350-601 : Implementing and Operating Cisco Data Center Core Technologies (DCCOR) : Part 07
-
Which of the following statements about vPC technology limitations is not true?
- Each VDC is a separate switch.
- There is only one vPC domain ID per switch.
- There are only two vPC domain IDs per switch.
- vPC peer links are always 10 Gbps.
- vPC forms a Layer 3 port channel.
Explanation:
A virtual port channel (vPC) forms an Open System Interconnection (OSI) networking model Layer 2 port channel, not a Layer 3 port channel. The vPC feature is not capable of supporting Layer 3 port channels. Therefore, any routing that is configured from the vPC peers to other parts of the network should be performed on separate Layer 3 ports.
Each virtual device context (VDC) is a separate switch in a vPC domain. A VDC logically virtualizes a switch. A VDC is a single virtual instance of physical switch hardware. A vPC logically combines ports from multiple switches into a single port-channel bundle. Conventional port channels, which are typically used to create high-bandwidth trunk links between two switches, require that all members of the bundle exist on the same switch. vPCs enable virtual domains that are comprised of multiple physical switches to connect as a single entity to a fabric extender, server, or other device.
A vPC domain is comprised of two switches per domain. In addition, a vPC domain cannot be comprised of more than two switches. Each switch in the vPC domain must be configured with the same vPC domain ID. To enable vPC configuration on a Cisco Nexus 7000 Series switch, you should issue the feature vpc command on both switches. To assign the vPC domain ID, you should issue the vpc domain domain-id command, where domain-id is an integer in the range from 1 through 1000, in global configuration mode. For example, issuing the vpc domain 101 command on a Cisco Nexus 7000 Series switch configures the switch with a vPC domain ID of 101.
Only one vPC domain can be configured per switch. If you were to issue more than one vpc domain domain-id command on a Cisco Nexus 7000 Series switch, the vPC domain ID of the switch would become whatever value was issued last. After you issue the vpc domain domain-id command, the switch is placed into vPC domain configuration mode. In vPC domain configuration mode, you should configure a peer keepalive link.
Peer keepalive links monitor the remote device to ensure that it is operational. You can configure a peer keepalive link in any virtual routing and forwarding (VRF) instance on the switch. Each switch must use its own Internet Protocol (IP) address as the peer keepalive link source IP address and the remote switch’s IP address as the peer keepalive link destination IP address. The following commands configure a peer keepalive link between SwitchA and SwitchB in vPC domain 101:SwitchA(config)#vpc domain 101 SwitchA(config-vpc-domain)#peer-keepalive destination 192.168.1.2 source 192.168.1.1 vrf default SwitchB(config)#vpc domain 101 SwitchB(config-vpc-domain)#peer-keepalive destination 192.168.1.1 source 192.168.1.2 vrf default
A vPC peer link should always be a 10-gigabit-per-second (Gbps) Ethernet port, not 1 Gbps. Peer links are configured as a port channel between the two members of the vPC domain. You should configure vPC peer links after you have successfully configured a peer keepalive link. Cisco recommends connecting two 10-Gbps Ethernet ports from two different input/output (I/O) modules. To configure a peer link, you should issue the vpc peer-link command in interface configuration mode. For example, the following commands configure a peer link on port-channel 1
SwitchA(config)#interface port-channel 1 SwitchA(config-if)#switchport mode trunk SwitchA(config-if)#vpc peer-link SwitchB(config)#interface port-channel 1 SwitchB(config-if)#switchport mode trunk SwitchB(config-if)#vpc peer-link
It is important to issue the correct channel-group commands on a port channel’s member ports prior to configuring the port channel. For example, if you are creating Port-channel 1 by using the Ethernet 2/1 and Ethernet 2/2 interfaces, you could issue the following commands on each switch to correctly configure those interfaces as members of the port channel:
SwitchA(config)#interface range ethernet 2/1-2 Switch(config-if-range)#switchport SwitchA(config-if-range)#channel-group 1 mode active SwitchB(config)#interface range ethernet 2/1-2 SwitchB(config-if-range)#switchport SwitchB(config-if-range)#channel-group 1 mode active
-
Which of the following best describes the control plane of a Nexus switch?
- It is where SNMP operates.
- It is where routing calculations are made.
- It is also known as the forwarding plane.
- It is where traffic forwarding occurs.
Explanation:
Of the available choices, the control plane of a Nexus switch is best described as where routing calculations are made. A Nexus switch consists of three operational planes: the control plane, the management plane, and the data plane, which is also known as the forwarding plane. Routing protocols such as Enhanced Interior Gateway Routing Protocol (EIGRP), Open Shortest Path First (OSPF), and Border Gateway Protocol (BGP) all operate in the control plane of a Nexus switch. The control plane is responsible for gathering and calculating the information required to make the decisions that the data plane needs for forwarding. Routing protocols operate in the control plane because they enable the collection and transfer of routing information between neighbors. This information is used to construct routing tables that the data plane can then use for forwarding.
