routes with lower metrics are selected as repair paths.
The linecard-disjoint attribute is considered fifth. Interfaces on the same line card are likely to fail at the same time if there is a problem with the card.
The node-protecting attribute is considered sixth. You can configure the node-protecting attribute so that the primarypath gateway router is not selected for the repair path.
The broadcast-interface-disjoint attribute is considered last. You can configure the broadcast-interface-disjoint attribute so that the repair path does not use the broadcast network to which the primary path is connected. -
You issue the show running-config command on RouterA and receive the following partial output:
Access-list 101 permit ip host 172.16.223.82 10.17.88.0 0.0.0.255
route-map map1 permit 10
match ip address 101
set next-hop 192.168.1.1Which of the following packets will RouterA redirect to the nexthop router at 192.168.1.1? (Select the best answer.)
- packets sent from the 10.17.88.0/24 network or destined to 172.16.223.82
- packets sent from the 10.17.88.0/24 network and destined to 172.16.223.82
- packets sent from 172.16.223.82 or destined to the 10.17.88.0/24 network
- packets sent from 172.16.223.82 and destined to the 10.17.88.0/24 network
Explanation:
RouterA will detect packets sent from 172.16.223.82 and destined to the 10.17.88.0/24 network and then redirect them to the nexthop router at 192.168.1.1. Route maps are conditional statements that determine whether a packet is processed normally or modified. A route map can be divided into a series of sequences that are processed in sequentialorder. If a route matches all the match criteria in a sequence, the route is permitted or denied based on the permit or deny keywords in the routemap command and any setconditions are applied. If a route does not match all the match criteria in any sequence, the route is discarded.
In this scenario, the routemap map1 permit 10 command creates a route map namedmap1. The permit10 keywords indicate that any route satisfying all the matchstatements in route map sequence number 10 will be redistributed. In this sequence, there is only one match statement, match ip address 101, which indicates that packets that match the IP addresses in access list 101 will be processed by the route map.
The accesslist 101 permit ip host 172.16.223.82 10.17.88.0 0.0.0.255 command creates access list 101, which specifies that IP packets sent from 172.16.223.82 and destined to the 10.17.88.0/24 network are processed by the route map. Packets have to match only one accesslist statement in order to be processed by the route map.
RouterA will not redirect packets sent from the 10.17.88.0/24 network and destined to 172.16.223.82. To configure RouterA to match this traffic, you would need to reverse the keywords in the accesslist statement so that the source is the 10.17.88.0/24 network and the destination is the host at 172.16.223.82. The following command set would configure RouterA to detect packets sent from the 10.17.88.0/24 network and destined to 172.16.223.82 and then redirect those packets to the nexthop router at 192.168.1.1:RouterA(config)#accesslist 101 permit ip 10.17.88.0 0.0.0.255 host 172.16.223.82 RouterA(config)#routemap map1 permit 10 RouterA(configroutemap)#match ip address 101 RouterA(configroutemap)#set nexthop 192.168.1.1
RouterA will not redirect packets sent from the 10.17.88.0/24 network or destined to 172.16.223.82. To configure RouterA to match either of two access list criteria, you would need to create two separate accesslist statements: one that matches traffic sent from the 10.17.88.0/24 network destined to anywhere, and one that matches traffic sent from anywhere destined to 172.16.223.82. The following command set would configure RouterA to detect packets sent from the 10.17.88.0/24 network or destined to 172.16.223.82 and redirect those packets to the nexthop router at 192.168.1.1:
RouterA(config)#accesslist 101 permit ip 10.17.88.0 0.0.0.255 any RouterA(config)#accesslist 101 permit ip any host 172.16.223.82 RouterA(config)#routemap map1 permit 10 RouterA(configroutemap)#match ip address 101 RouterA(configroutemap)#set nexthop 192.168.1.1
RouterA will not redirect packets sent from 172.16.223.82 or destined to the 10.17.88.0/24 network. To configure RouterA to match either of two access list criteria, you would need to create two separate accesslist statements: one that matches traffic sent from 172.16.223.82 destined to anywhere, and one that matches traffic sent from anywhere destined to the 10.17.88.0/24 network. The following command set would configure RouterA to detect packets sent from 172.16.223.82 or destined to the 10.17.88.0/24 network and then redirect those packets to the nexthop router at 192.168.1.1:
RouterA(config)#accesslist 101 permit ip any 10.17.88.0 0.0.0.255 RouterA(config)#accesslist 101 permit ip host 172.16.223.82 any RouterA(config)#routemap map1 permit 10 RouterA(configroutemap)#match ip address 101 RouterA(configroutemap)#set nexthop 192.168.1.1
-
You are considering moving your company’s software development to a public cloudbased solution. Which of the following are least likely to increase? (Select 2 choices.)
