350-401 : Implementing Cisco Enterprise Network Core Technologies (ENCOR) : Part 05
-
Which of the following can be monitored by the EEM IOSWDSysMon core event publisher? (Select the best answer.)
- abnormal stop events
- memory utilization
- syslog messages
- timed events
- counter thresholds
Explanation:
Memory utilization can be monitored by the Embedded Event Monitor (EEM) Watchdog System Monitor (IOSWDSysMon) core event publisher. Watchdog System Monitor can also be configured to monitor CPU utilization.
EEM consists of three components: the EEM server, event publishers, and event subscribers. EEM event detectors are event publishers; EEM policies are event subscribers. When an event is detected, EEM can perform various actions, such as generating a Simple Network Management Protocol (SNMP) trap or reloading the router.
Abnormal stop events are monitored by the system manager event detector. Syslog messages are monitored by the syslog event detector. Timed events are monitored by the timer event detector. Counter thresholds are monitored by the counter event detector. All of these event detectors are considered to be EEM core event publishers. -
Which of the following are characteristics of GLBP? (Select 2 choices.)
- One router is elected as the active router, and another router is elected as the standby router.
- One router is elected as the master router, and all other routers are placed in the backup state.
- All routers in a GLBP group can participate by forwarding a portion of the traffic.
- In a GLBP group, only one AVG and only one AVF can be assigned.
- In a GLBP group, only one AVG can be assigned but multiple AVFs can be assigned.F. In a GLBP group, multiple AVGs can be assigned but only one AVF can be assigned.
Explanation:
The following are characteristics of Gateway Load Balancing Protocol (GLBP):
-All routers in a GLBP group can participate by forwarding a portion of the traffic.
-Only one active virtual gateway (AVG) can be assigned in a GLBP group, but multiple active virtualforwarders (AVFs) can be assigned in a GLBP group.
GLBP is a Cisco proprietary protocol used to provide router redundancy and load balancing. GLBP enables you to configure multiple routers into a GLBP group; the routers in the group receive traffic sent to a virtual IP address that is configured for the group. Each GLBP group contains an AVG that is elected based on which router is configured with the highest priority value or the highest IP address value if multiple routers are configured with the highest priority value.
The other routers in the GLBP group are configured as primary or secondary AVFs. The AVG assigns a virtual Media Access Control (MAC) address to up to four primary AVFs; all other routers in the group are considered secondary AVFs and are placed in the listen state. The virtual MAC address is always 0007.b400.xxyy, where xx is the GLBP group number and yy is the AVF number.
When the AVG receives Address Resolution Protocol (ARP) requests that are sent to the virtual IP address for the GLBP group, the AVG responds with different virtual MAC addresses. This provides load balancing, because each of the primary AVFs will participate by forwarding a portion of the traffic sent to the virtual IP address. If one of the AVFs fails, the AVG assigns the AVF role to another router in the group. If the AVG fails, the AVF with the highest priority becomes the AVG; by default, preemption is disabled.
Additionally, you can control the percentage of traffic that is sent to a specific gateway by configuring weighted load balancing. By default GLBP uses a roundrobin technique to load balance between routers. If you configure weighted load balancing, GLBP can send a higher percentage of traffic to a single GLBP group member based on the weight values assigned to the interfaces of that member.
The election of an active router and a standby router are characteristics of Hot Standby Router Protocol (HSRP), not GLBP. Like GLBP, HSRP provides router redundancy. However, only one router in an HSRP group is active at any time. If the active router becomes unavailable, the standby router becomes the active router.
The election of a master router and the placement of all other routers in the group into the backup state are characteristics of Virtual Router Redundancy Protocol (VRRP). Like GLBP and HSRP, VRRP provides router redundancy. However, similar to HSRP, only one router is active at any time. If the master router becomes unavailable, one of the backup routers becomes the master router.
A GLBP group can contain only one AVG. All other routers in the group are configured as AVFs; multiple AVFs can be configured in a GLBP group. -
Which of the following DSCP values has a binary value of 101110? (Select the best answer.)
- AF11
- AF23
- AF42
- CS1
- CS5
- EF
Explanation:
The Differentiated Services Code Point (DSCP) value EF has a binary value of 101110, which is equal to a decimal value of 46. DSCP values are sixbit header values that identify the Quality of Service (QoS) traffic class that is assigned to the packet. The Expedited Forwarding (EF) per-hop behavior (PHB), which is defined in Request for Comments (RFC) 2598, indicates a high-priority packet that should be given queuing priority over other packets but should not be allowed to completely monopolize the interface. Voice over IP (VoIP) traffic is often assigned a DSCP value of EF.
DSCP values beginning with CS are called Class Selector (CS) PHBs, which are defined in RFC 2475. CS values are backward compatible with three-bit IP precedence values; the first three bits of the DSCP value correspond to the IP precedence value, and the last three bits of the DSCP value are set to 0. Packets with higher CS values are given queuing priority over packets with lower CS values. The following table displays the CS values with their binary values, decimal values, and IP precedence category names:

350-401 Part 05 Q03 056 DSCP values beginning with AF are called Assured Forwarding (AF) PHBs, which are defined in RFC 2597. AF separates packets into four queue classes and three drop priorities. The AF values are specified in the format AFxy, where x is the queue class and y is the drop priority. The following table displays the AF values with their queue classes and drop rates:

350-401 Part 05 Q03 057 The first three DSCP bits correspond to the queue class, the fourth and fifth DSCP bits correspond to the drop priority, and the sixth bit is always set to 0. To quickly convert AF values to decimal values, you should use the formula 8x + 2y. For example, AF42 converts to a decimal value of 36, because (8 x 4) + (2 x 2) = 32 + 4 = 36.