The data plane, not the control plane, is where traffic forwarding occurs. Cut-through switching allows a switch to begin forwarding a frame before the frame has been received in its entirety. Store-and-forward switching receives an entire frame and stores it in memory before forwarding the frame to its destination.
The management plane, not the control plane, is where Simple Network Management Protocol (SNMP) operates. The management plane is responsible for monitoring and configuration of the control plane. Therefore, network administrators typically interact directly with protocols running in the management plane. -
Which of the following protocols are used to bring up an ACI fabric in a cascading manner? (Choose two.)
- LLDP
- CDP
- STP
- DHCP
- ARP
Explanation:
Link-Layer Discovery Protocol (LLDP) and Dynamic Host Configuration Protocol (DHCP) are protocols that are used to bring up a Cisco Application Centric Infrastructure (ACI) fabric in a cascading manner. LLDP is a standard protocol that detects neighboring devices of any type. An ACI fabric uses LLDP along with DHCP to discover switch nodes and to assign Internet Protocol (IP) addresses to virtual extensible local area network (VXLAN) tunnel endpoints (VTEPs). LLDP is also used by Cisco Application Policy Infrastructure Controllers (APICs) to detect virtual switches, although it is also possible to use Cisco Discovery Protocol (CDP) for that purpose.
Each APIC server in the ACI communicates with ACI nodes and other APIC servers during the APIC cluster discovery process by using private IP addresses. Private IP addresses are not routable over the Internet. When an ACI fabric is booted, an internal private IP addressing scheme is used to enable the APIC to communicate with other nodes and controllers.
The ACI fabric does not use CDP, Address Resolution Protocol (ARP), or Spanning Tree Protocol (STP) to bring up a Cisco API fabric in a cascading manner. If configured, CDP can be used instead of LLDP to detect virtual switches. ARP is a protocol that is, used to map Media Access Control (MAC) addresses to IP addresses on a LAN. STP is a protocol that is used in switched networks to prevent switching loops. -
Which of the following is also known as a context within an ACI tenant?
- an EPG
- a bridge domain
- a VRF instance
- an application profile
Explanation:
Of the available choices, a virtual routing and forwarding (VRF) instance is also known as a context within a Cisco Application Centric Infrastructure (ACI) tenant. VRF instances are also sometimes known as private networks. A VRF instance is an Open Systems Interconnection (OSI) networking model Layer 3 forwarding domain within a given ACI tenant. Multiple bridge domains can be connected to a given VRF instance within a tenant.
A bridge domain typically defines a Layer 2 address space and flood domain within a Cisco ACI fabric. An ACI bridge domain is similar to a traditional networking virtual local area network (VLAN) in that it is a Layer 2 broadcast domain. Bridge domains define the Media Access Control (MAC) address space. Typically, a bridge domain is associated with a single subnet, although multiple subnets can be associated within a given bridge domain. Bridge domains are typically connected to VRF instances within a given ACI tenant.
An application profile is used to configure policies and relationships between endpoint groups (EPGs). Typically, an application profile is a container for one or more logically related EPGs. For example, EPGs that provide similar services or functions might be associated with the same application profile.
An EPG is a logical ACI construct that contains multiple related endpoints. Endpoints are physical or virtual devices that are connected to a network. For example, a web server is an endpoint. EPGs contain endpoints that have similar policy requirements, although not necessarily similar functions. EPGs enable group management of the policies for the endpoints they contain. -
Which of the following logically virtualizes an OSI networking model Layer 3 address domain?
- a VRF instance
- vPC
- a VIC
- a VDC
Explanation:
A virtual routing and forwarding (VRF) instance logically virtualizes an Open Systems Interconnection (OSI) networking model Layer 3 address domain. VRFs enable a router to maintain multiple, simultaneous routing tables. Therefore, VRFs can be configured on a single router to serve multiple Layer 3 domains instead of implementing multiple hardware routers.
A virtual device context (VDC) does not logically virtualize an OSI networking model Layer 3 address domain. A VDC logically virtualizes a Cisco Nexus 7000 Series switch. A VDC is a single virtual instance of physical switch hardware. By default, the control plane of the Cisco Nexus 7000 Series switch is configured to run a single VDC. It is possible to configure multiple VDCs on the same hardware. A single VDC can contain multiple virtual local area networks (VLANs) and VRF instances.
A virtual port channel (vPC) does not logically virtualize an OSI networking model Layer 3 address domain. A vPC enables ports from multiple switches to be combined into a single port channel bundle. Conventional port channels, which are typically used to create high-bandwidth trunk links between two switches, require that all members of the bundle exist on the same switch. vPCs enable virtual domains that are comprised of multiple physical switches to connect as a single entity to a fabric extender, server, or other device.
A virtual interface card (VIC) does not logically virtualize an OSI networking model Layer 3 address domain. A VIC is a Cisco device that can be used to create multiple logical network interface cards (NICs) and host bus adapters (HBAs). VICs such as the Cisco M81KR send Fibre Channel over Ethernet (FCoE) traffic and normal Ethernet traffic over the same physical medium. -
You connect Port 13 of a Cisco UCS Fabric Interconnect to a SAN. All the Fabric Interconnect ports are unified ports.
