DP-300 : Administering Relational Databases on Microsoft Azure : Part 09
-
HOTSPOT
You have an Azure SQL Database managed instance named sqldbmi1 that contains a database name Sales.
You need to initiate a backup of Sales.
How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
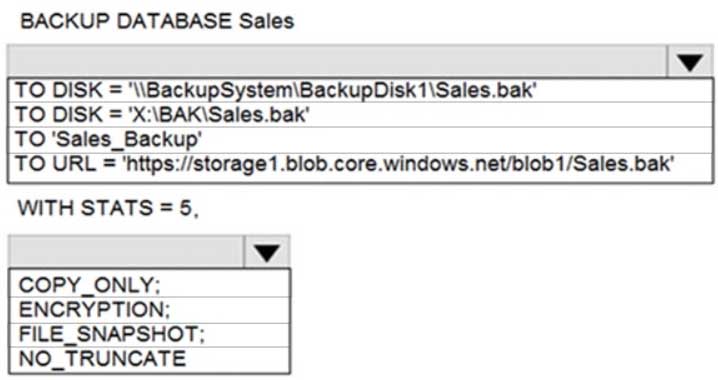
DP-300 Administering Relational Databases on Microsoft Azure Part 09 Q01 096 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 09 Q01 096 Answer Explanation:Box 1: TO URL = ‘https://storage1.blob.core.windows.net/blob1/Sales.bak’
Native database backup in Azure SQL Managed Instance.
You can backup any database using standard BACKUP T-SQL command:BACKUP DATABASE tpcc2501
TO URL = ‘https://myacc.blob.core.windows.net/testcontainer/tpcc2501.bak’
WITH COPY_ONLYBox 2: COPY_ONLY
-
You have the following Transact-SQL query.
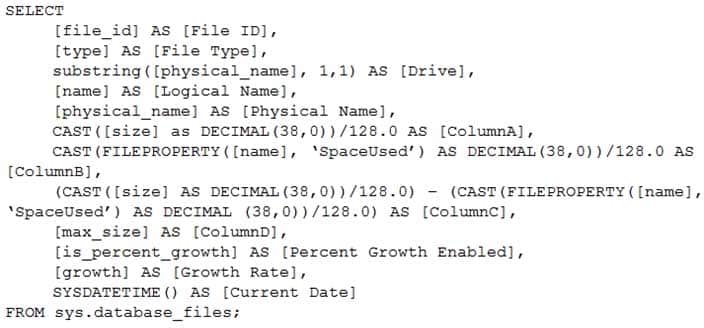
DP-300 Administering Relational Databases on Microsoft Azure Part 09 Q02 097 Which column returned by the query represents the free space in each file?
- ColumnA
- ColumnB
- ColumnC
- ColumnD
Explanation:Example:
Free space for the file in the below query result set will be returned by the FreeSpaceMB column.SELECT DB_NAME() AS DbName,
name AS FileName,
type_desc,
size/128.0 AS CurrentSizeMB,
size/128.0 – CAST(FILEPROPERTY(name, ‘SpaceUsed’) AS INT)/128.0 AS FreeSpaceMB
FROM sys.database_files
WHERE type IN (0,1); -
HOTSPOT
You have an Azure Data Lake Storage Gen2 account named account1 that stores logs as shown in the following table.

DP-300 Administering Relational Databases on Microsoft Azure Part 09 Q03 098 You do not expect that the logs will be accessed during the retention periods.
You need to recommend a solution for account1 that meets the following requirements:
– Automatically deletes the logs at the end of each retention period
– Minimizes storage costsWhat should you include in the recommendation? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 09 Q03 099 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 09 Q03 099 Answer Explanation:Box 1: Store the infrastructure logs in the Cool access tier the application logs in the Archive access tier
Hot – Optimized for storing data that is accessed frequently.
Cool – Optimized for storing data that is infrequently accessed and stored for at least 30 days.
Archive – Optimized for storing data that is rarely accessed and stored for at least 180 days with flexible latency requirements, on the order of hours.Box 2: Azure Blob storage lifecycle management rules
Blob storage lifecycle management offers a rich, rule-based policy that you can use to transition your data to the best access tier and to expire data at the end of its lifecycle. -
HOTSPOT
You have an Azure Data Lake Storage Gen2 container.
Data is ingested into the container, and then transformed by a data integration application. The data is NOT modified after that. Users can read files in the container but cannot modify the files.
You need to design a data archiving solution that meets the following requirements:
– New data is accessed frequently and must be available as quickly as possible.
Data that is older than five years is accessed infrequently but must be available within one second when requested.
– Data that us older than seven years is NOT accessed. After seven years, the data must be persisted at the lowest cost possible.
– Costs must be minimized while maintaining the required availability.How should you manage the data? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-300 Administering Relational Databases on Microsoft Azure Part 09 Q04 100 Question 
DP-300 Administering Relational Databases on Microsoft Azure Part 09 Q04 100 Answer Explanation:Box 1: Move to cool storage
The cool access tier has lower storage costs and higher access costs compared to hot storage. This tier is intended for data that will remain in the cool tier for at least 30 days. Example usage scenarios for the cool access tier include:Short-term backup and disaster recovery
Older data not used frequently but expected to be available immediately when accessed
Large data sets that need to be stored cost effectively, while more data is being gathered for future processingNote: Hot – Optimized for storing data that is accessed frequently.
Cool – Optimized for storing data that is infrequently accessed and stored for at least 30 days.
Archive – Optimized for storing data that is rarely accessed and stored for at least 180 days with flexible latency requirements, on the order of hours.Box 2: Move to archive storage
Example usage scenarios for the archive access tier include:Long-term backup, secondary backup, and archival datasets
Original (raw) data that must be preserved, even after it has been processed into final usable form
Compliance and archival data that needs to be stored for a long time and is hardly ever accessed -
You plan to perform batch processing in Azure Databricks once daily.