Packets with higher AF values are not necessarily given preference over packets with lower AF values. Packets with a higher queue class value are given queuing priority over packets with a lower queue class, but packets with a higher drop rate value are dropped more often than packets with a lower drop rate value. -
You administer the network in the topology diagram.

350-401 Part 05 Q04 058 All routers are running EIGRP. All interface delay values are set to their defaults. On each active interface, the ip route cache command and the no ip routecache cef command have been configured.
The variance 2 command has been issued on RouterA.
An IP address of 192.168.51.50 has been assigned to the FastEthernet 1/0 interface on RouterC.
You issue the show ip route 192.168.51.50 command on RouterA and receive the following output:
350-401 Part 05 Q04 059 Which of the following is indicated by the asterisk in the output? (Select the best answer.)
- The path through RouterB is the active path for a new flow.
- The path through RouterB is the active path for a new packet.
- The path through RouterB is the active path for the next flow and the next packet.
- The path through RouterB is down, so the traffic can only flow through RouterD.
- The path through RouterD is the active path for a new flow.
- The path through RouterD is the active path for a new packet.
- The path through RouterD is the active path for the next flow and the next packet.
- The path through RouterD is down, so the traffic can flow through only RouterB.
Explanation:
The asterisk in the output of the show ip route 192.168.51.50 command indicates that the path through RouterD, which is connected to RouterA’s Serial 0/0 interface, is the active path for a new destinationbased flow to 192.168.51.50. RouterA is performing per-destination load balancing, which is a type of load balancing that decides where to send packets based on the destination address of the packet. Therefore, the path of the network flow, which is a sequence of packets, is decided based on the destination address.
Per-destination load balancing typically occurs when fast switching is enabled on a router. In this scenario, the ip routecache command has been issued on each active interface on RouterA. In addition, Cisco Express Forwarding (CEF), which can be configured to use either per-destination load balancing or perpacket load balancing, has been disabled on each interface. Therefore, RouterA is fastswitching packets.
When an asterisk appears in the output of the show ip route ip address command on a router that is performing perdestination load balancing, it is an indicator that the next flow to the destination specified by ipaddress will flow over the path indicated by the asterisk. Therefore, the following line of output indicates that traffic to the destination of 192.168.51.50 will flow through RouterD because RouterD is connected to RouterA’s Serial 0/0 interface:* 192.168.1.2, from 192.168.1.2, 00:00:16 ago, via Serial0/0
In this scenario, Enhanced Interior Gateway Routing Protocol (EIGRP) on RouterA is performing unequalcost load balancing of traffic to the destination network of 192.168.51.0 by sending some traffic over RouterB and some traffic over RouterD. Packets for a different destination address on the same network as 192.168.51.50 in this scenario might flow over RouterB instead.
You can determine the number of destinations that are likely to flow over RouterB as compared to RouterD by examining the Traffic share count line of the output from the show ip route 192.168.51.50 command. In this scenario, 120 per-destination flows will flow over RouterD for every 97 per-destination flows that flow over RouterB. This number can also be represented as a traffic flow ratio of 97:120. A Cisco router calculates the traffic flow for a load-balanced path by dividing each path’s metric into the largest metric and rounding down to the nearest integer. That integer becomes the traffic share count value for that path. You can influence the traffic flow ratio of load-balanced paths by adjusting the delay values of interfaces along the paths.
Neither the path through RouterB nor the path through RouterD is load balancing packets, because RouterA is not process switching packets. However, if process switching were enabled, RouterA would load balance the path to the 192.168.51.0/24 network by varying the packets sent over each path instead of varying the destination based flows. Although perpacket load balancing guarantees that an equal amount of traffic will traverse each link, packets could arrive out of order at their destinations.
Neither the path through RouterB nor the path through RouterD is down. When a path learned by a dynamic routing protocol goes down, the path is removed from the routing table. For example, if the path through RouterD were down in this scenario, the output of the show ip route 192.168.51.50 command on RouterA would display only the path through RouterB, as shown in the following output: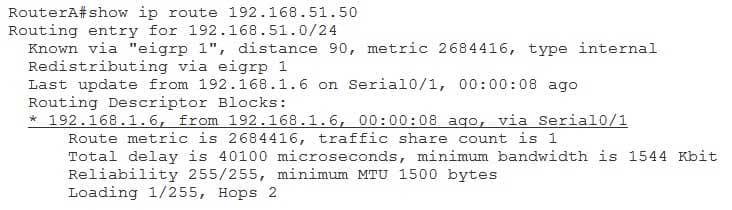
350-401 Part 05 Q04 060 -
You administer the BGP network in the following exhibit:
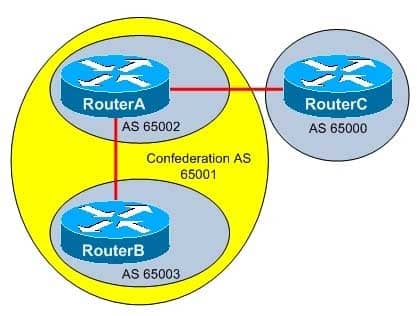
350-401 Part 05 Q05 061 Between which routers can the cost community attribute be passed? (Select the best answer.)
- between all of the routers in this scenario
- between none of the routers in this scenario
- only between RouterA and RouterB
- only between RouterA and RouterC
Explanation:
The Border Gateway Protocol (BGP) cost community attribute can be passed only between RouterA and RouterB. The cost community, which is a nontransitive extended community, is passed only between internal BGP (iBGP) and confederation peers? it is not sent to external BGP (eBGP) peers. When multiple equalcost paths exist, the path with the lowest cost community number is preferred.
