350-601 : Implementing and Operating Cisco Data Center Core Technologies (DCCOR) : Part 02
-
A UCS administrator connects Fabric Interconnect A’s Layer 1 and Layer 2 high availability ports to Fabric Interconnect B’s Layer 1 and Layer 2 high availability ports. In addition, the administrator connects Fabric Interconnect A’s Mgmt 0 port to a switch. Fabric Interconnect B’s Mgmt 0 port remains disconnected. No FC connections have been made between Fabric Interconnect A and Fabric Interconnect B.
Which of the following statements about the Fabric Interconnect cluster is true?
- Failover will work, and link-level redundancy is available.
- Failover will not work, because no FC connections have been made.
- Failover will not work, because no Ethernet connections have been made.
- Failover will work, but there will be no link-level redundancy.
Explanation:
Cisco Unified Computing System (UCS) Fabric Interconnect failover will work, but there will be no link-level redundancy. In this scenario, the UCS administrator connects two Cisco Fabric Interconnects, A and B, together by using each device-s Layer 1 and Layer 2 high availability ports. This configuration is known as a Fabric Interconnect cluster.
Each Fabric Interconnect in a cluster is capable of monitoring the status of the Fabric Interconnect to which it is connected. If Fabric Interconnect A fails, Fabric Interconnect B can take over the duties of Fabric Interconnect A. If Fabric Interconnect B fails, Fabric Interconnect A can take over the duties of Fabric Interconnect B.
Link-level redundancy is not available in this scenario because only Mgmt 0 port on Fabric Interconnect A has been connected to a switch. In a Fabric Interconnect cluster, it is possible to connect only one device’s Mgmt 0 port to a switch to enable management of the entire cluster. However, the connection of both Mgmt 0 ports ensures link-level redundancy in case of failure of one of the devices.
Failover will work even though there are no Fibre Channel (FC) connections between the devices in this scenario. A Fabric Interconnect cluster requires that no FC connections exist between the cluster members. Therefore, connecting the two Fabric Interconnects by using FC connections is more likely to prevent failover that to facilitate it.
Ethernet connections have been made in this scenario. The Layer 1 and Layer 2 high availability ports on the first Fabric Interconnect are connected to the Layer 1 and Layer 2 high availability ports on the second Fabric Interconnect by using Ethernet cables. The Layer 1 high availability port on the first device should connect to the Layer 1 high availability port on the second device. Likewise, the Layer 2 high availability port on the first device should connect to the Layer 2 high availability port on the second device. -
You are creating a workflow in UCS Director’s Workflow Designer. You have connected each task’s On Failure event in the workflow to the completed (failed) task. You need to connect each task’s On Success event to the appropriate task.
Which of the following tasks are you most likely to choose?
- start
- completed (failed)
- completed (success)
- the next task in the workflow
Explanation:
Of the available choice, you are most likely to connect each task’s On Success event to the next task in the workflow. Workflows determine the order in which tasks that are designed to automate complex IT operations are performed. Workflow Designer allows administrators to create workflows that can be automated by using Unified Computing System (UCS) Director’s orchestrator.
The following Cisco UCS Director’ Workflow Designer tasks are predefined when creating a workflow:
– Completed (failed)
– Completed (success)
– Start
The start task is the beginning of the workflow. The completed (failed) task represents the end of a workflow when the desired result could not be achieved. The completed (success) task represent a successfully completed workflow. Each task in a workflow processes input and produces output that is sent to the next task in the workflow. In addition, each task contains an On Success event and an On Failure event that can be used to determine which task should be performed next based on whether the task could be successfully completed. On Success events should be connected to the next task in the workflow. On Failure events, on the other hand, should be connected to the completed (failed) task so that the workflow does not attempt to perform more tasks that would rely on successful output from the previously failed task. -
Which of the following statements about Layer 3 virtualization on a Cisco Nexus 7000 Series switch is true?
- A VRF represents a Layer 2 addressing domain.
- Each VRF can belong to multiple VDCs.
- Each Layer 3 interface is configured in one VRF.
- Each VDC can be configured with only one VRF.
Explanation:
Each Layer 3 interface on a Cisco Nexus 7000 Series switch can be configured with only one virtual routing and forwarding (VRF) instance. In other words, a Layer 3 interface that has been assigned to a given VRF cannot be simultaneously assigned to another VRF. There are two VRF instances configured on a Nexus 7000 Series switch by default: the management VRF and the default VRF. The management VRF is used only for management, includes only the Mgmt 0 interface, and uses only static routing. The default VRF, on the other hand, includes all Layer 3 interfaces until you assign those interfaces to another VRF.
A VRF instance represents an Open Systems Interconnection (OSI) networking model Layer 3 addressing domain, not a Layer 2 addressing domain. VRFs are used to logically separate OSI networking model Layer 3 networks. The address space, routing process, and forwarding table that are used within a VRF are local to that VRF.
Each VRF on a Cisco Nexus 7000 Series switch can belong to only one virtual device context (VDC). However, each VDC can be configured with multiple VRFs. A VDC is a virtual switch. Therefore, a VDC is a logical representation of a physical device on which VRFs can be configured. -
You are examining the following command-line output on a Nexus 7000 Series switch:
vdc_id: 2 vdc_name: acctg interfaces: Ethernet2/1
Which of the following have you most likely issued?