Which of the following options should you select for Port 13 in Cisco UCS Manager?
- Configure as Appliance Port
- Configure as Server Port
- Configure as FCoE Storage Port
- Configure as Uplink Port
- Configure as FCoE Uplink Port
Explanation:
You should select the Cisco Unified Computing System (UCS) Manager Configure as FCoE Uplink Port option for Port 13 on the Cisco UCS Fabric Interconnect in this scenario because Port 13 is connected to a storage area network (SAN). Cisco UCS Fabric Interconnects enable management of two different types of network fabrics in a single UCS domain, such as a Fibre Channel (FC) SAN and an Ethernet local area network (LAN).
Unified ports in a UCS Fabric Interconnect can operate in one of two primary modes: FC or Ethernet. Each mode can be assigned a different port role, such as server port, uplink port, or appliance port for Ethernet. The FC port mode supports two roles: FC over Ethernet (FCoE) uplink port and FCoE storage port. Uplink ports are used to connect the Fabric Interconnect to the next layer of the network, such as to a SAN by using the FCoE uplink port role or to a LAN by using the uplink port role.
You should not choose the Configure as Uplink Port option in this scenario. The Configure as Uplink Port option would configure Port 13 in the uplink role in Ethernet mode. This port role is used for connecting a UCS Fabric Interconnect to an Ethernet LAN.
You should not choose the Configure as Server Port option in this scenario. The Configure as Server Port option is used to connect the Fabric Interconnect to network adapters on server hosts.
You should not choose the Configure as FCoE Storage Port option in this scenario. The Configure as FCoE Storage Port option is used to connect the Fabric Interconnect to a Direct-Attached Storage (DAS) device.
You should not choose the Configure as Appliance Port option in this scenario. The Configure as Appliance Port option is used to connect the Fabric Interconnect to a storage appliance. -
Which of the following Cisco FabricPath features improves on data center scalability?
- use of iSCSI instead of FCoE
- deployment of consistent policies
- elimination of reliance on STP
- convergence of network and storage
Explanation:
Of the available choices, the elimination of reliance on Spanning Tree Protocol (STP) to ensure a loop-free switching environment is a Cisco FabricPath feature that improves data center scalability and growth. Cisco Unified Fabric uses virtual Port Channel (vPC) in place of technologies such as EtherChannel, which was developed to enable redundant high-speed connectivity between switches in an STP topology. However, STP is still present to ensure that switching loops can be mitigated if they occur. Cisco FabricPath, on the other hand, is a Cisco Unified Fabric technology that completely replaces STP with the Intermediate System-to-Intermediate System (IS-IS) routing protocol. The combination of IS-IS with the Open Systems Interconnection (OSI) networking model Layer 2 fabric’s simplicity and fabric extenders enhances the scalability of Cisco Unified Fabric beyond the practical limits of a normal Layer 2 topology.
The deployment of consistent network policies is a Cisco Unified Fabric feature that improves on data center security, not a Cisco FabricPath feature that improves on data center scalability. Cisco Unified Fabric allows the use of templates and a common switch operating system (OS) to ensure the deployment of network policies consistently across the fabric and its virtualized environments. The use of templates reduces the likelihood of human error when deploying network policies. In addition, Cisco Unified Fabric contains virtualization-aware security products.
The use of Internet Small Computer Systems Interface (iSCSI) instead of Fibre Channel over Ethernet (FCoE) in a Cisco Unified Fabric enables the encapsulation of Fibre Channel (FC) in Transmission Control Protocol/Internet Protocol (TCP/IP) packets; it is not a Cisco FabricPath feature that improves on data center scalability. The use of iSCSI in a Cisco Unified Fabric can be considered an alternative to the use of FCoE in a fabric that does not have strict storage connectivity requirements. Unlike iSCSI, FCoE encapsulates FC in Ethernet frames.
Convergence of network and storage is a Cisco Unified Fabric feature that simplifies operation and reduces management endpoints, not a Cisco FabricPath feature that improves on data center scalability. A typical Cisco Unified Fabric architecture is used to merge storage area network (SAN) features with a local area network (LAN). The resulting converged network and storage is delivered over an Ethernet fabric. -
Which of the following port types allows only FabricPath VLAN traffic?
- a trunk port
- a core port
- an access port
- an edge port
Explanation:
Of the available choices, only a Cisco FabricPath core port allows only FabricPath virtual local area network (VLAN) traffic. Cisco FabricPath uses Open Systems Interconnection (OSI) networking model Layer 3 routing combined with Layer 2 switching to construct a unified and scalable Layer 2 fabric. Although Cisco FabricPath defines two types of ports, only core ports are considered to be part of the FabricPath network. Core ports forward Ethernet frames encapsulated within a FabricPath header. In addition, core ports are always trunk ports that include an Institute of Electrical and Electronics Engineers (IEEE) 802.1Q VLAN tag. Only FabricPath VLANs are allowed on core ports.