To configure the cost community attribute in a route map, you should issue the set extcommunity costcommunityidcostvalue command from routemap configuration mode. The community ID, which is defined by the communityid variable, is a value from 0 through 255. The cost, which is defined by the costvalue variable, is a value from 0 through 4294967295, with a default value of half of the maximum, or 2147483647. If two paths have the same cost, the path with the lowest community ID will be preferred.
When aggregate routes or multipaths are used and several component routes use the same community ID, the highest cost is applied to the aggregate or multipath route. If one or more of the component routes do not carry the cost community attribute or are configured with different community IDs, the default value of 2147483647 is applied to the aggregate or multipath route. -
Which of the following OSPFv3 LSA types is an intraareaprefix LSA? (Select the best answer.)
- Type 3
- Type 4
- Type 5
- Type 8
- Type 9
Explanation:
Open Shortest Path First version 3 (OSPFv3) Type 9 linkstate advertisements (LSAs) are intraareaprefix LSAs. OSPFv3 Type 9 LSAs carry IPv6 prefix information, much like OSPF version 2 (OSPFv2) Type 1 and Type 2 LSAs carry IPv4 prefix information. In OSPFv3, Type 1 and Type 2 LSAs no longer carry route prefixes. LSAs carry only routing information; they do not contain a full network topology. Both Type 9 LSAs and Type 8 LSAs are new in OSPFv3.
OSPFv3 Type 8 LSAs are link LSAs. Type 8 LSAs are used to advertise the router’s linklocal IPv6 address, prefix, and option information. These LSAs are never flooded outside the local link.
OSPFv3 Type 3 LSAs are interareaprefix LSAs for area border routers (ABRs). Type 3 LSAs are used to advertise internal networks to other areas. Like Type 9 LSAs, Type 3 LSAs also carry IPv6 prefix information.
OSPFv3 Type 4 LSAs are interarearouter LSAs for autonomous system boundary routers (ASBRs). Type 4 LSAs are used to advertise the location of an ASBR so that routers can determine the best nexthop path to an external network.
OSPFv3 Type 5 LSAs are autonomous system (AS)external LSAs. Type 5 LSAs are used to advertise external routes that are redistributed into OSPF. -
You are creating an account for a new administrator. The administrator should only be allowed to configure IP addresses and view the running configuration.
Which of the following actions should you perform? (Select the best answer.)
- Create an ACL so that the administrator has access to the proper commands.
- Configure the administrator’s user account with a privilege level of 1.
- Configure the administrator’s user account with a privilege level of 6.
- Configure the administrator’s user account with a privilege level of 15.
- Create a rolebased CLI view, and associate it with the administrator’s user account.
Explanation:
You should create a rolebased commandline interface (CLI) view and associate it with the administrator’s user account. Like privilege levels, rolebased CLI views limit the IOS commands that a user can access. However, rolebased CLI views provide administrators with greater detail and flexibility in restricting command access.
Before you can create rolebased CLI views, you must first ensure that Authentication, Authorization, and Accounting (AAA) is enabled on the router by issuing the aaa newmodel command. You should then enable the root view by using the enable viewcommand. The root view contains commands equivalent to privilege level 15. Before you can configure any other CLI views, you must enable the root view.
To create a rolebased CLI view, you should issue the parser viewviewname command, which specifies the view name and places the device into parser view configuration mode. Prior to specifying any commands for the view, you must secure the view with a password by issuing the secretpassword command. After you have secured the view, you can issue one or more commands that allow or restrict access to parts of the IOS. The basic syntax of the commands command is commandsparsermode {include | includeexclusive | exclude} [all] [command]. The parsermode variable is used to indicate the mode in which the command exists. For example, the exec keyword indicates privileged EXEC mode, and the configure keyword indicates global configuration mode. The includekeyword indicates that the command should be added to this view. The exclude keyword indicates that the command should be denied to this view. The includeexclusivekeyword indicates that the command should be added to this view but not to any other superviews that might include this view? a superview is a view that consists of one or more rolebased CLI views. The all keyword indicates that all subcommands that begin with the specified command keywords should be included.
After you have created a view, you can apply it to a user account by issuing the username name viewviewnamepassword password command. You can also test the view by issuing the enable viewviewname command and issuing the password that you specified with the password password keywords. Commands that are not available for the user’s view will not appear in the command list in contextsensitive help. Attempting to issue a command that is not included in a user’s view will display an error message just as if the command did not exist on the router, as shown in the following output:Router>enable view NEWADMIN Password: Router#configure terminal ^ % Invalid input detected at '^' marker.
Privilege levels can be also used to limit access to CLI commands. However, you are limited to 16 privilege levels, some of which are used by default by the IOS. For example, privilege level 0 includes only the disable, enable, exit, help, and logout commands. Each privilege level contains a list of commands that are available at that level. Users assigned to a privilege level have access to all of the commands at that privilege level and all lower privilege levels. Changing the commands that are available to a privilege level might provide access to a user who should not be allowed access to the command, or it might restrict access to another user who should be allowed access to the command.
Configuring the administrator’s user account with a privilege level of 1 will not enable the administrator to configure IP addresses and to view the running configuration. Privilege level 1 allows a user to issue any command that is available at the user EXEC > prompt.
Configuring the administrator’s user account with a privilege level of 6 will not enable the administrator to configure IP addresses and to view the running configuration unless you have first configured privilege level 6 with the proper commands. By default, no commands are assigned to privilege level 6.