Which type of Databricks cluster should you use?
- automated
- interactive
- High Concurrency
Explanation:Azure Databricks makes a distinction between all-purpose clusters and job clusters. You use all-purpose clusters to analyze data collaboratively using interactive notebooks. You use job clusters to run fast and robust automated jobs.
The Azure Databricks job scheduler creates a job cluster when you run a job on a new job cluster and terminates the cluster when the job is complete.
-
HOTSPOT
You have two Azure virtual machines named VM1 and VM2 that run Windows Server 2019. VM1 and VM2 each host a default Microsoft SQL Server 2019 instance. VM1 contains a database named DB1 that is backed up to a file named D:\DB1.bak.
You plan to deploy an Always On availability group that will have the following configurations:
– VM1 will host the primary replica of DB1.
– VM2 will host a secondary replica of DB1.You need to prepare the secondary database on VM2 for the availability group.
How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area.
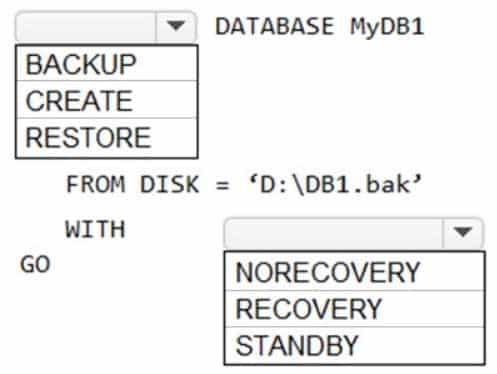
DP-300 Administering Relational Databases on Microsoft Azure Part 09 Q06 101 Question 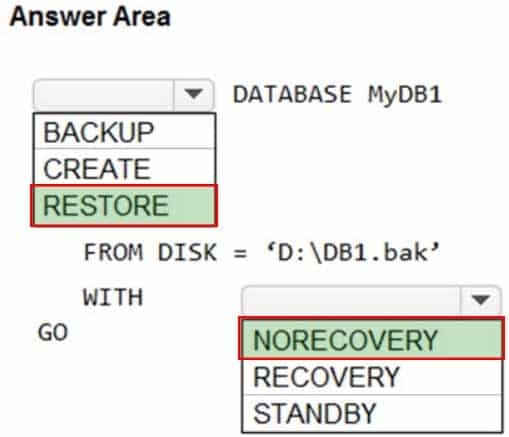
DP-300 Administering Relational Databases on Microsoft Azure Part 09 Q06 101 Answer -
DRAG DROP
You have an Azure Active Directory (Azure AD) tenant named contoso.com that contains a user named [email protected] and an Azure SQL managed instance named SQLMI1.
You need to ensure that [email protected] can create logins in SQLMI1 that map to Azure AD service principals.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
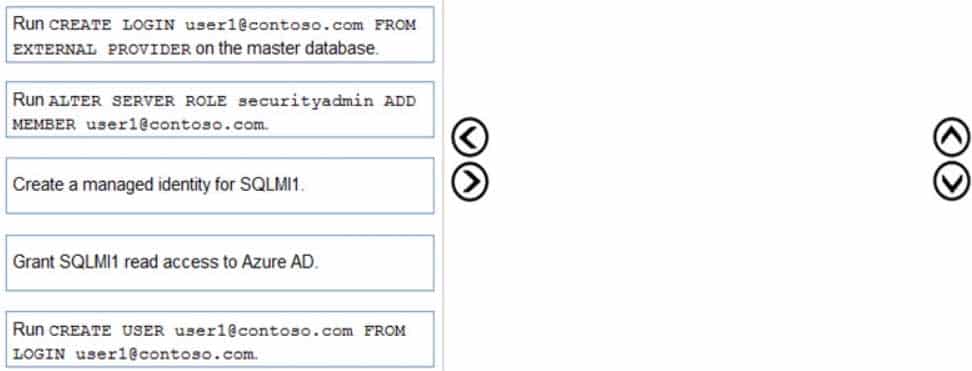
DP-300 Administering Relational Databases on Microsoft Azure Part 09 Q07 102 Question 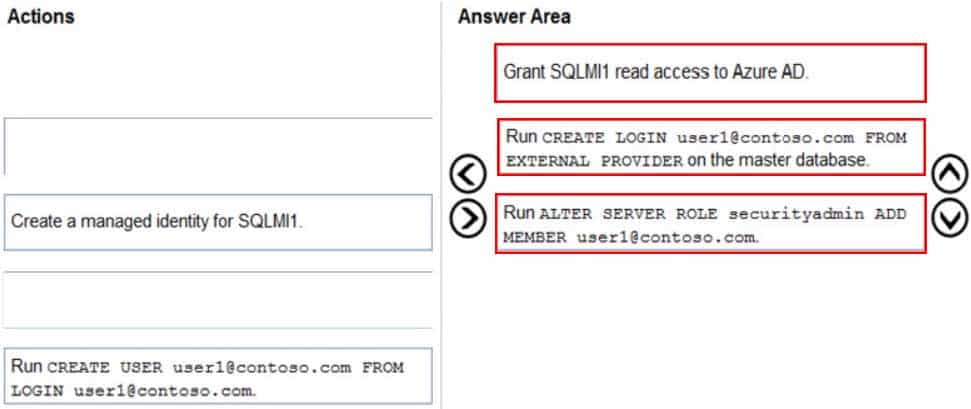
DP-300 Administering Relational Databases on Microsoft Azure Part 09 Q07 102 Answer