Classic Ethernet VLAN traffic is allowed on an edge port. An edge port is a Cisco FabricPath component port that does not operate as part of the FabricPath network. Instead, edge ports send only normal Ethernet frames as part of a classic Layer 2 switched network. An edge port can be configured as either an access port or an IEEE 802.1Q trunk port.
Although all core ports are trunk ports, not all trunk ports are core ports. Therefore, a trunk port could carry either FabricPath VLAN traffic or classic Ethernet VLAN traffic depending on the circumstances and configuration. Trunk ports enable switches to transmit and receive data on multiple VLANs over the same link.
An access port carries either FabricPath VLAN traffic or classic Ethernet VLAN traffic, depending on the circumstances and configuration. An access port is a switch port that typically connects to an end device, such as a server or workstation. Access ports transmit and receive data on a single VLAN. Core ports cannot be access ports. -
Examine the Cisco UCS Director Workflow Designer workflow in the following exhibit:
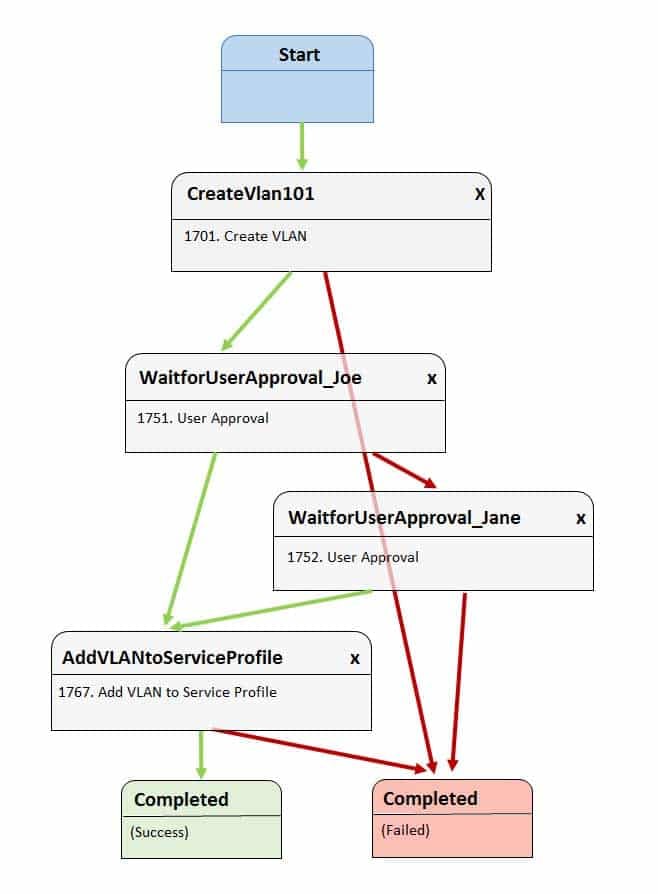
350-601 Part 07 Q09 013 Jane initiates the workflow, but Joe rejects it.
Which of the following best describes what will most likely occur next?- VLAN 101 will be sent back to Joe for approval if Jane approves.
- VLAN 101 will not be added to the service profile, and the workflow will succeed.
- VLAN 101 will not be added to the service profile, and the workflow will fail.
- VLAN 101 will be added to the service profile if Jane approves.
Explanation:
Most likely, virtual local area network (VLAN) 101 will be added to the service profile if Jane approves. The Cisco Unified Computing System (UCS) Director Workflow Designer workflow in this scenario creates VLAN 101 after it starts. Before the next task is executed, the workflow requires the approval of a user named Joe. In this scenario, Joe has rejected the approval step. If Joe’s approval is not obtained, then the workflow prompts Jane for approval to continue. If Jane rejects the approval step, the workflow ends in failure. If Jane approves, VLAN 101 will be assigned to the service profile.
Cisco UCS Director Workflow Designer is a graphical user interface (GUI) that enables users to create automated workflows in a drag-and-drop fashion. Each task in a workflow is equipped with an On Success button and an On Failure button. Each button provides a drop-down list of other tasks in the workflow. In this way, the user can select which tasks are executed next if a task succeeds and which tasks are executed next if a task fails. Green arrows in Workflow Designer represent the On Success path. Red arrows represent the On Failure path.
VLAN 101 will not be sent back to Joe for approval if Jane approves. In this scenario, the WaitforUserApproval_Jane task’s On Success button is connected to the AddVLANtoServiceProfile task. Therefore, Jane can approve adding VLAN 101 to the service profile even if Joe does not.
There is nothing in this scenario that would lead to workflow failure or workflow success based on Joe’s rejection of the task, because Jane has an opportunity to approve the addition of the VLAN to the Service Profile if Joe rejects it. However, if Joe were to approve the addition of VLAN 101 to the service profile, the task would be attempted and potentially completed without Jane’s approval or rejection because the WaitforUserApproval_Joe task’s On Success button is tied directly to the AddVLANtoServiceProfile task. -
Which of the following statements about Layer 3 virtualization on a Cisco Nexus 7000 Series switch is not true?
- Each Layer 3 interface can be configured in only one VRF.