Configuring the administrator’s user account with a privilege level of 15 will enable the administrator to configure IP addresses and to view the running configuration. However, it will also provide access to all other commands that are available at the privileged EXEC #prompt. This will provide more access to the IOS than you want the administrator to have.
Access control lists (ACLs) can be used to limit administrative access to a router. However, you cannot limit access to particular IOS commands by using an ACL. -
What is the default timer setting for the IGMPv2 group membership timeout? (Select the best answer.)
- one second
- 10 seconds
- 255 seconds
- 260 seconds
Explanation:
The Internet Group Management Protocol version 2 (IGMPv2) group membership timeout is set to a value of 260 seconds by default. The group membership timeout is the amount of time a router will wait before deciding that a group has no multicast sources or hosts on the network. To configure the group membership timeout, issue the ip igmp grouptimeoutseconds command.
The IGMPv2 last member query response interval is set to a value of one second by default. The last member query is the amount of time a router will wait after receiving a leave message from the last group member before sending a response and deleting the group. To configure the last member query response interval, issue the ip igmp lastmemberqueryresponsetime seconds command.
The IGMPv2 query max response time is set to a value of 10 seconds by default. The query max response time is the maximum response time advertised in IGMP queries. To configure the query max response time, issue the ip igmp querymaxresponsetime secondscommand.
The IGMPv2 querier timeout, which is also referred to as the other querier present interval, is set to a value of 255 seconds by default. The querier timeout is the number of seconds that a router will wait after the querier has stopped transmitting before the router will take over the querier role. To configure the querier timeout, issue the ip igmp querytimeoutseconds command or the ip igmp queriertimeoutseconds command. -
By default, how often are MAC addresses flushed from the CAM table? (Select the best answer.)
- after three minutes of no activity from that address
- after five minutes of no activity from that address
- after 10 minutes of no activity from that address
- after 300 minutes of no activity from that address
Explanation:
By default, Media Access Control (MAC) addresses are flushed from the Content Addressable Memory (CAM) table after five minutes of inactivity from that address. The CAM table provides a list of known hardware addresses and their associated ports on the switch. After the integrity of a frame has been verified, the switch searches the CAM table for an entry that matches the frame’s destination MAC address. If the frame’s destination MAC address is not found in the table, the switch forwards the frame to all its ports, except the port from which it received the frame. If the destination MAC address is found in the table, the switch forwards the frame to the appropriate port. The source MAC address is also recorded if it did not previously exist in the CAM table.
By default, MAC addresses are flushed from the CAM table after 300 seconds of no activity from that address, not 300 minutes. The mac-address-table aging-time seconds command can be used to change the frequency with which MAC addresses are flushed from the CAM table. In order to have MAC addresses flushed from the CAM table after three minutes of inactivity, you should issue the macaddresstable agingtime 180 command. Likewise, you should issue the macaddresstable agingtime 600 command for the addresses to be flushed after 10 minutes of inactivity. -
You administer the networks shown above.
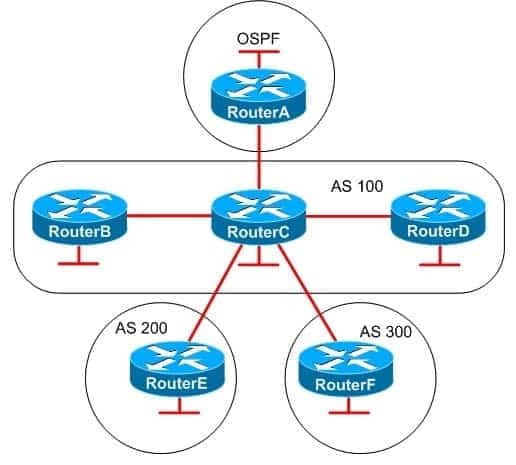
350-401 Part 05 Q10 062 RouterA is connected to network A, RouterB is connected to network B, and so on. RouterB and RouterD are iBGP peers of RouterC; RouterE and RouterF are eBGP peers of RouterC. RouterA and RouterC are OSPF neighbors.
RouterC, which is not configured as a route reflector, receives routes from all of the other routers on the network. You have issued the network command on each router to advertise their respective networks. You have also issued the redistribute command on RouterC to redistribute the OSPF routes from RouterA into BGP.
Routes to which of the following networks will RouterC advertise to RouterF? (Select the best answer.)- only network C
- only networks B, C, and D
- only networks A, B, C, and D
- only networks A, B, C, D, and E
- networks A, B, C, D, E, and F
Explanation:
RouterC will advertise only networks A, B, C, D, and E to RouterF. RouterC and RouterF are external Border Gateway Protocol (eBGP) peers, which are BGP routers that belong to different autonomous systems (ASes). An eBGP peer advertises the following routes to another eBGP peer:-Routes learned through internal BGP (iBGP)
-Routes learned through eBGP
-Routes learned through redistribution
-Routes originated by a network statementThe only route that RouterC will not advertise to RouterF is network F, because RouterC originally learned of the route from RouterF. When RouterF advertises network F to RouterC, RouterF adds the AS number (ASN) to the AS_PATH. Routes with an AS_PATH that contains the ASN of a BGP peer are not advertised back to that peer.
If RouterF were in AS 100, RouterF and RouterC would be iBGP peers. The BGP split horizon rule states that routes learned through iBGP are not advertised to iBGP peers. Therefore, an iBGP peer advertises the following routes to another iBGP peer:
-Routes learned through eBGP
-Routes learned through redistribution
-Routes originated by a network statementBecause iBGP routes are not advertised to iBGP peers, one of the following actions must be taken to enable routers running iBGP to communicate:
-Configure a full mesh.