- availability
- redundancy
- security
- mobility
- control
- scalability
Explanation:
Of the choices provided, security and control are least likely to increase. With a public cloudbased solution, the service provider, not the customer, controls the cloud infrastructure and devices. Therefore, physical security of the data and hardware is no longer in the customer’s control. In addition, resources stored in the public cloud are typically accessed over the Internet. Care must be taken so that the data can be accessed securely.
Availability, redundancy, mobility, and scalability are all likely to increase by moving to a public cloudbased solution. Cloudbased resources are typically spread over several devices, sometimes even in multiple geographic areas, thereby ensuring availability. If one device or location becomes unavailable, other devices and locations can handle the workload. Data stored on cloudbased resources can be copied or moved to other devices or locations, thereby increasing redundancy and mobility. As usage increases, additional devices can be brought online, thereby providing scalability. -
In a threenode OpenStack architecture, which services are part of the compute node? (Select 2 choices.)
- Ceilometer Agent
- Ceilometer Core
- Neutron DHCP Agent
- Neutron Server
- Nova Hypervisor
- Nova Management
- Correct
Explanation:
In a three-node OpenStack architecture, the Ceilometer Agent and the Nova Hypervisorservices are part of the compute node. OpenStack is an opensource cloudcomputing platform. Each OpenStack modular component is responsible for a particular function, and each component has a code name. The following list contains several of the most popular OpenStack components:-Nova -OpenStack Compute: manages pools of computer resources
-Neutron -OpenStack Networking: manages networking and addressing
-Cinder -OpenStack Block Storage: manages blocklevel storage devices
-Glance -OpenStack Image: manages disk and server images
-Swift -OpenStack Object Storage: manages redundant storage systems
-Keystone -OpenStack Identity: is responsible for authentication
-Horizon -OpenStack Dashboard: provides a graphical user interface (GUI)
-Ceilometer -OpenStackTelemetry: provides counterbased tracking that can be used for customer usage billingA threenode OpenStack architecture consists of the compute node, the controller node, and the network node. The compute node consists of the following services:
-Nova Hypervisor
-Kernelbased Virtual Machine (KVM) or Quick Emulator (QEMU)
-Neutron Modular Layer 2 (ML2) PlugIn
-Neutron Layer 2 Agent
-Ceilometer Agent
-The controller node consists of the following services:-Keystone
-Glance
-Nova Management
-Neutron Server
-Neutron ML2 PlugIn
-Horizon
-Cinder
-Swift
-Ceilometer CoreThe network node consists of several Neutron services:
-Neutron ML2 PlugIn
-Neutron Layer 2 Agent
-Neutron Layer 3 Agent
-Neutron Dynamic Host Configuration Protocol (DHCP) Agent -
You issue the show runningconfig command on RouterA and receive the following partial output:

350-401 Part 03 Q11 034 How much web traffic can RouterA send out the FastEthernet0/1 interface during periods of heavy voice and video traffic? (Select the best answer.)
- 10 Mbps
- 15 Mbps
- 20 Mbps
- 25 Mbps
- 40 Mbps
Explanation:
RouterA can send 10 Mbps of web traffic out the FastEthernet0/1 interface during periods of heavy voice and video traffic. To create a Quality of Service (QoS) policy, you must perform the following steps:1.Define one or more class maps by issuing the classmap name command.
2.Define the traffic that matches the class map by issuing one or more match commands.
3.Define one or more policy maps by issuing the policymap name command.
4.Link the class maps to the policy maps by issuing the classname command.
5.Define one or more actions that should be taken for that traffic class.
6.Link the policy map to an interface by issuing the servicepolicy {input | output} name command.Bandwidth guarantees are set in policymap class configuration mode. You can specify the bandwidth as a rate or as a percentage with the bandwidth and priority commands. The syntax of the priority command is priority {bandwidth | percentpercentage} [burst], where bandwidth is specified in Kbps and burst is specified in bytes. The prioritycommand creates a strictpriority queue where packets are dequeued before packets from other queues are dequeued. The strictpriority queue is given priority over all other traffic.