- the show vdc command in the default VDC
- the show vdc detail command in a nondefault VDC
- the show vdc command in a nondefault VDC
- the show vdc detail command in the default VDC
- the show vdc membership command in a nondefault VDC
Explanation:
Most likely, you have issued the show vdc membership command in a nondefault virtual device context (VDC) if you see the command-line output in this scenario on a Nexus 7000 Series switch. The show vdc membership command displays the interfaces that have been allocated to VDCs on the physical device, as shown in the following output:
NEX7S#show vdc membership vdc_id: 2 vdc_name: acctg interfaces: Ethernet2/1
Based on the output above, you can surmise that the command was issued in a nondefault VDC. The output displays information for only the VDC named acctg. If the command had been issued in the default VDC, the output would have displayed information about the interfaces assigned to every VDC that is configured on the physical device.
It is not likely that you have issued the show vdc command in this scenario. The show vdc command displays information about VDCs configured on the physical switch. However, the output of the show vdc command depends on the VDC in which the command has been issued. When issued in the default VDC, the command displays output for all VDCs configured on the device, as shown in the following output:NEX7S#show vdc vdc_id vdc_name state mac --------- -------- ------ --------------- 1 sales active A8:CC:D8:D8:65:F4 2 acctg active 7F:52:92:26:29:CF 3 prod active 7B:05:CA:ED:41:E1
When issued in a nondefault VDC, the command displays output for only the current VDC, as shown in the following output:
NEX7S#show vdc vdc_id vdc_name state mac --------- -------- ------ --------------- 1 sales active A8:CC:D8:D8:65:F4
To issue read and write commands in the default VDC, a user must be assigned the network-admin user role. The network-operator role has read-only access to the default VDC. Users that have been assigned the vdc-admin role can review output from the show vdc command in the nondefault VDC in which they are operating. However, they do not have rights to read or write information in other VDCs.
It Is not likely that you have issued the show vdc detail command in this scenario. Similar to the show vdc command, the show vdc detail command displays information about the VDCs configured on the physical device. However, the show vdc detail command provides extra information about the VDCs that is not visible in the summarized show vdc command output. For example, the output of the show vdc detail command contains information about the VDC ha policy, boot order, create time, and restart count in addition to the VDC ID, name, state, and Media Access Control (MAC) address. Also similar to the show vdc command, the show vdc detail command displays output for all VDCs when the command is issued in the default VDC. When issued in a nondefault VDC, the command displays output only for the VDC in which it was issued. -
Which of the following examples best describes the SaaS service model?
- A company obtains a subscription to use a service provider’s infrastructure, programming tools, and programming languages to develop and serve cloud-based applications.
- A company moves all company-wide policy documents to an internet-based virtual file system hosted by a service provider.
- A company hires a service provider to deliver cloud-based processing and storage that will house multiple virtual hosts configured in a variety of ways.
- A company licenses an office suite, including email service, that is delivered to the end user through a web browser.
Explanation:
A company that licenses an office suite, including email service, that is delivered to the end user through a web browser is an example of the Software as a Service (SaaS) service model. The National Institute of Standards and Technology (NIST) defines three service models in its definition of cloud computing: SaaS, Infrastructure as a Service (IaaS), and Platform as a Service (PaaS). Cloud computing offers several benefits over traditional physical infrastructure and software licensing, including a reduction in downtime and administrative overhead.
The SaaS service model enables its consumer to access applications running in the cloud infrastructure but does not enable the consumer to manage the cloud infrastructure or the configuration of the provided applications. A company that licenses a service provider’s office suite and email service that is delivered to end users through a web browser is using SaaS. SaaS providers use an Internet-enabled licensing function, a streaming service, or a web application to provide end users with software that they might otherwise install and activate locally. Web-based email clients, such as Gmail and Outlook.com, are examples of SaaS.
The PaaS service model provides its consumer with a bit more freedom than the SaaS model by enabling the consumer to install and possibly configure provider-supported applications in the cloud infrastructure. A company that uses a service provider’s infrastructure, programming tools, and programming languages to develop and serve cloud-based applications is using PaaS. PaaS enables a consumer to use the service provider’s development tools or Application Programming Interface (API) to develop and deploy specific cloud-based applications or services. Another example of PaaS might be using a third party’s MySQL database and Apache services to build a cloud-based customer relationship management (CRM) platform.
The IaaS service model provides the greatest degree of freedom by enabling its consumer to provision processing, memory, storage, and network resources within the cloud infrastructure. The IaaS service model also enables its consumer to install applications, including operating systems (OSs) and custom applications. However, with 1aaS, the cloud infrastructure remains in control of the service provider. A company that hires a service provider to deliver cloud-based processing and storage that will house multiple physical or virtual hosts configured in a variety of ways is using IaaS. For example, a company that wanted to establish a web server farm by configuring multiple Linux Apache MySQL PHP (LAMP) servers could save hardware costs by virtualizing the farm and using a provider’s cloud service to deliver the physical infrastructure and bandwidth for the virtual farm. Control over the OS, software, and server configuration would remain the responsibility of the organization, whereas the physical infrastructure and bandwidth would be the responsibility of the service provider.
A company that moves all company-wide policy documents to an Internet-based virtual file system hosted by a third party is using cloud storage. Cloud storage is a term used to describe the use of a service provider’s virtual file system as a document or file repository. Cloud storage enables an organization to conserve storage space on a local network. However, cloud storage is also a security risk in that the organization might not have ultimate control over who can access the files. -
You are installing a Cisco Nexus 1000v VSM in VMware vSphere by using the OVF folder method of installation.