-Configure a confederation.
-Configure a route reflector.A full mesh configuration enables each router to learn each iBGP route independently without passing through a neighbor. However, a full mesh configuration requires the most administrative effort to configure. A confederation enables an AS to be divided into discrete units, each of which acts like a separate AS. Within each confederation, the routers must be fully meshed unless a route reflector is established. A route reflector can be used to pass iBGP routes between iBGP routers, eliminating the need for a full mesh configuration. However, it is important to note that route reflectors advertise best paths only to route reflector clients. Additionally, if multiple paths exist, a route reflector will always advertise the exit point that is closest to the route reflector.
-
You are connecting host computers to a switch with 10/100/1000Mbps Gigabit Ethernet ports. All of the ports are configured to autonegotiate speed and duplex settings.
Which of the following will cause a mismatch condition? (Select the best answer.)
- connecting a NIC that is configured for halfduplex, 100Mbps operation
- connecting a NIC that is configured for fullduplex, 100Mbps operation
- connecting a NIC that is configured for fullduplex, 1000Mbps operation
- connecting a NIC that is configured to autonegotiate duplex and speed settings
Explanation:
Connecting a network interface card (NIC) that is configured for fullduplex, 100Mbps operation will cause a mismatch condition because the duplex modes on the NIC and on the port will be different. A NIC that has been manually configured to use fullduplex or halfduplex mode does not respond to a port that is attempting to autonegotiate duplex settings. When the autonegotiating port receives no reply, it will use the default duplex settings for that speed. If the port detects that it should transmit at 10 Mbps or 100 Mbps, the port will default to halfduplex mode? if the port detects that it should transmit at 1000 Mbps, the port will default to fullduplex mode.
You can detect a duplex mismatch by monitoring a switch for %CDP-4-DUPLEXMISMATCH error messages. Additionally, you can issue the show interfacesinterface command, which displays counter information. If you see an abnormal increase in frame check sequence (FCS) errors and alignment errors on a halfduplex port, you should suspect a duplex mismatch. An abnormal increase in FCS errors and runts on a fullduplex port is also an indicator of a duplex mismatch.
Connecting a NIC that is configured for halfduplex, 100Mbps operation will not cause a mismatch condition.
The port will detect that it should transmit at 100 Mbps; therefore, it will default to halfduplex mode. Configuring both switch ports for halfduplex mode would enable only one port to send data at a time; however, communication could still occur, albeit slowly.
Connecting a NIC that is configured for fullduplex, 1000Mbps operation will not cause a mismatch condition. The port will detect that it should transmit at 1000 Mbps; therefore, it will default to fullduplex mode.
Connecting a NIC that is configured to autonegotiate duplex and speed settings will not cause a mismatch condition. When both sides of a link autonegotiate speed settings, they will select the highest speed common to both of them. When both sides of a link autonegotiate duplex settings, they will negotiate fullduplex mode if both ports support fullduplex operation. If either side of the link does not support fullduplex operation, the ports will negotiate halfduplex mode. -
Which of the following CHAP packets contains a Code field that is set to a value of 4? (Select the best answer.)
- Challenge
- Failure
- Response
- Success
Explanation:
A Challenge Handshake Authentication Protocol (CHAP) Failure packet contains a Code field that is set to a value of 4. A CHAP packet consists of the following fields:
-A oneoctet Code field
-A oneoctet Identifier field, which helps to match challenges to responses
-A twooctet Length field,which indicates the length of the packet
-One or more fields that are determined by the Code fieldA Challenge packet has a Code field that is set to a value of 1. It also has the following additional fields:
-A oneoctet ValueSize field, which indicates the length of the Value field
-A variablelength ChallengeValue field, which contains a variable, unique stream of octets
-A variablelength Name field, which identifies the name of the transmitting deviceA Response packet has a Code field that is set to a value of 2. It also has the following additional fields:
-A oneoctet ValueSize field, which indicates the length of the Response Value field
-A variablelength Response Value field, which contains a concatenated oneway hash of the ID, the secret key, and the Challenge Value
-A variablelength Name field, which identifies the name of the transmitting device
A Success packet has a Code field that is set to a value of 3. In addition to the standard fields, the Success packet and the Failure packet have a variablelength Message field, which displays a success or failure message, typically in humanreadable ASCII characters. -
You administer the network shown in the exhibit above.

350-401 Part 05 Q13 063 You enable root guard by issuing the spanning-tree guard root command in interface configuration mode for the Fa0/0 interfaces of S2 and S3.
Which of the following statements best describes what will occur if the link between S1 and S2 is broken? (Select the best answer.)
- Traffic will follow its normal path from Host2 to S1.
- The Fa0/0 port on both switches will be put into the root-inconsistent state.
- Only Fa0/0 on S2 will be put into the root-inconsistent state.
- Only Fa0/0 on S3 will be put into the root-inconsistent state.
- STP will be disabled.
Explanation:
If the link between S1 and S2 is broken, the Fa0/0 port on S2 will be placed into the root-inconsistent state. Root guard is typically used to prevent a designated port from becoming a root port, thereby influencing which bridge will become the root bridge on the network. When root guard is applied to a port, the port is permanently configured as a designated port. Normally, a port that receives a superior bridge protocol data unit (BPDU) will become the root port. However, if a port configured with root guard receives a superior BPDU, the port transitions to the rootinconsistent state and no data will flow through that port until it stops receiving superior BPDUs. As a result, root guard can be used to influence the placement of the root bridge on a network by preventing other switches from propagating superior BPDUs throughout the network and becoming the root bridge.