If no priority traffic is being sent, the other traffic classes can share the remainingbandwidth based on their configured values.
The bandwidth command specifies a guaranteed amount of bandwidth for a particular traffic class. The syntax of the bandwidth command is bandwidth {kbps | remaining percentpercentage | percentpercentage}, where kbps is the amount of bandwidth that is guaranteed to a particular traffic class.
In this scenario, Voice over IP (VoIP) traffic is given a guaranteed 20 percent of the interface’s bandwidth. Video traffic is given a guaranteed 40 percent of the interface’s bandwidth. Voice and video traffic can exceed these bandwidth percentages if any unused bandwidth remains.
The remaining 40 percent, or 40 Mbps, of the interface’s bandwidth can be used by other traffic. If traffic does not match any traffic class, it will become part of the classdefault class. In this scenario, web traffic belongs to the classdefault class. Therefore, web traffic can consume 25 percent of the remaining bandwidth. If no other traffic is being sent on the interface, web traffic can consume 25 percent of the interface’s bandwidth. However, when voice and video traffic are heavy, web traffic can consume 25 percent of the remaining 40 Mbps, which is equal to 10 Mbps.
Even less web traffic can be sent if File Transfer Protocol (FTP) traffic or other unclassifiedtraffic is heavy. FTP traffic can consume 50 percent of the remaining bandwidth on the interface. If no other traffic is being sent on the interface, FTP traffic can consume 50 percent of the interface’s bandwidth. During periods of heavy voice and video usage, FTP traffic can consume 50 percent of the remaining 40 Mbps, which is equal to 20 Mbps. -
Which of the following is appended to a VPNv4 BGP route to indicate membership in an RFC 4364 MPLS VPN? (Select the best answer.)
- a label
- an RT
- an RD
- an LSP
- a VRF
Explanation:
A route target (RT) is appended to a virtual private network version 4 (VPNv4) Border
Gateway Protocol (BGP) route to indicate membership in a Request for Comments (RFC)4364 Multiprotocol Label Switching (MPLS) VPN. Export RTs associate each route with one or more VPNs, and import RTs are associated with each VPN routing and forwarding (VRF) table to determine the routes that should be imported into the VRF; a VRF is a routing table instance for a VPN. A label is assigned to each VPNv4 address prefix, and the inboundtooutbound label mapping is stored in the Label Forwarding Information Base (LFIB). By configuring import and export RTs, you can configure which sites can reach each other. For example, you can configure RTs so that CustomerA and CustomerB can communicate with ProviderZ, but CustomerA and CustomerB cannot communicate with one another.
To configure RTs, you should issue the routetarget {import | export | both} valuecommand. The import, export, and both keywords specify whether extended community attributes should be imported, exported, or both. The value parameter should use one of the following formats:– AS:nn, where AS is a 16bit autonomous system number (ASN) and nn is a 32bit decimal number
– A.B.C.D:nn, where A.B.C.D is a 32bit IP address and nn is a 16bit decimal numberA route distinguisher (RD) is a value that is added to the beginning of an IP address to create a globally unique VPNv4 address. RDs enable customers to use the same or overlapping IP address ranges on their internal networks. To create an RD, you should issue the rd value command, where the value parameter uses the same formats as the value parameter in the route-target command.
There are three types of RDs: Type 0, Type 1, and Type 2. The type of RD configuration you create depends on how you issue the value parameter of the rd command and whether you are configuring a multicast VPN environment. Type 0 and Type 1 RDs are used in unicast configurations. A Type 0 RD is configured by issuing the value parameter of the rd command with the 16bit ASN in front of the 32bit decimal number. A Type 1 RD is configured by issuing the value parameter of the rd command with the 32bit decimal number in front of the 16bit ASN. A Type 2 RD is configured similarly to a Type 1 RD but only applies to multicast VPN configurations.
A label switched path (LSP) is the path that labeled packets take through an MPLS network from one label switch router (LSR) to another. The 32bit MPLS label is used by LSRs to make forwarding decisions along the LSP. The MPLS label is placed between the Layer 2 header and the Layer 3 header. The structure of an MPLS label is shown below:
350-401 Part 03 Q12 035 -
On which of the following interfaces can a port ACL be applied? (Select 3 choices.)