Which of the following steps are you required to manually perform? (Choose four.)
- perform initial VSM setup
- add hosts
- install VSM plug-in
- configure VSM networking
- create the VSM
- configure SVS connection
Explanation:
You are required to manually perform the initial virtual supervisor module (VSM) setup, install the VSM plug-in, configure the server virtualization switch (SVS) connection, and add hosts. In this scenario, you are using the open virtualization format (OVF) folder method of installation. This method of installation automatically performs the first two steps of the six-step installation process. An OVF folder contains a hierarchy of files with different metadata that together define a given virtual environment.
There are three methods of installing the Nexus 1000v VSM:
– By using an International Standards Organization (ISO) image
– By using an OVF folder and installation wizard
– By using an open virtualization appliance (OVA) file and installation wizard
No matter which installation method is chosen, the VSM installation process consists of the following six steps:
– Creation of the VSM virtual machine (VM) in Cisco vCenter
– Configuration of VSM networking
– Initial VSM setup in the VSM console
– Installation of the VSM plug-in in vCenter
– Configuration of the SVS connection in the VSM console
– Addition of hosts to the virtual distributed switch in vCenter
The steps in this process that you are required to perform manually depend on the method of installation that you choose.
The OVA file method of installing the Nexus 1000v VSM is similar to the OVF folder method. However, the OVA file method performs the first four steps of the installation process. This means that you are required to manually configure the SVS connection in the VSM console and add hosts to the virtual distributed switch in vCenter. However, the first four steps in the process are performed automatically after you deploy the OVA by using the installation wizard. The primary difference between an OVA file and an OVF folder is that the OVA file is a single compressed archive.
The ISO image method of installing the Nexus 1000v VSM requires that you manually perform each of the six steps in the installation process. An ISO image file contains a virtual filesystem that can be mounted by an operating system (OS) similar to an optical disc or a Universal Serial Bus (USB) flash drive. -
Which of the following is true of the mgmt 0 interface?
- Only this interface can be a member of the management VRF.
- By default, it is assigned to the default VRF.
- It can be assigned to any VRF.
- It is used only by the default VDC.
Explanation:
Only the mgmt 0 interface can be a member of the management virtual routing and forwarding (VRF) instance. The management VRF is used only for management. No routing protocols are allowed to run in the management VRF, and all routing is static. The management VRF includes only the mgmt 0 interface, which cannot be assigned to any other VRF. However, the mgmt 0 interface is shared among virtual device contexts (VDCs).
VRFs are used to logically separate Open Systems Interconnection (OSI) networking model Layer 3 networks. Therefore, it is possible to have overlapping Internet Protocol version 4 (IPv4) or Internet Protocol version 6 (IPv6) addresses in environments that contain multiple tenants. However, an interface that has been assigned to a given VRF cannot be simultaneously assigned to another VRF. The address space, routing process, and forwarding table that are used within a VRF are local to that VRF. By default, a Cisco router is configured with two VRFs: the management VRF and the default VRF.
A Cisco router’s default VRF instance is similar to a router’s global routing table. The default VRF includes all Layer 3 interfaces until you assign those interfaces to another VRF. Similarly, the default VRF runs any routing protocols that are configured unless those routing protocols are assigned to another VRF. All show and exec commands that are issued in the default VRF apply to the default routing context. -
You want to examine an inventory of fabric interconnect expansion modules as identified in the Cisco UCS Manager GUI
Which of the following Navigation pane tabs should you click?
- Servers
- SAN
- LAN
- Admin
- VM
- Equipment
Explanation:
You should click the Equipment tab in the Cisco Unified Computing System (UCS) Manager graphical user interface (GUI) if you want to examine an inventory of fabric interconnect expansion modules. Cisco UCS Manager GUI is a Java application. The main area of the GUI is divided into a Navigation pane and a work area. The selections you click in the Navigation pane determine the information and configuration fields that are displayed in the work area.
The Navigation pane of the Cisco UCS Manager GUI contains six tabs in a row across the top of the pane. To configure or view a given element of Cisco UCS Manager, you should first click the Navigation pane tab appropriate for that element. The Navigation pane contains all of the following tabs:
– The Equipment tab
– The Servers tab
– The LAN tab
– The SAN tab
– The VM tab
– The Admin tab
The Equipment tab can be used to display an inventory of the UCS domain. This information includes color-coded fault indicators, such as a red, yellow, or orange rectangle. If a device has a fault, one of these indicators will appear around the name of the device on the Equipment tab. The Equipment tab contains four nodes: Equipment, Chassis, Rack-mounts, and Fabric Interconnects. Selected nodes contain information specific to the devices indicated by the node name. For example, the Fabric Interconnects node contains information about expansion modules, fans, and power supply units (PSUs) connected to the domain’s fabric interconnects.
The Servers tab can be used to modify server-specific configurations, such as policies, profiles, and universally unique identifier (UUID) pools. The Servers tab contains six nodes: Servers, Service Profiles, Service Profile Templates, Policies, Pools, and Schedules. Selected nodes contain information specific to the server configurations indicated by the node name. For example, the Policies node allows the configuration of policies related to server adapters, server firmware, and other components.