When the root bridge detects the broken link, it will send out BPDUs to reconverge the network topology. Since root guard was enabled on Fa0/0 on S2, the interface will be placed into the rootinconsistent state when it receives superior BPDUs from Fa0/0 on S3. Thus root guard prevents Fa0/0 on S2 from being selected as a root port. The port will remain in the rootinconsistent state until it stops receiving superior BPDUs from Fa0/0 on S3.
Fa0/0 on S3 will not be placed into the rootinconsistent state, because it will not receive superior BPDUs from S2. S3 will continue to receive superior BPDUs from S1.
Traffic would not follow its normal path from Host2 to the root bridge if the link between S1 and S2 were broken. When the link between S1 and S2 is up, traffic from Host2 travels from S4 to S2 to S1. This is based on the root path cost. The root path cost is an accumulation of path costs from bridge to bridge. A Fast Ethernet link has a path cost of 19. There are two 100Mbps paths, so the root path cost from S4 to S2 to S1 equals 38. The root path cost from S4 to S3 to S1 also equals 38. If the root path cost is identical, the bridge ID is used to determine the path. In this scenario, S2 has a priority of 32768, as does S3. However, the Media Access Control (MAC) address for S2, 000000000002, is lower than the MAC address for S3, 000000000003, making S2 the designated bridge. If the link between S1 and S2 breaks, the path for traffic coming from Host2 will be rerouted from its normal path to the S4 to S3 to S1 path.
Spanning Tree Protocol (STP) would not be disabled if the link between S1 and S2 were to break. It is STP that reconverges the network topology to reroute traffic after a link in the root path becomes disabled. -
You administer a router that contains five routes to the same network: an eBGP route, an ISIS route, a RIP route, an OSPF route, and an internal EIGRP route. The default ADs are used.
Which route does the router prefer? (Select the best answer.)
- the eBGP route
- the ISIS route
- the RIP route
- the OSPF route
- the EIGRP route
Explanation:
The router prefers the external Border Gateway Protocol (eBGP) route. When multiple routes to a network exist and each route uses a different routing protocol, a router prefers the routing protocol with the lowest administrative distance (AD). The following list contains the most commonly used ADs:
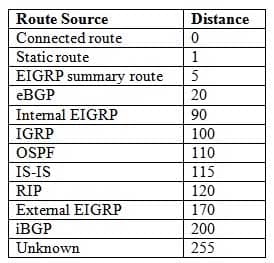
350-401 Part 05 Q14 064 If the eBGP route were to fail, the internal Enhanced Interior Gateway Routing Protocol (EIGRP) route would be preferred, because EIGRP has an AD of 90. If the EIGRP route were also to fail, the Open Shortest Path First (OSPF) route would be preferred, because OSPF has an AD of 110. If the OSPF route were also to fail, the Intermediate SystemtoIntermediate System (ISIS) route would be preferred, because ISIS has an AD of 115. The Routing Information Protocol (RIP) route would not be used unless all of the other links were to fail, because RIP has an AD of 120.
ADs for a routing protocol can be manually configured by issuing the distance command in router configuration mode. For example, to change the AD of RIP from 120 to 80, you should issue the following commands:RouterA(config)#router rip RouterA(configrouter)#distance 80
If you were to modify the AD of RIP by issuing the distance command, the RIP route would be preferred before the EIGRP route but after the eBGP route.
You can view the AD of the best route to a network by issuing the show ip routecommand. The AD is the first number inside the brackets in the output. For example, the following router output shows an OSPF route with an AD of 160:Router#show ip route Gateway of last resort is 10.19.54.20 to network 10.140.0.0 O E2 172.150.0.0 [160/5] via 10.19.54.6, 0:01:00, Ethernet2
-
Which of the following statements is true regarding Cisco IOS EPC? (Select the best answer.)
- Each capture point can be associated with multiple capture buffers.
- Multiple capture points can be active on a single interface.
- The buffer type and sampling interval are the only settings you can adjust when creating a capture buffer.
- The packet data contains a timestamp indicating when the packet was added to the buffer.
Explanation:
Multiple capture points can be active on a single interface. Cisco IOS Embedded Packet Capture (EPC) is a feature that you can implement to assist with tracing packets and troubleshooting issues with packet flow in and out of Cisco devices. To implement Cisco IOS EPC, you must perform the following steps:1.Create a capture buffer.
2.Create a capture point.
3.Associate the capture point with the capture buffer.
4.Enable the capture point.The buffer type and sampling interval are not the only settings you can adjust when creating a capture buffer; you can also adjust several other items, including the buffer size and the packet capture rate. Specifying the sampling interval and the buffer type will allow for the maximum number of pertinent packets to be stored in the buffer. To configure a capture buffer, you should issue the monitor capture bufferbuffername [clear | exportexportlocation | filteraccesslistipaccesslist | limit {allownthpaknthpacket | duration seconds | packetcounttotalpackets | packetspersec packets} | [maxsize elementsize] [sizebuffersize] [circular | linear]] command from global configuration mode.
The capture buffer contains packet data and metadata. The packet data does not contain a timestamp indicating when the packet was added to the buffer; the timestamp is contained within the metadata. In addition, the metadata contains information regarding the direction of transmission of the packet, the switch path, and the encapsulation type.
To create a capture point, you should issue the monitor capture point {ip | ipv6} {cefcapturepointname interfacename interfacetype {both | in | out} | processswitched capturepointname {both | fromus | in | out}} command from global configuration mode. You can create multiple capture points with unique names and parameters on a single interface.