- a VRF represents a Layer 2 addressing domain.
- Each VDC can be configured with multiple VRFs.
- Each VRF can belong to only one VDC.
Explanation:
A virtual routing and forwarding (VRF) instance represents an Open Systems Interconnection (OST) networking model Layer 3 addressing domain, not a Layer 2 addressing domain. VRFs are used to logically separate OSI networking model Layer 3 networks. The address space, routing process, and forwarding table that are used within a VRF are local to that VRF.
There are two VRF instances configured on a Nexus 7000 Series switch by default: the management VRF and the default VRF. The management VRF is used only for management, includes only the mgmt 0 interface, and uses only static routing. The default VRF, on the other hand, includes all Layer 3 interfaces until you assign those interfaces to another VRF.
Each Layer 3 interface on a Cisco Nexus 7000 Series switch can be configured in only one VRF. In other words, a Layer 3 interface that has been assigned to a given VRF cannot be simultaneously assigned to another VRF.
Each VRF on a Cisco Nexus 7000 Series switch can belong to only one virtual device context (VDC). However, each VDC can be configured with multiple VRFs. A VDC is a virtual switch. Therefore, a VDC is a logical representation of a physical device on which VRFs can be configured. -
Which of the following FIP components operates on the native VLAN?
- FLOGI
- FIP VLAN discovery
- FIP FCF Discovery
- FDISC
Explanation:
Of the available choices, only FCoE Initialization Protocol (FIP) virtual local area network (VLAN) Discovery operates on the native VLAN. FIP VLAN Discovery is one of two discovery protocols used by FIP during the Fibre Channel over Ethernet (FCoE) initialization process. FIP itself is a control protocol that is used to create and maintain links between FCoE device pairs, such as FCoE nodes (ENodes) and Fibre Channel Forwarders (FCFs). ENodes are FCoE entities that are similar to host bus adapters (HBAs) in native Fibre Channel (FC) networks. FCFs, on the other hand, are FCoE entities that are similar to FC switches in native FC networks.
FIP VLAN Discovery is typically the first discovery process to occur during FCoE initialization. This process discovers the VLAN that should be used to send all other FIP traffic during the initialization. This same VLAN is also used by FCoE encapsulation. The FIP VLAN Discovery protocol is the only FIP protocol that runs on the native VLAN.
FCF Discovery finds forwarders that can accept logins. FIP FCF Discovery is typically the second discovery process to occur during FCoE initialization. This process enables ENodes to discover FCFs that allow logins. FCFs that allow logins send periodic FCF Discovery advertisements on each FCoE VLAN.
Fabric Login (FLOGI) and Fabric Discovery (FDISC) messages comprise the final protocol in the FCoE FIP initialization process. These messages are used to activate Open Systems Interconnection (OSI) network model Layer 2, or the Data link layer, of the fabric. It is at this point in the initialization process that an FC ID is assigned to the N port, which is the port that connects the node to the switch. -
You manage the Cisco FabricPath network in the following exhibit:

350-601 Part 07 Q12 014 A host that is directly connected to L2 sends a unicast packet to an unknown host elsewhere in the Cisco FabricPath network.
Which of the following will L2 do first?- perform a lookup for the destination host in its MAC address table
- update the classic Ethernet MAC table with the sending host’s source MAC address
- encapsulate the packet into the FabricPath header
- receive an unknown unicast packet from the sending host
Explanation:
L2 will first receive an unknown unicast packet from the sending host if that host sends a unicast packet to an unknown host elsewhere in the Cisco FabricPath network. In this scenario, L2 is a leaf switch to which the sending host is directly connected. However, the sending host does not have information about how to send a unicast packet to the destination host. Therefore, the sending host sends an unknown unicast packet to the directly connected leaf switch. When L2 receives the unknown unicast, packet, the following occurs:
– L2 updates the classic Ethernet Media Access Control (MAC) table with the sending host’s source MAC address.
– L2 performs a lookup for the destination MAC address of the destination host.
– L2 encapsulates the classic Ethernet frame in a FabricPath header and floods it to the multidestination forwarding tree with L2’s switch ID as the outer source address (OSA).
Because of the spine-and-leaf configuration of the topology, L2 floods the packet to its directly connected spine switches, S1 and S2, which then flood the packet to the other leaf switches. Each leaf switch then performs a MAC address lookup. The switch that has the destination host in its MAC address table adds the sending host to its own MAC address table. At this point, the packet is sent to the destination host.
By contrast, when L2 receives a known unicast packet, which is a unicast packet with a destination address that the switch knows how to reach, that is intended for a host on a different switch the following occurs:
– L2 performs a MAC address lookup and locates the destination switch.
– L2 looks up the switch ID of the destination switch and chooses a FabricPath core port on which to send the packet.
– L2 encapsulates the packet in a FabricPath header, including its own switch ID in the OSA field and the destination switch’s ID in the outer destination address (ODA) field.
– L2 sends the packet.
If L2 receives a unicast packet that is destined for a host that is also directly connected to L2, the switch will locally deliver the packet and will not send or flood it to spine switches. -
Which of the following are benefits of server virtualization? (Choose four.)
