DP-900 : Microsoft Azure Data Fundamentals : Part 05
-
Your company needs to design a database that shows how changes in network traffic in one area of a network affect network traffic in other areas of the network.
Which type of data store should you use?
- graph
- key/value
- document
- columnar
Explanation:
Data as it appears in the real world is naturally connected. Traditional data modeling focuses on defining entities separately and computing their relationships at runtime. While this model has its advantages, highly connected data can be challenging to manage under its constraints.
A graph database approach relies on persisting relationships in the storage layer instead, which leads to highly efficient graph retrieval operations. Azure Cosmos DB’s Gremlin API supports the property graph model.
-
HOTSPOT
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

DP-900 Microsoft Azure Data Fundamentals Part 05 Q02 060 Question 
DP-900 Microsoft Azure Data Fundamentals Part 05 Q02 060 Answer Explanation:Box 1: Yes
Azure Databricks can consume data from SQL Databases using JDBC and from SQL Databases using the Apache Spark connector.
The Apache Spark connector for Azure SQL Database and SQL Server enables these databases to act as input data sources and output data sinks for Apache Spark jobs.Box 2: Yes
You can stream data into Azure Databricks using Event Hubs.Box 3: Yes
You can run Spark jobs with data stored in Azure Cosmos DB using the Cosmos DB Spark connector. Cosmos can be used for batch and stream processing, and as a serving layer for low latency access.You can use the connector with Azure Databricks or Azure HDInsight, which provide managed Spark clusters on Azure.
-
DRAG DROP
Match the datastore services to the appropriate descriptions.
To answer, drag the appropriate service from the column on the left to its description on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
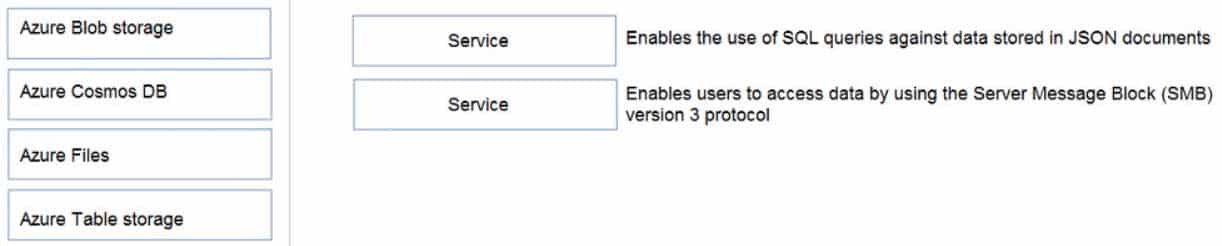
DP-900 Microsoft Azure Data Fundamentals Part 05 Q03 061 Question 
DP-900 Microsoft Azure Data Fundamentals Part 05 Q03 061 Answer Explanation:Box 1: Azure Cosmos DB
In Azure Cosmos DB’s SQL (Core) API, items are stored as JSON. The type system and expressions are restricted to deal only with JSON types.Box 2: Azure Files
Azure Files offers native cloud file sharing services based on the SMB protocol. -
HOTSPOT
To complete the sentence, select the appropriate option in the answer area.

DP-900 Microsoft Azure Data Fundamentals Part 05 Q04 062 Question 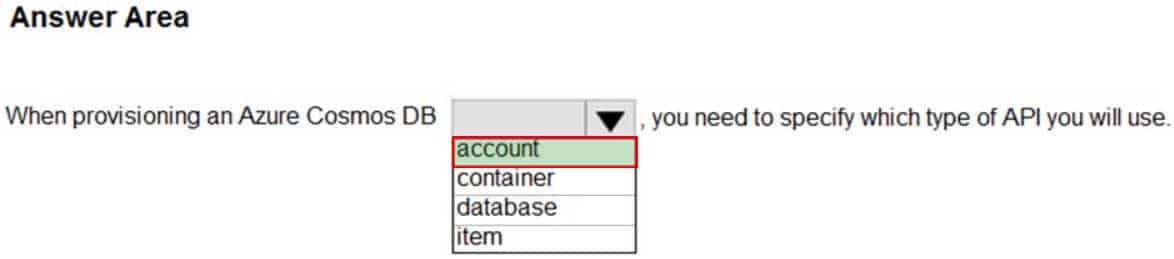
DP-900 Microsoft Azure Data Fundamentals Part 05 Q04 062 Answer -
DRAG DROP
Match the Azure services to the appropriate locations in the architecture.
To answer, drag the appropriate service from the column on the left to its location on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