The LAN tab can be used to configure local area network (LAN) components, such as Quality of Service (QoS) classes, virtual LANs (VLANs), and flow control policies. The LAN tab contains seven nodes: LAN Cloud, Appliances, Internal LAN, Policies, Pools, Traffic Monitoring Sessions, and Netflow Monitoring. Selected nodes contain information specific to the LAN component indicated by the node name. For example, the Pools node allows the configuration of both Internet Protocol (IP) address pools and Media Access Control (MAC) address pools that have been defined for a LAN.
The SAN tab can be used to configure storage area network (SAN) components, such as virtual SANs (vSANs), and World Wide Name (WWN) pools. The SAN tab contains six nodes: SAN, SAN Cloud, Storage Cloud, Policies, Pools, and Traffic Monitoring Sessions. Selected nodes contain information specific to the SAN component indicated by the node name. For example, the SAN node allows the configuration of SAN uplinks, Fibre Channel (FC) address assignments, and vSANs.
The VM tab can be used to configure virtual machine-fabric extender (VM-FEX) for UCS domain servers that are equipped with virtual interface cards (VICs). The VM tab contains seven nodes: All, Clusters, Fabric Network Sets, Port Profiles, VM Networks, Microsoft, and VMware. Selected nodes contain information specific to the VM component indicated by the node name. For example, the VMware node can be used to configure Cisco UCS Manager connections to VMware vCenter.
The Admin tab can be used to configure system-wide settings that must be configured by an administrator or viewed by a security administrator. The Admin tab contains 10 nodes:
– All
– Faults, Events and Audit Log
– User Management
– Key Management
– Communication Management
– Stats Management
– Time Zone Management
– Capability Catalog
– Management Extension
– License Management
Selected nodes contain information specific to the administrative component indicated by the node name. For example, the User Management node allows the configuration of authentication methods and user roles as well as remote access methods. -
You issue the following command on a Cisco Nexus 7000 switch:
vrf context default
Which of the following is most likely to occur?
- A new VDC named default will be created.
- A new VRF instance named default will be created.
- The switch will return an error because the default VRF already exists.
- The switch will be placed into VRF configuration mode for an existing VRF.
Explanation:
Most likely, the switch will be placed into virtual routing and forwarding (VRF) configuration mode for the existing default VRF. There are two VRF instances configured on a Nexus 7000 by default: the management VRF and the default VRF. The default VRF includes all Layer 3 interfaces until you assign those interfaces to another VRF. Similarly, the default VRF runs any routing protocols that are configured unless those routing protocols are assigned to another VRF. All show and exec commands that are issued in the default VRF apply to the default routing context. Unless an administrator configures other VRFs on a Nexus 7000, any forwarding configurations that are made by the administrator will operate in the default VRF. The management VRF, on the other hand, is used only for management, includes only the mgmt 0 interface, and uses only static routing.
The vrf context name command can be used to create a new VRF or to enter VRF configuration mode for an existing VRF. Because the Nexus 7000 is already configured with a management VRF, issuing the command in this scenario places the device into VRF configuration mode for that VRF. Similarly, issuing the vrf context management command would place the switch into VRF configuration mode for the existing management VRF.
VRFs are used to logically separate Open Systems Interconnection (OSI) networking model Layer 3 networks. Therefore, it is possible to have overlapping Internet Protocol version 4 (IPv4) or Internet Protocol version 6 (IPv6) addresses in environments that contain multiple tenants. However, an interface that has been assigned to a given VRF cannot be simultaneously assigned to another VRF. The address space, routing process, and forwarding table that are used within a VRF are local to that VRF. -
Which of the following best describes the data plane of a Nexus switch?
- It is where SNMP operates.
- It is where routing calculations are made.
- It is also known as the control plane.
- It is where traffic forwarding occurs.
Explanation:
Of the available choices, the control plane of a Nexus switch is best described as where traffic forwarding occurs. A Nexus switch consists of three operational planes: the control plane, the management plane, and the data plane, which is also known as the forwarding plane. Cut-through switching allows a switch to begin forwarding a frame before the frame has been received in its entirety. Store-and-forward switching receives an entire frame and stores it in memory before forwarding the frame to its destination.
The control plane, not the data plane, of a Nexus switch is where routing calculations are made. Routing protocols such as Enhanced Interior Gateway Routing Protocol (EIGRP), Open Shortest Path First (OSPF), and Border Gateway Protocol (BGP) all operate in the control plane of a Nexus switch. The control plane is responsible for gathering and calculating the information required to make the decisions that the data plane needs for forwarding. Routing protocols operate in the control plane because they enable the collection and transfer of routing information between neighbors. This information is used to construct routing tables that the data plane can then use for forwarding.
The management plane, not the data plane, of a Nexus switch is where Simple Network Management Protocol (SNMP) operates. The management plane is responsible for monitoring and configuration of the control plane. Therefore, network administrators typically interact directly with protocols running in the management plane. -
You are configuring port mirroring on a Cisco switch. You configure a VLAN as the source port. You configure a physical Ethernet port as the destination port.
Which of the following are you most likely configuring? (Choose two.)
- VSPAN
- SPAN
- RSPAN
- ERSPAN
- RAP
Explanation:
Most likely, you are configuring Switched Port Analyzer (SPAN) and virtual local area network (VLAN)-based SPAN (VSPAN) if you enable port mirroring by configuring a VLAN as the source port and a physical Ethernet port as the destination port on the same Cisco switch. SPAN source and destination ports must be on the same device. SPAN is limited to monitoring traffic on only the local device and cannot direct traffic to destination ports on a separate device for analysis. The source port can be a physical or virtual Ethernet port, a port channel, or a VLAN if VSPAN is being used. The destination port can be a physical or virtual Ethernet port or a port channel. However, the source port and the destination port cannot be the same port. All ports in a source VLAN become SPAN source ports. SPAN, Remote SPAN (RSPAN), and Encapsulated RSPAN (ERSPAN) are all capable of using VLANs as sources by implementing VSPAN.