- reduces maintenance downtime
- reduces facility expenses
- can aid configuration standardization
- reduces network bandwidth hot spots
- can grow and shrink based on resource need
Explanation:
Server virtualization can reduce maintenance downtime. Server virtualization is the process of using a virtual machine (VM) hypervisor to create and maintain multiple server VMs on a single hardware server. Because server VMs can be migrated from one hypervisor to another without powering down the VM, maintenance on a hypervisor’s host need not hinder virtualized server availability.
Server virtualization can grow and shrink based on resource need. This feature is known as elasticity and is commonly used by cloud-based virtual servers. A virtual server that requires more hardware resources can grow to consume those resources and shrink when those resources are no longer required.
Server virtualization can reduce facility expenses. When servers are virtualized, it is not necessary to purchase new hardware for each new server that is deployed at the facility. Instead, new servers can be quickly instantiated on existing hardware, thereby eliminating the cost of purchasing additional hardware.
Server virtualization can aid configuration standardization. Because VMs can be cloned, administrators can create what is known as a golden image, which is a single VM that is equipped with a standardized, secure configuration. This golden image can then be cloned to create new VMs that are already equipped with that standard, secure configuration. Deploying and instantiating VMs that are already configured with a standard, secure configuration reduces administrative overhead and prevents accidental deployment of an insecure configuration.Server virtualization causes, not reduces, network bandwidth hot spots. Therefore, reducing network bandwidth hot spots is not a benefit of server virtualization. Because all the VMs are using the same physical network connection, it is possible that required network bandwidth could surpass network capacity. It is therefore important that VM administrators understand the network demands of each VM installed on a given physical server and migrate or deploy new VMs on new hardware as necessary.
-
You are installing a Cisco Nexus 1000v VSM in VMware vSphere by using the recommended OVA file method of installation.
Which of the following steps are performed automatically? (Choose four.)- install VSM plug-in
- create the VSM
- add hosts
- configure VSM networking
- configure SVS connection
- perform initial VSM setup
Explanation:
The creation of the virtual supervisor module (VSM), the configuration of VSM networking, the initial VSM setup, and the installation of the VSM plug-in are performed automatically when you install a Cisco Nexus 1000v VSM in VMware vSphere by using the open virtualization appliance (OVA) file method of installation. You are required to manually configure the server virtualization switch (SVS) connection and add hosts. The OVA file method of installation is the Cisco-preferred method of installing a Nexus 1000v VSM on VMware vSphere.
There are three methods of installing the Nexus 1000v VSM:
– By using an International Standards Organization (ISO) image
– By using an open virtualization format (OVF) folder and installation wizard
– By using an OVA file and installation wizard
No matter which installation method is chosen, the VSM installation process consists of the following six steps:
– Creation of the VSM virtual machine (VM) in Cisco vCenter
– Configuration of VSM networking
– Initial VSM setup in the VSM console
– Installation of the VSM plug-in in vCenter
– Configuration of the SVS connection in the VSM console
– Addition of hosts to the virtual distributed switch in vCenter
The steps in this process that you are required to perform manually depend on the method of installation you choose.
The OVF folder method of installing the Nexus 1000v VSM is similar to the OVA file method. However, the OVF folder method performs only the first two steps of the installation process. This means that you are required to manually configure the final four steps. The primary difference between an OVA file and an OVF folder is that the OVA file is a single compressed archive.
The ISO image method of installing the Nexus 1000v VSM requires that you manually perform each of the six steps in the installation process. An ISO image file contains a virtual filesystem that can be mounted by an operating system (OS) similar to an optical disc or a Universal Serial Bus (USB) flash drive. -
Which of the following Cisco VIC adapter communication methods is most likely to rely on the VMware ESXi hypervisor to switch traffic?
- software and Nexus 1000V
- pass-through switching
- bare-metal OS driver
- store-and-forward switching
Explanation:
Of the available choices, the Cisco virtual interface card (VIC) adapter method that is most likely to rely on the VMware ESXi hypervisor to switch traffic is software and a Cisco Nexus 1000v virtual switch. Cisco VICs integrate with virtualized environments to enable the creation of virtual network interface cards (vNICs) in virtual machines (VMs). When using software and a Cisco Nexus 1000v virtual switch to switch traffic, switching is controlled by the hypervisor. Cisco describes the software-based method of handling traffic by using a Cisco Nexus 1000v virtual switch as Virtual Network Link (VN-Link).
Pass-through switching, which Cisco describes as hardware-based VN-Link, does not rely on the VMware ESXi hypervisor to switch traffic. Pass-through switching is a faster and more efficient means for Cisco VIC adapters to handle traffic between VMs.
Pass-through switching uses application-specific integrated circuit (ASIC) hardware switching, which reduces overhead because the switching occurs in the fabric instead of relying on software. Pass-through switching also enables administrators to apply network policies between VMs in a fashion similar to how traffic policies are applied between traditional physical network devices.