DP-900 Microsoft Azure Data Fundamentals Part 05 Q05 063 Question 
DP-900 Microsoft Azure Data Fundamentals Part 05 Q05 063 Answer Explanation:Box Ingest: Azure Data Factory
You can build a data ingestion pipeline with Azure Data Factory (ADF).Box Preprocess & model: Azure Synapse Analytics
Use Azure Synapse Analytics to preprocess data and deploy machine learning models. -
DRAG DROP
Match the types of workloads to the appropriate scenarios.
To answer, drag the appropriate workload type from the column on the left to its scenario on the right. Each workload type may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

DP-900 Microsoft Azure Data Fundamentals Part 05 Q06 064 Question 
DP-900 Microsoft Azure Data Fundamentals Part 05 Q06 064 Answer Explanation:Box 1: Batch
The batch processing model requires a set of data that is collected over time while the stream processing model requires data to be fed into an analytics tool, often in micro-batches, and in real-time.
The batch Processing model handles a large batch of data while the Stream processing model handles individual records or micro-batches of few records.
In Batch Processing, it processes over all or most of the data but in Stream Processing, it processes over data on a rolling window or most recent record.Box 2: Batch
Box 3: Streaming
-
HOTSPOT
To complete the sentence, select the appropriate option in the answer area.

DP-900 Microsoft Azure Data Fundamentals Part 05 Q07 065 Question 
DP-900 Microsoft Azure Data Fundamentals Part 05 Q07 065 Answer Explanation:Note: The data warehouse workload encompasses:
– The entire process of loading data into the warehouse
– Performing data warehouse analysis and reporting
– Managing data in the data warehouse
– Exporting data from the data warehouse -
HOTSPOT
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

DP-900 Microsoft Azure Data Fundamentals Part 05 Q08 066 Question 
DP-900 Microsoft Azure Data Fundamentals Part 05 Q08 066 Answer Explanation:Box 1: No
A pipeline is a logical grouping of activities that together perform a task.Box 2: Yes
You can construct pipeline hierarchies with data factory.Box 3: Yes
A pipeline is a logical grouping of activities that together perform a task. -
DRAG DROP
Match the Azure services to the appropriate requirements.
To answer, drag the appropriate service from the column on the left to its requirement on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

DP-900 Microsoft Azure Data Fundamentals Part 05 Q09 067 Question 
DP-900 Microsoft Azure Data Fundamentals Part 05 Q09 067 Answer Explanation:Box 1: Azure Data Factory
Box 2: Azure Data Lake Storage
Azure Data Lake Storage (ADLA) now natively supports Parquet files. ADLA adds a public preview of the native extractor and outputter for the popular Parquet file formatBox 3: Azure Synapse Analytics
Use Azure Synapse Analytics Workspaces. -
HOTSPOT
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