You are not configuring RSPAN in this scenario. RSPAN source and destination ports must be on the same local area network (LAN) but are not restricted to the same device. RSPAN enables you to monitor traffic on a network by capturing and sending traffic from a source port on one device to a destination port on a different device on a nonrouted network.
You are not configuring ERSPAN in this scenario. ERSPAN source and destination ports can exist in different LANs and are not typically configured on the same switch. ERSPAN enables an administrator to capture and analyze traffic across a routed network. Therefore, ERSPAN can monitor traffic across multiple routers on a network that spans multiple locations.
You are not configuring Roving Analysis Port (RAP) in this scenario. RAP is a form of port mirroring that is configured on 3Com switches, not on Cisco devices. -
Examine the Cisco UCS Director Workflow Designer in the following exhibit:
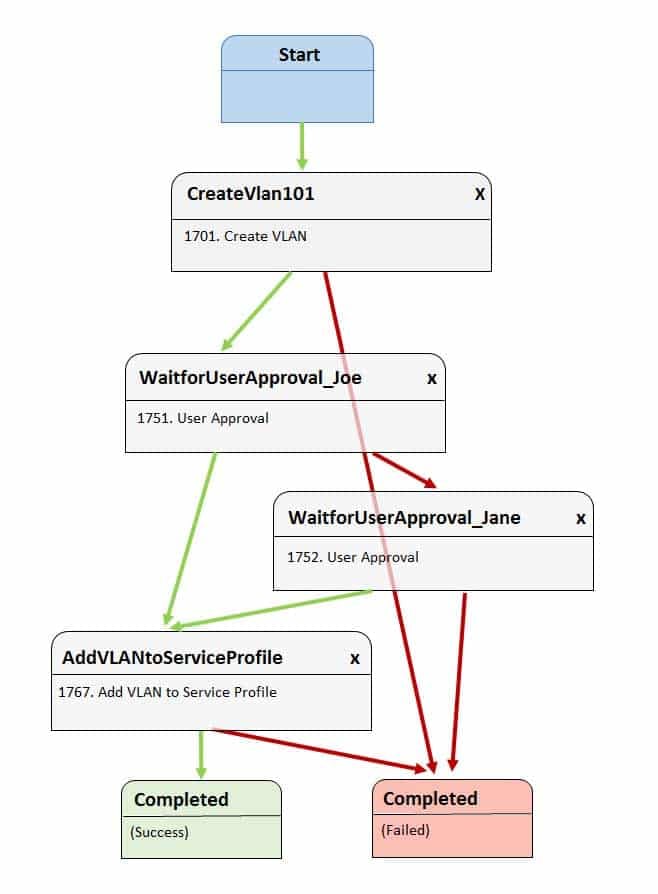
350-601 Part 02 Q12 004 Joe initiates the workflow and approves the addition of the VLAN to the service profile.
Which of the following best describes what will occur next?- VLAN 101 will be added to the service profile if Jane approves.
- VLAN 101 will be successfully added to the service profile.
- VLAN 101 will not be added to the service profile, and the workflow will succeed.
- VLAN 101 will not be added to the service profile, and the workflow will fail.
- VLAN 101 will be sent back to Joe for approval if Jane approves.
Explanation:
Most likely, virtual local area network (VLAN) 101 will be added to the service profile if Joe approves. The Cisco Unified Computing System (UCS) Director Workflow Designer workflow in this scenario creates VLAN 101 after it starts. Before the next task is executed, the workflow requires the approval of a user named Joe. In this scenario, Joe has approved this step. Because Joe’s approval is obtained, the workflow continues to the AddVLANtoServiceProfile task.
Cisco UCS Director Workflow Designer is a graphical user interface (GUI) that enables users to create automated workflows in a drag-and-drop fashion. Each task in a workflow is equipped with an On Success button and an On Failure button. Each button provides a drop-down list of other tasks in the workflow. In this way, the user can select which tasks are executed next if a task succeeds and which tasks are executed next if a task fails. Green arrows in Workflow Designer represent the On Success path. Red arrows represent the On Failure path.
Jane will not be provided with an opportunity to approve or reject in this scenario, because Joe has already approved the workflow. The On Success path of the WaitforUserApproval_Joe task is directly tied to the AddVLANtoServiceProfile task. If Joe had not approved, Jane would have been provided the opportunity to approve or reject because the On Failure path of the WaitforUserApproval_Joe task is tied to the WaitforUserApproval_Jane task. In that case, Jane could approve, which would launch the AddVLANtoServiceProfile task, or reject, which would cause the workflow to end in failure.
There is nothing in this scenario to indicate whether the AddVLANtoServiceProfile task would be successful following Joe’s approval. Therefore, it is not possible to determine whether the workflow will follow that task’s On Success path or its On Failure path. -
Which of the following is not a physical device?
- Nexus 5000 Series
- Nexus 100v Series
- Nexus 9000 Series
- Nexus 2000 Series
- Nexus 7000 Series
Explanation:
Of the available choices, the Cisco Nexus 1000v Series is not a physical device. The Cisco Nexus 1000v is a virtual switch that is capable of connecting to upstream physical switches in order to provide connectivity for a virtual machine (VM) network environment. Although the Cisco Nexus 1000v operates similar to a standard switch, it exists only as software in a virtual environment and is therefore not a physical switch.