A bare-metal operating system (0S) driver method of communication is not likely to rely on the VMware ESXi hypervisor to switch traffic. Cisco VIC adapters forward traffic similar to other Cisco Unified Computing System (UCS) adapters when installed in a server that is configured with a single bare-metal OS without virtualization. It is therefore possible to use a Cisco VIC adapter with OS drivers to create static vNICs on a server in a nonvirtualized environment.
Store-and-forward switching is not a method of communication that is used by Cisco VIC adapters. However, switches can be configured to use store-and-forward switching. A switch that uses store-and-forward switching receives the entire frame before
forwarding the frame. By receiving the entire frame, the switch can verify that no cyclic redundancy check (CRC) errors are present in the frame; this helps prevent the forwarding of frames with errors. Cisco VIC adapters are hardware interface components that support virtualized network environments. -
Which of the following are not capable of operating as a standalone physical switch? (Choose two.)
- Nexus 5000 Series
- Nexus 2000 Series
- Nexus 7000 Series
- Nexus 9000 Series
- Nexus 1000v Series
Explanation:
Of the available choices, neither the Cisco Nexus 1000v Series nor the Cisco Nexus 2000 Series are capable of operating as a standalone physical switch. The Cisco Nexus 1000v is a virtual switch that is capable of connecting to upstream physical switches in order to provide connectivity for a virtual machine (VM) network environment. Although the Cisco Nexus 1000v operates similar to a standard switch, it exists only as software in a virtual environment and is therefore not a physical switch.
The Cisco Nexus 2000 Series of switches are fabric extenders (FEXs) and cannot operate as standalone switches. FEX technologies depend on parent switches, such as a Cisco Nexus 5500 Series switch or a Cisco Nexus 7000 Series switch, to provide forwarding tables and control plane functionality. FEX technologies are intended to extend the network to edge devices. Typically, FEX devices in the Cisco Nexus 2000 Series are managed by first connecting to the parent device using either Telnet or Secure
Shell (SSH) and then configuring the FEX.
Cisco Nexus 5000 Series switches operate as standalone physical switches. Cisco Nexus 5000 Series switches are data center access layer switches that can support 10-gigabit-per-second (Gbps) or 40-Gbps Ethernet, depending on the model. Native Fibre Channel (FC) and FC over Ethernet (FCoE) are also supported by Cisco Nexus 5000 Series switches.
Cisco Nexus 7000 Series switches operate as standalone physical switches. Cisco Nexus 7000 Series switches are typically used as an end-to-end data center solution, which means that the series is capable of supporting all three layers of the data center architecture: core layer, aggregation layer, and access layer. In addition, the Cisco Nexus 7000 Series supports virtual device contexts (VDCs). The Cisco Nexus 7000 Series can support up to 100-Gbps Ethernet.
Cisco Nexus 9000 Series switches operate as standalone physical switches. Cisco Nexus 9000 Series switches can operate either as traditional NX-OS switches or in an Application Centric Infrastructure (ACI) mode. Unlike Cisco Nexus 7000 Series, Cisco Nexus 9000 Series switches do not support VDCs or storage protocols. -
You connect a FEX to a Cisco Nexus switch. After configuration is complete, you issue the show fex 100 command on the switch and receive the following partial output:
Switch#show fex 100 <output omitted> pinning-mode: static Max-links: 1 Fabric port for control traffic: Eth2/1 Fabric interface state: Eth2/1 - Interface Up. State: Active Eth2/2 - Interface Up. State: Active
Which of the following is most likely true?
- Which of the following is most likely true?
- The switch is connected to the FEX by using port channel, but the configuration is not complete.
- The fex associate 100 command has been issued on the Po100 interface.
- The switch is connected to the FEX by using static pinning.
Explanation:
Of the available choices, it is most likely that the switch is connected to the Cisco fabric extender (FEX) by using static pinning. There are two methods for connecting a FEX to a Cisco Nexus switch: static pinning and port channel. The static pinning method connects a switch to a FEX by using individual links between the two devices. Host interfaces are then distributed among the available fabric ports in an equal fashion. However, if a fabric port goes down, all the FEX interfaces associated with that fabric port are down.
In this scenario, two individual switch ports, Ethernet 2/1 and Ethernet 2/2, are displayed in the up and active states in the output of the show fex 100 command. However, only one of those ports can be the fabric port because the pinning max-links command is configured to its default value of 1. In order to support more than one fabric port, you should issue the pinning max-links maximum-links command, where maximum-links is equal to the number of connected switch ports that should be used as fabric ports.
It is not likely that the switch is connected to the Cisco FEX by using a port channel. A port channel configuration bypasses the static pinning issue of a single interface taking down all the ports on a FEX because a port channel is a logical interface that is comprised of a number of physical ports. When a FEX is associated with a port channel instead of static pinning, a failed interface means that the other interfaces in the port channel take over for the port that is down.