- an SVI
- a trunk port
- an EtherChannel interface
- a routed port
- a Layer 2 port
Explanation:
A port access control list (PACL) can be applied to a trunk port, a Layer 2 port, or an EtherChannel interface. PACLs filter inbound Layer 2 traffic on a switch port interface; PACLs cannot filter outbound traffic. When PACLs are applied on a switch, packets are filtered based on several criteria, including IP addresses, port numbers, or upperlayer protocol information. If a PACL is applied to a trunk port, it will filter all virtual LAN (VLAN) traffic traversing the trunk, including voice and data VLAN traffic. A PACL can be used with an EtherChannel configuration, but the PACL must be applied to the logical EtherChannel interface? physical ports within the EtherChannel group cannot have a PACL applied to them.
PACLs cannot be applied to a switch virtual interface (SVI) or to a routed port. An SVI is a virtual interface that is used as a gateway on a multilayer switch. SVIs can be used to route traffic across Layer 3 interfaces. However, PACLs can only be applied to Layer 2 switching interfaces. Furthermore, because PACLs operate at Layer 2, they cannot be applied to routed ports, which operate at Layer 3. -
Which of the following flags in the output of the show ip mroute command indicates that a receiver is directly connected to the network segment that is connected to the interface? (Select the best answer.)
- A
- C
- D
- L
- S
Explanation:
The C flag in the output of the show ip mroute command indicates that a receiver is directly connected to the network segment that is connected to the interface. You can view the IP multicast routing table by issuing the show ip mroute command, as shown in the following output:

350-401 Part 03 Q14 036 The A flag in the flags field would indicate that the router is a candidate for Multicast Source Discovery Protocol (MSDP) advertisement. However, if the A flag is specified in the outgoing interface list, as shown in the previous output, the router is the winner of an assert mechanism and therefore becomes the forwarder.
The D flag would indicate that the router is using dense mode. The L flag would indicate that the local router is a member of the multicast group. The S flag would indicate that the router is using sparse mode. -
Which of the following is true regarding the structure of a VPN ID? (Select the best answer.)
- It begins with a 4-byte VPN index and ends with a 6-byte MAC address.
- It begins with an 8-byte RD and ends with a 4-byte IPv4 address.
- It begins with a 4-byte IPv4 address and ends with a 3-byte OUI.
- It begins with a 3-byte OUI and ends with a 4-byte VPN index.
- It begins with a 6-byte MAC address and ends with a 4-byte IPv4 address.
Explanation:
A virtual private network (VPN) ID begins with a 3byte Organizationally Unique Identifier(OUI) and ends with a 4byte VPN index. The VPN ID identifies a VPN routing and forwarding (VRF). To update a VPN ID for a VRF, issue the vpn id oui: vpn-index command from VRF configuration mode.
Although a Media Access Control (MAC) address contains an OUI, a VPN ID does notcontain a MAC address. A VPN ID also does not contain a route distinguisher (RD) or an
IPv4 address. However, a multiprotocol Border Gateway Protocol (BGP) VPNIPv4 address begins with an 8byte RD and ends with a 4byte IPv4 address. -
DRAG DROP
Select each BGP command on the left, and drag it o its corresponding description on the right.
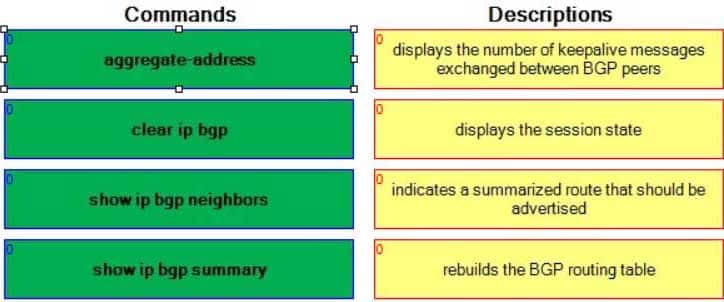
350-401 Part 03 Q16 037 Question 
350-401 Part 03 Q16 037 Answer Explanation:
The show ip bgp neighbors command displays the number of keepalive messages exchanged between Border Gateway Protocol (BGP) peers. The keepalive statistics are displayed within the Message statistics block of output. Additional information provided by the show ip bgp neighbors command includes detailed neighbor path, prefix, capability, and attribute information.
The following is sample output from the show ip bgp neighbors command:

350-401 Part 03 Q16 038 The clear ip bgp command rebuilds the BGP routing table. This command can be used to begin soft reconfiguration or a hard reset. Soft reconfiguration uses stored prefix information in order to rebuild BGP routing tables without breaking down any active peering sessions, whereas a hard reset breaks down the active peering sessions and then rebuilds the BGP routing tables.