The Cisco Nexus 2000 Series of switches are physical devices. However, they are fabric extenders (FEXs) and cannot operate as standalone switches. FEX technologies depend on parent switches, such as a Cisco Nexus 5500 Series switch or a Cisco Nexus 7000 Series switch, to provide forwarding tables and control plane functionality. FEX technologies are intended to extend the network to edge devices. Typically, FEX devices in the Cisco Nexus 2000 Series are managed by first connecting to the parent device by using either Telnet or Secure Shell (SSH) and then configuring the FEX.
Cisco Nexus 5000 Series switches are physical devices that operate as standalone switches. Cisco Nexus 5000 Series switches are data center access layer switches that can support 10-gigabit-per-second (Gbps) or 40-Gbps Ethernet, depending on the model. Native Fibre Channel (FC) and FC over Ethernet (FCoE) are also supported by Cisco Nexus 5000 Series switches.
Cisco Nexus 7000 Series switches are physical devices that operate as standalone switches. Cisco Nexus 7000 Series switches are typically used as an end-to-end data center solution, which means that the series is capable of supporting all three layers of the data center architecture: core layer, aggregation layer, and access layer. In addition, the Cisco Nexus 7000 Series supports virtual device contexts (VDCs). The Cisco Nexus 7000 Series can support up to 100-Gbps Ethernet.
Cisco Nexus 9000 Series switches are physical devices that operate as standalone switches. Cisco Nexus 9000 Series switches can operate either as traditional NX-OS switches or in an Application Centric Infrastructure (ACI) mode. Unlike Cisco Nexus 7000 Series, Cisco Nexus 9000 Series switches do not support VDCs or storage protocols. -
Which of the following Cisco UCS Manager identity pools contains a type of OSI Layer 3 identity?
- WWxN pool
- IP pool
- WWNN pool
- MAC pool
- WWPN pool
Explanation:
Of the available choices, only the Cisco Unified Computing System (UCS) Internet Protocol (IP) identity pool contains a type of Open Systems Interconnection (OSI) Layer 3 identity. IP identity pools contain IP addresses, which are 32-bit decimal addresses that are assigned to OSI Layer 3 interfaces. In a Cisco UCS domain, IP pools are typically used to assign one or more management IP addresses to each server’s Cisco Integrated Management Controller (IMC).
Media Access Control (MAC) identity pools contain MAC addresses, which are OSI Layer 2 48-bit hexadecimal addresses that are typically burned into a network interface card (NIC). The first 24 bits of a MAC address represent the Organizationally Unique Identifier (OUI), which is a value that is assigned by the Institute of Electrical and Electronics Engineers (IEEE). The OUI identifies the NIC’s manufacturer. The last 24 bits of a MAC address uniquely identify a specific NIC constructed by the manufacturer. This value is almost always an identifier that the manufacturer has never before used in combination with the OUI.
A World Wide Node/Port Name (WWxN) identity pool contains Fibre Channel-Layer 2 (FC1) identities. This is because WN identity pools are a combination of World Wide Name (WWN) types: the World Wide Port Name (WWPN) and the World Wide Node Name (WWNN). Unlike other networking technologies, Fibre Channel (FC) does not make use of the OSI network model. Instead, FC uses the FC-Layers model, which is broken out in the following fashion:
– FC4: Protocol mapping layer
– FC3: Common services layer
– FC2: Network layer
– FC1: Data link layer
– FCO: Physical layer
FCO, FC1, and FC2 have similar names and functions to their OSI model equivalents, which are Layer 1, Layer 2, and Layer 3, respectively. FC3 is equivalent to the OSI model’s Transport layer, or Layer 4. FC4, on the other hand, is similar in function to a combination of all three top layers of the OSI model, which are the Session layer (Layer 5), the Presentation layer (Layer 6), and the Application layer (Layer 7).
WWNNs are 64-bit globally unique identifiers that specify a given FC node. These identifiers are typically used to assign FC1 addresses in storage area network (SAN) routing. Similar to the WWNN identity pool, the WWPN identity pool contains globally unique 64-bit identifiers that are used to assign FC1 addresses. However, WWPNs represent a specific FC port, not an entire node. -
Which of the following Cisco Unified Fabric Features can result in reduced cabling?
- VXLANs
- vPCs
- STP
- CNAs
Explanation:
Of the available choices, converged network adapters (CNAs) are the Cisco Unified Fabric feature that can result in reduced cabling. Cisco Unified Fabric is a combination of architecture and high performance concepts that is intended to simplify data center networks. CNAs are network adapters that combine network interface cards (NICs) and host bus adapters (HBAs), enabling one adapter to support both Ethernet and Fibre Channel (FC). A server that contains separate FC and local area network (LAN) ports can require significantly more cabling than a server that is configured with a CNA. Cisco Unified Fabric also helps converge a data center’s LAN and storage area network (SAN) over a single transport in order to simplify management, provisioning, and operation.
Virtual Port Channels (vPCs) do not necessarily result in reduced cabling. A vPC is a Cisco Unified Fabric alternative to a traditional EtherChannel port channel. Therefore, vPCs are intended to create high-bandwidth redundant links between Layer 2 devices. Traditional EtherChannel relies on Spanning Tree Protocol (STP). Port channels that are created by using vPCs still rely on STP to mitigate switching links if they occur, but do not rely on it in the same functional way that EtherChannel does.