To associate a capture point with a capture buffer, you should issue the monitor capture point associatecapturepointname capturebuffername command from global configuration mode. Each capture point can be associated with only one capture buffer. Finally, to enable the capture point so that it can begin to capture packet data, you should issue the monitor capture point start {capturepointname | all} command. -
Which of the following connects more than two UNIs and enables each UNI to communicate with every other UNI in the configuration? (Select the best answer.)
- E-LAN
- EPL
- E-Tree
- EVPL
Explanation:
An ELAN service connects more than two User Network Interfaces (UNIs) and enables each UNI to communicate with every other UNI in the configuration. An ELAN is a multipointtomultipoint Ethernet virtual connection (EVC). A UNI is the physical demarcation between a service provider and a subscriber. ELAN services fully mesh two or more UNIs and follow a specific set of rules for delivering service frames to a UNI. Each UNI in an ELAN can communicate with any other UNI in the ELAN. ELANs typically have a distance limitation of 50 miles (80 kilometers). Layer 2 Virtual Private Networks (L2VPNs) and multipoint L2VPNs are examples of ELANs.
Both Ethernet private line (EPL) and Ethernet virtual private line (EVPL) are Eline services. Eline services are Ethernet pointtopoint EVC services that can be used to connect two UNIs. Therefore, an Eline does not connect more than two UNIs. The difference between an EPL and an EVPL is that an EVPL is capable of service multiplexing. In addition, an EPL requires full service frame transparency. An EVPL does not.
An ETree is a pointtomultipoint EVC that resembles a hubandspoke configuration. Therefore, an ETree does not enable each UNI to communicate with every other UNI in the configuration. An ETree service connects more than one UNI to a single root UNI or leaf UNI. Root UNIs can send data to any leaf UNI. However, a leaf UNI can send traffic only to a root UNI. ETrees are typically used to provide Internet access to multiple sites. -
Which of the following potential BGP enhancements were documented in the BGP Add-Paths proposal? (Select the best answer.)
- possible modifications to the best-path algorithm
- possible software upgrades for PE routers
- possible addition of a session between a route reflector and its client
- possible addition of a four-octet Path Identifier
Explanation:
The BGP Add-Paths proposal proposed the possible addition of a four-octet Path Identifier to Network Layer Reachability Information (NLRI) in order to enable Border Gateway Protocol (BGP) to distribute multiple paths. BGP as it is typically deployed has no mechanism for distributing paths that are not considered the best path between speakers.
Observations about the possible addition of a session between a router reflector and its client were documented in Request for Comments (RFC) 6774, which discusses the distribution of diverse BGP paths. Specifically, RFC 6774 observed that BGP as it is typically deployed has no mechanism for distributing paths that are not considered the best path between speakers. However, the possible addition of a session between a route reflector and its client could enable a BGP router to distribute alternate paths.
Neither the AddPaths proposal nor RFC 6774 document possible modifications to the bestpath algorithm or software upgrades for provider edge (PE) routers. Although RFC 6774 does discuss a possible means of distributing paths other than the best path, the means by which BGP determines the best path to a destination were not changed. Therefore, no software upgrade is required. -
You administer the OSPF network shown in the diagram.
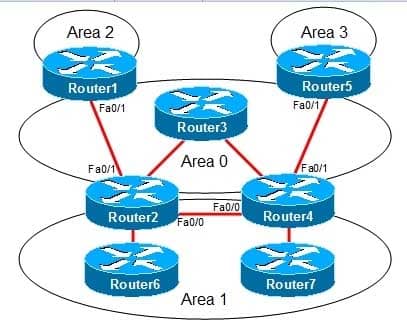
350-401 Part 05 Q18 065 Area 1 is configured as a standard area. Area 2 and Area 3 are configured as stub areas. Router3 fails. Several routes are lost throughout the network.
Which of the following actions can you take to restore the lost routes? (Select 2 choices.)- Configure Area 1 as a stub area.
- Configure Area 2 and Area 3 as standard areas.
- Create a virtual link between Router1 and Router5.
- Create a virtual link between Router2 and Router4.
- Configure the Fa0/0 interfaces on Router2 and Router4 to be part of Area 0.
- Configure the Fa0/1 interfaces on Router2 and Router4 with IP addresses that were configured onRouter3.
Explanation:
You can take either of the following actions to restore the lost routes:
– Create a virtual link between Router2 and Router4.
– Configure the Fa0/0 interfaces on Router2 and Router4 to be part of Area 0.In this scenario, the backbone area, Area 0, has become discontinuous, or partitioned, as shown in the following network diagram:
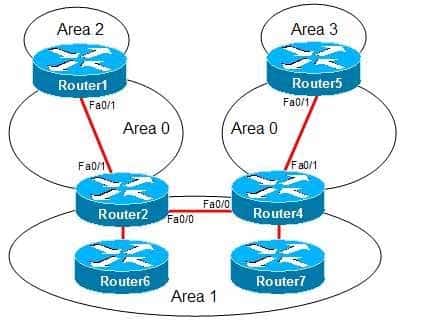
350-401 Part 05 Q18 066 To connect a backbone area that has become discontinuous because of the loss of a router or the loss of a link between two routers, you can create a virtual link. The routers at each end of the virtual link must adhere to the following restrictions:
– Both routers must connect to the backbone area.
– Both routers must share another common area, which is used as a transit area.
– The transit area cannot be a stub area.
– The transit area cannot be the backbone area.To create a virtual link, you should issue the area area-id virtual-link router-id command in router configuration mode on the routers at each end of the virtual link, where area-id is the transit area ID and routerid is the router ID of the router at the other end of the virtual link. For example, if the router ID of Router4 were 1.2.3.4, you would issue the area 1 virtual-link 1.2.3.4 command on Router2. You would also issue a similar command on Router4 by using the router ID of Router2 as the router-id parameter.