The aggregateaddress command indicates a summarized route that should be advertised. The syntax of the aggregateaddress command is aggregateaddressipaddresssubnetmask [summaryonly] [asset]. Typically, the aggregateaddresscommand is issued with the optional summaryonly keyword, which prevents the advertisement of routes with longer prefixes within the summarized range. The optional asset keyword enables BGP to detect loops by generating an aggregate address mathematically from a set of autonomous systems (ASes). You can determine whether an aggregate address has been calculated from a set of ASes by examining the output of the show ip bgp command. For example, the following output displays an aggregate address that summarizes AS 600 by using paths through AS 500 and AS 400:
350-401 Part 03 Q16 039 The show ip bgp summary command displays the session state. You can also use the show ip bgp summary command to determine neighbor path, prefix, capability, and attribute information. If the output indicates that network entries and path entries are consuming a lot of memory, the BGP database might be too large; this can occur when the router is attempting to store the entire global BGP routing table. The following is sample output from the show ip bgp summary command:

350-401 Part 03 Q16 040 -
Which nodes are available in a two-node OpenStack architecture? (Select 2 choices.)
- the compute node
- the controller node
- the network node
- the server node
Explanation:
The compute node and the controller node are available in a two-node OpenStack architecture. OpenStack is an opensource cloud computing platform. Each OpenStack modular component is responsible for a particular function, and each component has a code name. The following list contains several of the most popular OpenStack components:
-Nova -OpenStack Compute: manages pools of computer resources
-Neutron -OpenStack Networking: manages networking and addressing
-Cinder -OpenStack Block Storage: manages blocklevel storage devices
-Glance -OpenStack Image: manages disk and server images
-Swift -OpenStack Object Storage: manages redundant storage systems
-Keystone -OpenStack Identity: is responsible for authentication
-Horizon -OpenStack Dashboard: provides a graphical user interface (GUI)
-Ceilometer -OpenStackTelemetry: provides counterbased tracking that can be used for customer usage billingThe compute node in a twonode OpenStack architecture consists of the following services:
-Nova Hypervisor
-Kernelbased Virtual Machine (KVM) or Quick Emulator (QEMU)
-Nova Networking
-Ceilometer AgentThe controller node in a twonode OpenStack architecture consists of the following services:
-Keystone
-Glance
-Nova Management
-Horizon
-Cinder
-Swift
-Ceilometer CoreA threenode OpenStack architecture adds the network node and offloads networking functionality to the Neutron component. The network node consists of several Neutron services:
-Neutron Modular Layer 2 (ML2) PlugIn
-Neutron Layer 2 Agent
-Neutron Layer 3 Agent
-Neutron Dynamic Host Configuration Protocol (DHCP) AgentThe compute node in a threenode OpenStack architecture removes Nova Networking and adds the Neutron Layer 2 Agent and the Neutron ML2 PlugIn. The controller node in a threenode OpenStack architecture adds the Neutron Server and the Neutron ML2 PlugIn.
-
Which of the following statements are correct regarding NETCONF? (Select 2 choices.)
- NETCONF is an opensource cloudcomputing platform.
- NETCONF is a connectionless protocol.
- NETCONF is a standardsbased protocol.
- NETCONF uses XML as the data modeling language.
- NETCONF uses YANG as the data modeling language.
Explanation:
Network Configuration Protocol (NETCONF) is a standards based protocol that uses YANG as the data modeling language. NETCONF, which is described in Request for Comments (RFC) 6241, provides the ability to automate the configuration of network devices. YANG, which is defined in RFC 6020, is a hierarchical data modeling language that can model configuration and state data for NETCONF.
NETCONF does not use Extensible Markup Language (XML) as the data modeling language? NETCONF uses XML as its data encoding method. YANG data that is used by NETCONF is encoded in an XML format.
NETCONF is not a connectionless protocol. Rather, it is a connection oriented protocol that requires a persistent, reliable connection. NETCONF connections must also provide confidentiality, integrity, authentication, and replay protection. Secure Shell (SSH) is the mandatory transport protocol for NETCONF.