It is not likely that the fex associate 100 command has been issued on the Po100 interface in this scenario. In addition, it is not likely that the port-channel configuration has not been completed, because there is no evidence of the configuration of a P0100 interface in the output. To associate a port channel with a FEX, you should first create the port channel, configure the port channel to support a FEX, and then associate the port channel with a specific FEX. For example, the following commands configure Po100 on a Cisco Nexus switch to support a FEX and associate with FEX 100:
interface port-channel 100
switchport mode fex-fabric
fex associate 100
The switchport mode fex-fabric command and the fex associate 100 command should also be issued on each physical port that is a member of Po100’s channel group 100. -
Which of the following are most likely to operate in the management plane of a Nexus switch?
- store-and-forward switching
- cut-through switching
- EIGRP
- SNMP
- OSPF
- BGP
Explanation:
Of the available choices, Simple Network Management Protocol (SNMP) is an Internet Protocol (IP) network management protocol that is most likely to operate in the management plane of a Nexus switch. A Nexus switch consists of three operational planes: the data plane, which is also known as the forwarding plane, the control plane, and the management plane. The management plane is responsible for monitoring and configuration of the control plane. Therefore, network administrators typically interact directly with protocols running in the management plane.
Cut-through switching and store-and-forward switching are most likely to operate in the data plane of a Nexus switch. Of the three, the data plane is where traffic forwarding occurs. Cut-through switching allows a switch to begin forwarding a frame before the frame has been received in its entirety. Store-and-forward switching receives an entire frame and stores it in memory before forwarding the frame to its destination.
Enhanced Interior Gateway Routing Protocol (EIGRP), Open Shortest Path First (OSPF), and Border Gateway Protocol (BGP) all operate in the control plane of a Nexus switch. The control plane is responsible for gathering and calculating the information required to make the decisions that the data plane needs for forwarding. Routing protocols operate in the control plane because they enable the collection and transfer of routing information between neighbors. This information is used to construct routing tables that the data plane can then use for forwarding. -
You issue the following command on a Cisco Nexus 7000 switch:
vrf context management
Which of the following is most likely to occur?
- The switch will be placed into VRF configuration mode for an existing VRF instance.
- The switch will return an error because the management VRF already exists.
- A new VDC named management will be created.
- A new VRF instance named management will be created.
Explanation:
Most likely, the switch will be placed into virtual routing and forwarding (VRF) configuration mode for the existing management VRF. There are two VRF instances configured on a Nexus 7000 by default: the management VRF and the default VRF. The management VRF is used only for management, includes only the mgmt 0 interface, and uses only static routing.
The vrf context name command can be used to create a new VRF or to enter VRF configuration mode for an existing VRF. Because the Nexus 7000 is already configured with a management VRF, issuing the command in this scenario places the device into VRF configuration mode for that VRF. Similarly, issuing the vrf context default command would place the switch into VRF configuration mode for the existing default VRF.
VRFs are used to logically separate Open Systems Interconnection (OSI) networking model Layer 3 networks. Therefore, it is possible to have overlapping Internet Protocol version 4 (IPv4) or Internet Protocol version 6 (IPv6) addresses in environments that contain multiple tenants. However, an interface that has been assigned to a given VRF cannot be simultaneously assigned to another VRF. The address space, routing process, and forwarding table that are used within a VRF are local to that VRF.
The default VRF, on the other hand, includes all Layer 3 interfaces until you assign those interfaces to another VRF. Similarly, the default VRF runs any routing protocols that are configured unless those routing protocols are assigned to another VRF. All show and exec commands that are issued in the default VRF apply to the default routing context. Unless an administrator configures other VRFs on a Nexus 7000, any forwarding configurations that are made by the administrator will operate in the default VRF. -
You want to perform maintenance on an ESXi server and need to migrate its VMware VMs to another ESXi server. However, you do not need to migrate the VM datastore. You do not want to power off the VMs during the migration process.
Which of the following solutions should you choose?
- vSphere vMotion
- copying or cloning
- cold migration
- Storage vMotion
Explanation:
Of the available choices, you should choose VMware vMotion if you want to migrate a VMware virtual machine (VM) from one VMware ESXi server to another ESXi server without powering off the VM. In this scenario, you do not want to migrate the VMware datastore. VMware’s vSphere vMotion does not migrate datastores.
VMware’s ESXi server is a bare-metal server virtualization technology, which means that ESXi is installed directly on the hardware it is virtualizing instead of running on top of another operating system (OS). This layer of hardware abstraction enables tools like vMotion to migrate ESXi VMs from one host to another without powering off the VM, enabling the VM’s users to continue working without interruption.
You do not need to choose Storage vMotion to perform the migration in this scenario, because Storage vMotion allows migration of both the VM and its datastore. The datastore is the repository of VM-related files, such as logs and virtual disks. When migrating a VM by using Storage vMotion, both the virtualized environment and the datastore can be moved to a new host without powering down or suspending the VM.
You should not choose cold migration, copying, or cloning in this scenario. Cold migration is the process of powering down a VM and moving the VM or the VM and its datastore to a new location. While a cold migration is in progress, no users can perform tasks inside the VM. Both copying and cloning create new instances of a given VM. Therefore, neither action is a form of migrating a VM to another host. Typically, a VM must be powered off or suspended in order to successfully copy or clone it