Alternatively, you can configure the Fa0/0 interfaces on Router2 and Router4 to be part of Area 0. Doing so would make Area 1 discontinuous. This is acceptable because interarea traffic must pass through the backbone or a transit area; therefore, nonbackbone areas can be discontinuous. The discontinuous Area 1 partitions would be advertised to one another through inter-area routes instead of intra-area routes.
Configuring Area 1 as a stub area will not restore the lost routes. Additionally, configuring Area 1 as a stub area eliminates the possibility of using a virtual link to connect the discontinuous backbone areas.
Configuring Area 2 and Area 3 as standard areas will not restore the lost routes. Changing a stub area to a standard area will only allow Type 5 external summary routes to be advertised throughout the area.
You cannot create a virtual link between Router1 and Router5. For a virtual link to be created, both routers must share a common area. If Router1 and Router5 shared a nonstub area, you could create a virtual link between them and the lost routes would be restored.
Configuring the Fa0/1 interfaces on Router2 and Router4 with IP addresses that were configured on Router3 will not restore the lost routes. The routes were not lost because of the unavailability of the IP addresses on Router3; the routes were lost because of the discontinuous backbone area. -
Which of the following ICMPv6 message types is sent by an IPv6capable host at startup? (Select the best answer.)
- router solicitation
- router advertisement
- neighbor solicitation
- neighbor advertisement
Explanation:
An Internet Control Message Protocol version 6 (ICMPv6) router solicitation message is sent by an IPv6capable host at startup. When IPv6 is enabled on a router interface, a linklocal address is created. Before the address is assigned to the interface, duplicate address detection (DAD) is performed to determine whether the IPv6 address is unique on the link. If DAD determines that the address is unique, the linklocal address is assigned to the interface and the router solicitation message is sent to the allrouters multicast address FF02::2. Hosts use router solicitation messages to request an immediate router advertisement.
A router advertisement that is sent in response to a router solicitation message is sent directly to the host that sent the router solicitation. Routers also send unsolicited router advertisements periodically to the allnodes multicast address FF02::1. Router advertisements contain the following information:– The IPv6 address of the router interface attached to the link
– One or more IPv6 prefixes for the local link
– The lifetime for each prefix
– Flags that specify whether stateless or stateful autoconfiguration can be used
– The hop limit and maximum transmission unit (MTU) that the host should use
– Whether the router is a default router
– The amount of time that the router can be used as a default routerWhen a host receives a router advertisement, the IPv6 link-local prefix is added to the host’s interface identifier to create the host’s full IPv6 address. The first three octets of the interface identifier are set to the Organizationally Unique Identifier (OUI) of the Media Access Control (MAC) address of the interface. The fourth and fifth octets are set to FFFE. The sixth, seventh, and eighth octets are equal to the last three octets of the MAC address.
A host will send a neighbor solicitation message to determine the link-layer address of another host on the local link. Neighbor solicitation messages are sent with the sender’s own link-layer address to the solicited-node multicast address. The solicited-node multicast address is created by adding the FF02::1:FF00/104 prefix to the last 24 bits of the destination host’s IPv6 address. After a destination host’s link-layer address is discovered, neighbor solicitations can be used to verify the reachability of a destination host.
When a host receives a neighbor solicitation message, it will reply with a neighbor advertisement message that contains the link-layer address of the host. The neighbor advertisement is sent directly to the host that sent the neighbor solicitation. A host will send an unsolicited neighbor advertisement whenever its address changes. Unsolicited neighbor advertisements are sent to the allnodes link-local multicast address FF02::1. -
Which of the following is true regarding RTC? (Select the best answer.)
- RTC sends only the prefixes that the PE router wants.
- RTC finds route inconsistencies.
- RTC synchronizes peers without a hard reset.
- RTC works with only VPNv4.
- RTC makes the ABR an RR and sets the next hop to self.
Explanation:
Route Target Constraint (RTC) sends only the prefixes that the Provider Edge (PE) router wants. In a normal Multiprotocol Label Switching (MPLS) virtual private network (VPN), the route reflector (RR) sends all of its VPN version 4 (VPNv4) and VPNv6 prefixes to the PE router. The PE router then drops the prefixes for which it does not have a matching VPN routing and forwarding (VRF). RTC allows a PE router to send its route target (RT) membership data to the RR within an address family named rtfilter. The RR then uses rtfilter to determine which prefixes to send to the PE. In order for RTC to work, both the RR and the PE need to support RTC.
RTC does not find route inconsistencies, nor does it synchronize peers without a hard reset. This functionality is provided by Border Gateway Protocol (BGP) Enhanced Route Refresh.
BG Enhanced Route Refresh is enabled by default. If two BGP peers support EnhancedRoute Refresh, each peer will send a RouteRefresh StartofRIB (SOR) message and a RouteRefresh EndofRIB (EOR) message before and after an AdjRIBOut message, respectively. After a peer receives an EOR message, or after the EOR timer expires, the peer will check to see whether it has any routes that were not readvertised. If any stale routes remain, they are deleted and the route inconsistency is logged.
RTC does not make the area border router (ABR) an RR, nor does it set the next hop to self. This behavior is exhibited by Unified MPLS. Unified MPLS increases scalability for an MPLS network by extending the label switched path (LSP) from end to end, not by redistributing interior gateway protocols (IGPs) into one another, but by distributing some of the IGP prefixes into BGP. BGP then distributes those prefixes throughout the network.