NETCONF is not an opensource cloud computing platform. OpenStack is an opensource cloud computing platform. Each OpenStack modular component is responsible for a particular function, and each component has a code name. The following list contains several of the most popular OpenStack components:-Nova -OpenStack Compute: manages pools of computer resources
-Neutron -OpenStack Networking: manages networking and addressing
-Cinder -OpenStack Block Storage: manages block level storage devices
-Glance -OpenStack Image: manages disk and server images
-Swift -OpenStack Object Storage: manages redundant storage systems
-Keystone -OpenStack Identity: is responsible for authentication
-Horizon -OpenStack Dashboard: provides a graphical user interface (GUI)
-Ceilometer -Open Stack Telemetry: provides counter based tracking that can be used for customer usage billing -
Which of the following benefits is provided by fog computing? (Select the best answer.)
- It filters data before it goes to the cloud.
- It ensures reliable connectivity to the cloud.
- It allows more data to be stored in the cloud.
- It allows data to be transmitted to the cloud faster.
Explanation:
Fo computing filters data before it goes to the cloud. Fog computing is a method designed to alleviate the challenges of processing the data generated by Internet of Things (IoT) devices and transmitting that data to the cloud. IoT devices, which are often called embedded devices or smart objects, are typically lowpower, lowmemory devices with limited processing capabilities. These devices are used in a variety of applications, such as environmental monitoring, healthcare monitoring, process automation, and location tracking. Many embedded devices can transmit data wirelessly, and some are capable of transmitting over a wired connection. However, connectivity is generally unreliable and bandwidth is often constrained.
Io devices are numerous, and they produce a lot of data. For example, an airplanegenerates 10 terabytes (TB) of data for every 30 minutes of flight, and a tagged cow can generate an average of 200 megabytes (MB) of data per year. However, IoT devices often do not have the processing power to analyze the data, nor do they have the power or bandwidth to transmit a lot of data. Fog computing addresses these concerns by storing, processing, and filtering IoT data locally, sending only critical information to the cloud.
Fo computing does not ensure reliable connectivity to the cloud. However, because fogcomputing handles most of the data locally, security and resiliency of the data are increased.
Fo computing does not allow more data to be stored in the cloud. However, because fogcomputing processes and filters data before it is sent to the cloud, the cloud storage space can be filled with relevant data rather than irrelevant, unprocessed data.
Fo computing does not allow data to be transmitted to the cloud faster. However, because fog computing selectively chooses only the most relevant data to send to the cloud, more bandwidth is freed up for data to be sent. -
You administer the IS-IS network shown in the exhibit above.

350-401 Part 03 Q20 041 A DIS has been elected on the multiaccess segment.
Which of the following routers will be the DIS after you connect RouterE to the multiaccess segment? (Select the best answer.)- RouterA
- RouterB
- RouterC
- RouterD
- RouterE
Explanation:
RouterE will be the designated intermediate system (DIS) after you connect it to the multiaccess segment. The Intermediate SystemtoIntermediate System (IS-IS) DIS is analogous to the Open Shortest Path First (OSPF) designated router (DR). All ISIS routers on the network segment establish adjacencies with the DIS. The DIS serves as a focal point for the distribution of ISIS routing information. If the DIS is no longer detected on the network, a new DIS is elected based on the priority of the remaining routers on the network segment.
The DIS for the multiaccess segment is the router with the highest interface priority. To configure the priority of an interface, you should issue the isis priority command from interface configuration mode. The syntax of the isis priority command is isis priorityvalue [level1 | level2], where value is an integer from 0 through 127. A router with an interface priority of 0 can still become the DIS. If you do not issue the isis prioritycommand on an interface, the default interface priority is 64.
If interface priority values are equal, the router with the highest Media Access Control (MAC) address becomes the DIS if the multiaccess segment is a LAN. If the multiaccess segment is a Frame Relay link, the router with the highest datalink connection identifier (DLCI) becomes the DIS. If the DLCI is the same at both ends, the router with the higher system ID becomes the DIS. Every ISIS router is required to have a unique system ID. If two ISIS routers have the same system ID, an ISIS neighbor relationship will not form.
Unlike the DR in OSPF, the DIS in ISIS can be preempted if a router with a higher priority or a higher MAC address is connected to the network. In this scenario, all of the routers have the same interface priority. Therefore, the router with the highest MAC address becomes the DIS. Before RouterE is connected, RouterD is the DIS because it has the highest MAC address. However, after RouterE is connected, RouterE becomes the DIS because RouterE has a higher MAC address than RouterD.
Neither RouterA, RouterB, nor RouterC will become the DIS unless you increase the interface priority for that router’s interface. Loopback addresses and interface IP addresses are not considered in the election of the DIS.