Virtual extensible LANs (VXLANs) are not a Cisco Unified Fabric that can result in reduced cabling. VXLANs use Layer 3 technologies to extend Layer 2 technologies. In this way, VXLANs can achieve the same results as Cisco FabricPath without implementing FabricPath. Cisco FabricPath enables the scaling of a Layer 2 network beyond normal practical limitations by using Layer 3 routing protocol Intermediate System-to-Intermediate System (IS-IS) in place of STP.
STP is not a Cisco Unified Fabric feature. Instead, STP is a Layer 2 protocol that is intended to prevent switching loops in a network with redundant links. -
You connect a Cisco 5548UP Nexus switch to a FEX. Next, you install a Cisco 5108 blade server chassis.
Which of the following servers are you least likely to install in this configuration? (Choose two.)
- Cisco UCS C240 M4
- Cisco UCS C220 M4
- Cisco B200 M4
- Cisco B260 M4
- Cisco B420 M4
Explanation:
Of the available choices, you are least likely to install a Cisco Unified Computing System (UCS) C220 M4 server or a Cisco UCS C240 M4 server. The Cisco UCS 5108 is a blade server chassis for Cisco B-Series blade servers. The Cisco 5108 blade server chassis can accommodate eight half-width blade servers or four full-width blade servers. In this scenario, you have installed a Cisco 5108 blade server and connected a Cisco UCS 5548UP Nexus switch to a fabric extender (FEX).
The Cisco UCS C220 M4 and the Cisco UCS C240 M4 are Cisco C-Series rack servers, not Cisco B-Series blade servers. C-Series rack servers are rack-mountable standalone servers and do not require a B-Series server chassis. The Cisco C220 M4 is a 1-rack unit (RU) server that supports a maximum of eight internal disk drives and has a dual 1-gigabit per second (Gbps) and 10-Gbps embedded Ethernet controller. The Cisco UCS C240 M4, on the other hand, is a 2-RU server that supports a maximum of 24 internal disk drives and has a quad 1-Gbps embedded Ethernet controller.
The Cisco B200 M4, Cisco B260 M4, and Cisco B420 M4 are all Cisco B-Series blade servers. Therefore, any of these servers can be installed in the Cisco 5108 blade server chassis. The Cisco B200 M4 server is a half-width blade server that supports up to 80-Gbps throughput. The B260 M4 server is a half-width blade server that supports up to 160-Gbps throughput. The B420 M4 server is also a half-width blade server that supports up to 160-Gbps throughput. However, the B420 M4 server supports 6.4 terabytes (TB) of storage and can be deployed in one of four Redundant Array of Independent Disks (RAID) configurations. The B260 M4 server, on the other hand, supports 2.4 TB of storage and either RAID 0 or RAID 1 configurations. -
Which of the following is typically used for hardware abstraction?
- a VM
- an API
- a hypervisor
- mezzanine card
Explanation:
Of the available choices, only a hypervisor is used for hardware abstraction. A hypervisor is software that has two roles: the abstraction of physical hardware and the creation of virtual machines (VMs). Hypervisors are capable of virtualizing the physical components of computer hardware. Virtualization enables the creation of multiple VMs that can be configured and run in separate instances on the same hardware. Hardware abstraction is the use of software to emulate physical hardware. Hardware abstraction enables device-independent software development and allows a given VM to become portable between physical devices.
A VM is a software environment that behaves as physical computer hardware in that it typically runs a separate operating system (OS) from the host OS. However, a VM does not itself abstract the hardware on which the host OS is installed. VMs provide the hardware environment for guest OSes and the applications they run by making calls to the hypervisor, which then makes calls to either the host OS or the bare-metal server, depending on the type of hypervisor installed on the device.
An Application Programming Interface (API) is typically used to enable an application to perform functions on a remote framework, database, or application. For example, representational state transfer (REST) is an API architecture that uses Hypertext Transfer Protocol (HTTP) or HTTP Secure (HTTPS) to enable external resources to access and make use of programmatic methods that are exposed by the API. A web application that retrieves user product reviews from an online marketplace for display on third-party websites might obtain those reviews by using methods provided in an API that is developed and maintained by that marketplace.
A mezzanine card is a computer hardware component that can be plugged into expansion slots on a main board. Cisco Unified Computing System (UCS) B-Series blade servers use mezzanine cards to add a variety of network interfaces to the system. For example, the Cisco UCS Virtual Interface Card (VIC) 1280 is a mezzanine card that adds 10-gigabit-per-second (Gbps) Ethernet port and Fibre Channel over Ethernet (FCoE) capabilities to a Cisco UCS B-Series blade server. -
Which of the following frame fields does Cisco FabricPath use to mitigate temporary Layer 2 loops?
- FTAG
- LID
- STP
- TTL
- IS-IS
Explanation:
Of the available choices, the Time to Live (TTL) field is the Cisco FabricPath frame field that FabricPath uses to mitigate temporary Open Systems Interconnection (OSI) networking model Layer 2 loops. The TTL field in a FabricPath frame operates similarly to the TTL field in Internet Protocol (IP) networking in that the field is decremented by a value of 1 each time it traverses a new hop. If the TTL expires, the frame is discarded.