DP-900 Microsoft Azure Data Fundamentals Part 05 Q10 068 Question 
DP-900 Microsoft Azure Data Fundamentals Part 05 Q10 068 Answer Explanation:Box 1: Yes
Compute is separate from storage, which enables you to scale compute independently of the data in your system.Box 2: Yes
You can use the Azure portal to pause and resume the dedicated SQL pool compute resources.
Pausing the data warehouse pauses compute. If your data warehouse was paused for the entire hour, you will not be charged compute during that hour.Box 3: No
Storage is sold in 1 TB allocations. If you grow beyond 1 TB of storage, your storage account will automatically grow to 2 TBs. -
What should you use to build a Microsoft Power BI paginated report?
- Charticulator
- Power BI Desktop
- the Power BI service
- Power BI Report Builder
Explanation:
Power BI Report Builder is the standalone tool for authoring paginated reports for the Power BI service. -
DRAG DROP
Match the Azure services to the appropriate locations in the architecture.
To answer, drag the appropriate service from the column on the left to its location on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
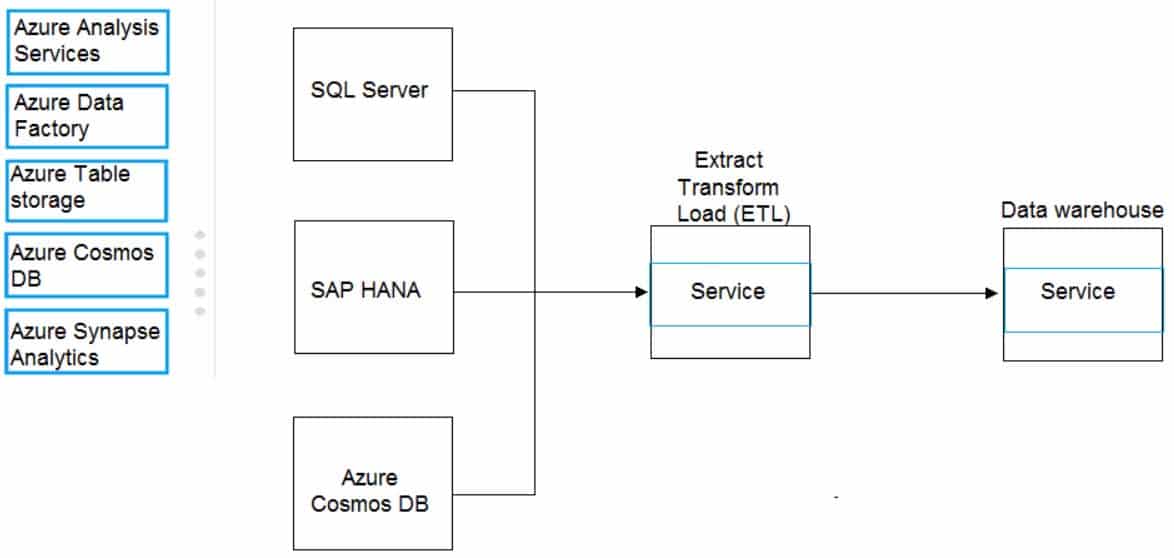
DP-900 Microsoft Azure Data Fundamentals Part 05 Q12 069 Question 
DP-900 Microsoft Azure Data Fundamentals Part 05 Q12 069 Answer Explanation:Box 1: Azure Data factory
Relevant Azure service for the three ETL phases are Azure Data Factory and SQL Server Integration Services (SSIS).Box 2: Azure Synapse Analytics
You can copy and transform data in Azure Synapse Analytics by using Azure Data FactoryNote: Azure Synapse Analytics connector is supported for the following activities:
– Copy activity with supported source/sink matrix table
– Mapping data flow
– Lookup activity
– GetMetadata activity -
HOTSPOT
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

DP-900 Microsoft Azure Data Fundamentals Part 05 Q13 070 Question 
DP-900 Microsoft Azure Data Fundamentals Part 05 Q13 070 Answer -
Which scenario is an example of a streaming workload?
- sending transactions that are older than a month to an archive
- sending transactions daily from point of sale (POS) devices
- sending telemetry data from edge devices
- sending cloud infrastructure metadata every 30 minutes
-
HOTSPOT
To complete the sentence, select the appropriate option in the answer area.

DP-900 Microsoft Azure Data Fundamentals Part 05 Q15 071 Question 
DP-900 Microsoft Azure Data Fundamentals Part 05 Q15 071 Answer -
HOTSPOT
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

DP-900 Microsoft Azure Data Fundamentals Part 05 Q16 072 Question 
DP-900 Microsoft Azure Data Fundamentals Part 05 Q16 072 Answer -
You need to gather real-time telemetry data from a mobile application.
Which type of workload describes this scenario?
- Online Transaction Processing (OLTP)
- batch
- massively parallel processing (MPP)
- streaming
-
You have a SQL pool in Azure Synapse Analytics that is only used actively every night for eight hours.
You need to minimize the cost of the SQL pool during idle times. The solution must ensure that the data remains intact.
What should you do on the SQL pool?
- Scale down the data warehouse units (DWUs).
- Pause the pool.
- Create a user-defined restore point.
- Delete the pool
-
Which Azure Data Factory component initiates the execution of a pipeline?
- a control flow
- a trigger
- a parameter
- an activity
-
Your company has a reporting solution that has paginated reports. The reports query a dimensional model in a data warehouse.
Which type of processing does the reporting solution use?
- stream processing
- batch processing
- Online Analytical Processing (OLAP)
- Online Transaction Processing (OLTP)