Cisco FabricPath frames are classic Ethernet frames that are encapsulated with a 16-byte FabricPath header. This header contains a 48-bit outer destination address (ODA), which is a Media Access Control (MAC) address, and 48-bit outer source address (OSA). In addition, the field contains a 32-bit FabricPath tag. The classic Ethernet frame’s cyclic redundancy check (CRC) field is replaced by a new CRC field that is updated to reflect the additional header data in the frame. The TTL field is a 6-bit field that resides at the end of the FabricPath tag field.
Cisco FabricPath does not use an Intermediate System-to-Intermediate System (IS-IS) frame field to mitigate temporary Layer 2 loops. In addition, FabricPath does not use a Spanning Tree Protocol (STP) frame field. However, the IS-IS routing protocol is used as a Layer 3 replacement for traditional STP in a Cisco FabricPath topology. In traditional networking, STP is used to prevent Layer 2 switching loops in a topology that contains redundant links. The use of the IS-IS routing protocol ensures that Cisco FabricPath operates as a multipath environment for Layer 2 packets. In other words, IS-IS ensures that Cisco FabricPath is capable of Layer 2 multipath forwarding.
Cisco FabricPath does not use the forwarding tag (FTAG) frame field to mitigate temporary Layer 2 loops. Instead, the FTAG field is used to identify the unique FabricPath topology that unicast traffic is traversing. Each topology in FabricPath is assigned a unique tag. For multicast or broadcast traffic, the 10-bit FTAG field contains an ID for a forwarding tree that contains multiple destinations within the topology. The FTAG field is the second of three fields that reside in the FabricPath tag field. It is preceded by the 16-bit Ethertype field and succeeded by the TTL field.
Cisco FabricPath does not use the local ID (LID) frame field to mitigate temporary Layer 2 loops. Instead, the LID field stores a 16-bit value that identifies the edge port that a packet is either destined to or sent from. The LID field is the last field in the ODA and OSA fields of a Cisco FabricPath header. The edge port can be either a physical port or a logical port. In addition, the value in the LID field is locally significant to the switch that the frame is traversing. -
Which of the following of the main architectural component of Cisco ACI?
- the APIC
- a leaf switch
- a CE network
- a spine switch
Explanation:
The Cisco Application Policy Infrastructure Controller (APIC) is a means of managing the Cisco Application Centric Infrastructure (ACI); it is the main architectural component of Cisco ACI. A Cisco ACI architecture requires both the APIC and the spine switches and leaf switches of FabricPath to complete the architecture. The APIC communicates with the spine and leaf nodes and provides policy distribution as well as centralized management.
A leaf switch is not the main architectural component of Cisco ACI; a leaf switch is the Cisco FabricPath component that provides access layer connectivity. Cisco FabricPath is a means of constructing a scalable Open Systems Interconnection (OSI) networking model Layer 2 network from both Layer 2 and Layer 3 components. End hosts and classic Ethernet (CE) networks are typically directly connected to leaf switches by using edge ports.
A spine switch is not the main architectural component of Cisco ACI. Spine switches are the Cisco FabricPath component that form the backbone of the FabricPath’s switching fabric. Typically, leaf switches are connected to every spine switch along the backbone so that the spine switches provide connectivity between the leaf switches. Leaf switches connect to spine switches by using core ports.
A CE network, which is a traditional Ethernet network that uses Spanning Tree Protocol (STP) and transparent bridging, is not technically part of Cisco FabricPath. However, Cisco Nexus switches can connect to a CE network and Cisco FabricPath simultaneously. -
Which of the following statement best describes Cisco Fabric Service?
- There can be only two peers per domain.
- It synchronizes the state between two vPC peers.
- It monitors the status of vPC peers.
- It synchronizes the control plane and the data plane.
Explanation:
Cisco Fabric Services synchronizes the control plane and the data plane. Cisco Fabric Services is a messaging protocol that operates between virtual port channel (vPC) peers. Control plane and data plane information is synchronized over a vPC peer link.
There can be only two peers, or switches, per vPC domain. A vPC enables you to bundle ports from two peers, which form a domain, into a single Open Systems Interconnection (OSI) Layer 2 port channel. Similar to a normal port channel, a vPC bundles multiple switch ports into a single high-speed trunk port. A single vPC domain cannot contain ports from more than two switches. For ports on two switches to successfully form a vPC domain, all the following must be true:
– The vPC feature must be enabled on both switches.
– The vPC domain ID must be the same on both switches.
– The peer keepalive link must be configured and must be 10 gigabits per second (Gbps) or more.
– The vPC number must be the same on both switches.
A vPC peer link, not Cisco Fabric Services, synchronizes the state between two vPC peers. A vPC peer link is typically comprised of a port channel made up of two physical ports on each switch. This link synchronizes Media Access Control (MAC) address tables between switches and serves as a transport for data plane traffic. Bridge protocol data unit (BPDU) and Link Aggregation Control Protocol (LACP) packets are also forwarded to the second peer over this link, which causes the vPC peers to appear to be a single control plane.
A vPC peer keepalive link, not Cisco Fabric Services, monitors the status of vPC peers. The peer keepalive link operates at Layer 3 of the OSI networking model; it is used to ensure that vPC switches are capable of determining whether a vPC domain peer has failed. Peer keepalive links can be configured to operate in any virtual routing and forwarding (VRF) instance, including the management VRF. Each vPC peer keepalive link is configured with the remote peer’s IP address as its destination IP address and the local peer’s IP address as its source address. Peer keepalive links must be trunk links.